by Goetz Graefe, Jim Ewel, and Cesar Galindo-Legaria
Microsoft Corporation
September 1998
Summary: This article presents the goals of SQL Server 7.0. This article also describes query processing in general and discusses specific features of the SQL Server 7.0 query processor. (21 printed pages)
Introduction
What Is a Query Processor?
Types of Query Optimizers
Goals for Microsoft SQL Server 7.0
Query Execution
Query Optimization
Distributed Queries
Working with queries
Conclusion
Microsoft® SQL Server™ version 7.0 is a defining release for Microsoft's database products, building on the solid foundation established by Microsoft SQL Server version 6.5. Customer needs and requirements have driven the significant product innovations in SQL Server 7.0. As the best relational database management system (RDBMS) for the Microsoft Windows® family of operating systems, SQL Server is the right choice for a broad spectrum of corporate customers and independent software vendors (ISVs).
This article describes the innovations and improvements to the SQL Server query processor, that portion of the database server that accepts SQL syntax, determines how to execute that syntax, and executes the chosen plan. SQL Server 7.0 is a source of considerable innovation when compared to other commercially available RDBMS products.
After a brief introduction describing the role of query processor, types of query processors, and the components of query processing, the following topics will be discussed:
A relational database consists of many parts, but at its heart are two major components: the storage engine and the query processor. The storage engine writes data to and reads data from the disk. It manages records, controls concurrency, and maintains log files.
The query processor accepts SQL syntax, determines how to execute that syntax and executes the chosen plan. The user or program interacts with the query processor, and the query processor in turn interacts with the storage engine. Notice that the query processor isolates the user from the details of execution: the user specifies the result, and the query processor determines how this result is obtained.
There are two major phases of query processing: query optimization and query execution.
Query optimization is the process of choosing the fastest execution plan. In the optimization phase, the query processor chooses:
Query execution is the process of executing the plan chosen during query optimization. The query execution component also determines the techniques available to the query optimizer. For example, SQL Server implements both a hash join algorithm and a merge join algorithm, both of which are available to the query optimizer.
The query optimizer is the brain of a relational database system. Although almost any task can be accomplished manually, the query processor enables the relational database to work smartly and efficiently.
As an analogy, imagine two construction firms. Both firms are given the task of building a house. The house must be of a certain size, and it must have a certain number of windows, a certain number of bedrooms and bathrooms, a kitchen, and so on. The first firm begins by planning. They determine the order of the necessary steps, which steps can happen in parallel, which steps are dependent on previous steps, and which workers are best suited to performing various tasks. The second construction firm does no planning. They pick up whatever tools are at hand and start building.
Unless the task is simple (and building a house is generally not simple), the firm that planned ahead is more likely to finish first. For the same reason, a relational database with a sophisticated query optimizer is more likely to complete a query, especially a complex query, faster than a relational database with a simple query optimizer.
The types of tools available also determine how quickly a job can be performed, and in some ways, what kinds of jobs can be tackled. For example, a dump truck might be an appropriate tool for building a house, but it is an inappropriate tool for clearing a garden. In a similar fashion, a relational database must not only have a sophisticated query optimizer, but it must also have the right tools available for query execution and must choose the right tools for the job.
There are two major types of query optimizers in relational databases: a syntax-based query optimizer and a cost-based query optimizer.
A syntax-based query optimizer creates a procedural plan for obtaining the answer to a SQL query, but the particular plan it chooses is dependent on the exact syntax of the query and the order of clauses within the query. A syntax-based query optimizer executes the same plan every time, regardless of whether the number or composition of records in the database changes over time. Unlike a cost-based query optimizer, it does not look at or maintain statistics about the database.
A cost-based query optimizer chooses among alternative plans to answer an SQL query. Selection is based on cost estimates (number of I/O operations, CPU seconds, and so on) for executing a particular plan. It estimates these costs by keeping statistics about the number and composition of records in a table or index. Unlike the syntax-based query optimizer, it is not dependent on the exact syntax of the query or the order of clauses within the query.
Both SQL Server 6.5 and SQL Server 7.0 implement a cost-based query optimizer. SQL Server 7.0 offers considerable improvements in the sophistication of the query optimizer as well as the query execution engine.
Presented here are the overall goals for Microsoft SQL Server 7.0 and specific goals for the query processor:
The product goals include ease of use, scalability and reliability, and comprehensive support for data warehousing.
Customers are looking for solutions to business problems. Many database solutions only add cost and complexity. Microsoft's strategy is to make SQL Server the best database for building, managing, and deploying business applications. This means providing a fast and simple programming model for developers, eliminating database administration for standard operations, and providing sophisticated tools for more complex operations.
Customers make investments in database management systems in the form of the applications written to that database and the training necessary for deployment and management. That investment must be protected. As the business grows, the database must grow to handle more data, transactions, and users. Customers also want to protect investments as they scale database applications down to laptops and out to branch offices.
To meet these needs, Microsoft delivers a single database engine that scales from a mobile laptop computer running the Windows® 95 or Windows® 98 operating system, to terabyte symmetric multiprocessor clusters running Windows NT® Server operating system, Enterprise Edition. All these systems maintain the security and reliability demanded by mission-critical business systems.
Transaction processing systems are a key component of corporate database infrastructures, and SQL Server 7.0 continues the performance and price/performance leadership firmly established with SQL Server 6.0 and SQL Server 6.5. Companies are also investing heavily in increasing comprehension of their data. The goal of SQL Server is to reduce the cost and complexity of data warehousing while making the technology accessible to a wider audience.
SQL Server 7.0 introduces many new features for data warehousing, including parallel query processing; Plato, an integrated online analytical processing (OLAP) server; Data Transformation Services (DTS); Microsoft Repository; Visual Studio® development system; and integrated replication. And the query processor has been improved to handle complex queries and large databases.
Innovation enables SQL Server 7.0 to be a leader in several of the database industry's fastest-growing application categories, including e-commerce, mobile computing, branch automation, line-of-business applications, and data warehousing.
Previous versions of SQL Server had excellent performance in record-to-record and index-to-index navigation, as found in small queries and in online transaction processing (OLTP). The goals for SQL Server 7.0 were to improve the query processor for decision support, large queries, complex queries, data warehousing, and OLAP. These are some of the specific goals.
Previous versions of SQL Server provided limited ways of optimizing queries. For example, SQL Server 6.5 supported only one method for performing a join: nested loops iteration. SQL Server 7.0 adds hash join and merge join, which give the optimizer more options to choose from and which are the algorithms of choice for many large queries.
A second goal was to improve execution of the plan once it was chosen. Faster scans, sort improvements, and large memory support all offer potential performance advantages.
Symmetric multiprocessing (SMP) machines as well as striped disk sets are increasingly common. SQL Server 6.5 implemented parallel I/O and inter-query parallelism (assigning different queries to different processors), but it could not execute different parts of a single query in parallel. SQL Server 7.0 breaks a single query into multiple subtasks and distributes them across multiple processors for parallel execution.
Star schemas and star queries are common in data warehousing applications. A star query joins a large central table, called a fact table, to one or more smaller tables, called dimension tables. SQL Server 7.0 recognizes these queries automatically and makes a cost-based choice among multiple types of star join plans.
Currently, database administrators are in short supply and very expensive. Minimizing involvement for standard operations frees the database administrator for more complex tasks.
SQL Server 7.0 provides tools like Profiler, Query Analyzer, and Index Tuning Wizard to identify, diagnose, and fix problem queries. These tools allow the database administrator to pinpoint the source of problems. In many cases, these tools suggest remedies.
Query execution is the process of executing the plan chosen during query optimization. The objective is to execute the plan quickly, meaning returning the answer to the user (or more often, the program run by the user) in the least amount of time, which is not the same as executing the plan with the least amount of resources (CPU, I/O, and memory). For example, a parallel query will almost always use more resources than a nonparallel query, but it is often desirable because it returns the result to the user faster.
The set of implemented query execution techniques determines the set of choices available to the query optimizer. This article discusses query execution before query optimization so that the techniques that the query optimizer exploits are clearly understood.
The foundation for efficient query processing is efficient data transfer between disks and memory. SQL Server 7.0 incorporates many improvements in disk I/O.
I/O operations (reading data from disk) are among the more expensive operations of a computer system. There are two types of I/O operations: sequential I/O, which reads data in the same order as it is stored on the disk, and random I/O, which reads data in random order, jumping from one location to another on the disk. Random I/O can be more expensive than sequential I/O, particularly when reading large amounts of data.
Microsoft SQL Server 7.0 maintains an on-disk structure that minimizes random I/O and allows rapid scans of large heap tables, which are tables without a clustered index, meaning the data rows are not stored in any particular order. This is an important feature for decision support queries. Such disk-order scans can also be employed for clustered and nonclustered indexes if the index's sort order is not required in subsequent processing steps.
Previous versions of SQL Server used a page chain, where each page had a pointer to the next page holding data for the table. This resulted in random I/O and prevented read-ahead because, until the server read a page, it did not have the location of the next page.
SQL Server 7.0 takes a different approach. An Index Allocation Map (IAM) maps the pages used by a table or index. The IAM is a bitmap, in disk order, of the data pages for a particular table. To read all the pages, the server scans the bitmap, determining which pages need to be read in what order. It can then use sequential I/O to retrieve the pages and issue read-aheads.
If the server can scan an index rather than reading the table, it will attempt to do so. This is useful if the index is a covering index, that is, an index that has all the fields necessary to satisfy the query. The server may satisfy a query by reading the B-tree index in disk order rather than in sort order. This results in sequential I/O and faster performance.
In SQL Server 7.0, all database pages are 8 KB, increased from 2 KB in previous releases. SQL Server now reads data in 64 KB extents, increased from 16 KB. Both of these changes increase performance by allowing the server to read larger amounts of data in a single I/O request. This is particularly important for very large databases (VLDB) and for decision support queries, where a single request can process large numbers of rows.
SQL Server 7.0 takes increased advantage of striped disk sets by reading multiple extents ahead of the actual query processor request. This results in faster scans of heap tables and B-tree indexes.
Disk-order scans speed up scans of large amounts of data. SQL Server 7.0 also speeds up fetching data using a nonclustered index.
When searching for data using a nonclustered index, the index is searched for a particular value. When that value is found, the index points to the disk address. The traditional approach would be to immediately issue an I/O for that row, given the disk address. The result is one synchronous I/O per row and, at most, one disk at a time working to evaluate the query. This doesn't take advantage of striped disk sets.
SQL Server 7.0 takes a different approach. It continues looking for more record pointers in the nonclustered index. When it has collected a number of them, it provides the storage engine with prefetch hints. These hints tell the storage engine that the query processor will need these particular records soon. The storage engine can now issue several I/Os simultaneously, taking advantage of striped disk sets to execute multiple operations simultaneously.
Many different areas of the query processor rely on the sort algorithms: merge joins, index creations, stream aggregations, and so on. Sort performance is dramatically improved in SQL Server 7.0.
Many internal improvements make each sort operation faster: simpler comparisons, larger I/O operations, asynchronous I/O, and large memory. In addition, SQL Server 7.0 pipelines data between a sort operation and the query operations on its input and output sides, thus avoiding query plan phases, which were traditionally used in SQL Server and which require writing and scanning intermediate work tables.
SQL Server 6.5 used nested loops iteration, which is excellent for row-to-row navigation, such as moving from an order record to three or four order line items. However, it is not efficient for joins of large numbers of records, such as typical data warehouse queries.
SQL Server 7.0 introduces three new techniques: merge joins, hash joins, and hash teams, the last of which is a significant innovation not available in any other relational database.
A merge join simultaneously passes over two sorted inputs to perform inner joins, outer joins, semi-joins, intersections, and union logical operations. A merge join exploits sorted scans of B-tree indexes and is generally the method of choice if the join fields are indexed and if the columns represented in the index cover the query.
A hash join hashes input values, based on a repeatable randomizing function, and compares values in the hash table for matches. For inputs smaller than the available memory, the hash table remains in memory; for larger inputs, overflow files on disk are employed. Hashing is generally the method of choice for large, nonindexed tables, in particular for intermediate results.
The hashing operation can be used to process GROUP BY clauses, distincts, intersections, unions, differences, inner joins, outer joins, and semi-joins. SQL Server 7.0 implements all the well-known hashing techniques including cache-optimized in-memory hashing, large memory, recursive partitioning, hybrid hashing, bit vector filtering, and role reversal.
An innovation in SQL Server 7.0 is the hash team. In simple terms, many queries consist of multiple execution phases; where possible, the query optimizer should take advantage of similar operations across multiple phases. For example, you want to know how many order line items have been entered for each part number and each supplier.
SELECT l_partkey, count (*)
FROM lineitem, part, partsupp
WHERE l_partkey = p_partkey and p_partkey = ps_partkey
GROUP BY l_partkey
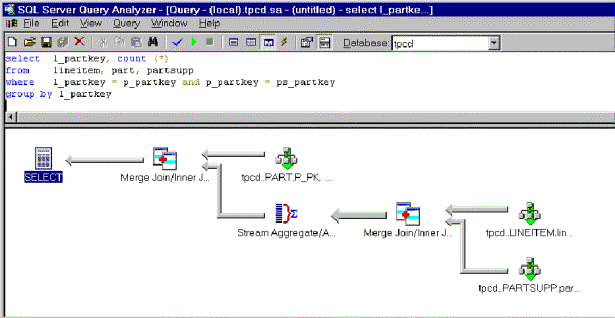
As a result, the query processor generates an execution plan as depicted in figure 1:
Figure 1. Hash team query processor execution plan
This query plan performs a merge inner join between the lineitem table and the partsupp table. It calculates the count (stream aggregate), and then joins the result with the part table. This query never requires a sort operation. It begins by retrieving records in sorted order from the lineitem and partsupp tables using sorted scans over an index. This provides a sorted input into the merge join, which provides sorted input into the aggregation, which in turn provides sorted input into the final merge join.
Interesting ordering, the idea of avoiding sort operations by keeping track of the ordering of intermediate results that move from operator to operator, are implemented by all major query processors on the market today. But SQL Server 7.0 goes a step further and applies the same concept to hash joins. Consider the same query, but assume that the crucial index on lineitems has been dropped, such that the previous plan would have to be augmented with an expensive sort operation on the large lineitems table. This is depicted in figure 2 below:
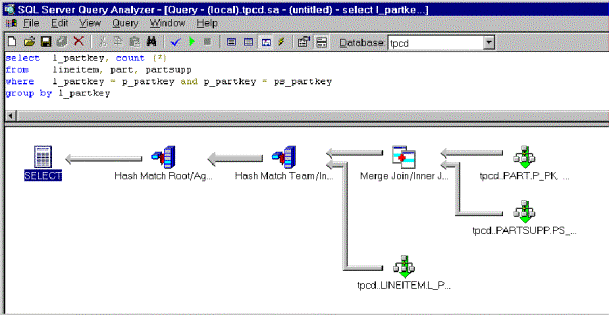
Figure 2. Query plan employing a hash join rather than a merge join
This query plan (depicted above in figure 2) employs a hash join instead of a merge join; one of the merge joins is not affected by the dropped index and therefore still very fast. The two hash operations are marked specially as the root and a member of a team. As data moves from the hash join to the grouping operation, work to partition rows in the hash join is exploited in the grouping operation. This eliminates overflow files for one of the inputs of the grouping operation, and thus reduces I/O costs for the query. The benefit is faster processing for complex queries.
Microsoft SQL Server 6.5 selected the one best index for each table, even when a query had multiple predicates. SQL Server 7.0 takes advantage of multiple indexes, selecting small subsets of data based on each index, and then performing an intersection of the two subsets (that is, returning only those rows that meet all the criteria).
For example, you want to count orders for certain ranges of customers and order dates:
SELECT count (*)
FROM orders
WHERE o_orderdate between '9/15/1992' and '10/15/1992' and
o_custkey between 100 and 200
SQL Server 7.0 can exploit indexes on both o_custkey and o_orderdate, and then employs a join algorithm to obtain the index intersection between the two subsets. This execution plan (depicted in figure 3) exploits two indexes, both on the orders table.
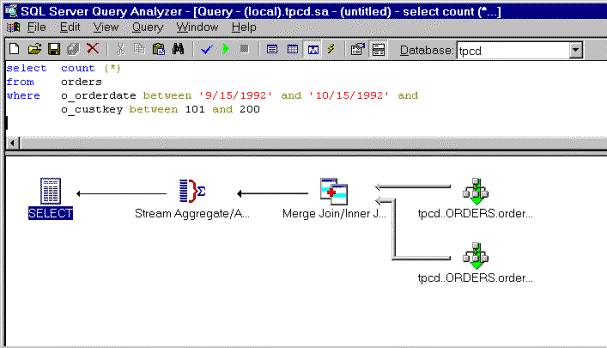
Figure 3. Index intersection between o_custkey and o_orderdate
A variation of index intersections is index joins. When using any index, if all the columns required for a given query are available in the index itself, it is not necessary to fetch the full row. This is called a covering index because the index covers or contains all the columns needed for the query.
The covering index is a common and well-understood technique. SQL Server 7.0 takes it a step further by applying it to the index intersection (as depicted in figure 4 below). If no single index can cover a query, but multiple indexes together can cover the query, SQL Server will consider joining these indexes. Which of these alternatives is chosen is based on the cost prediction of the query optimizer.
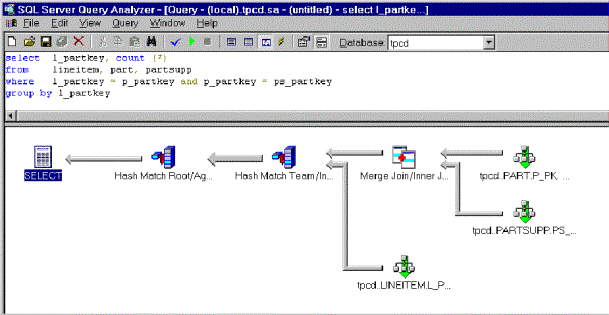
Figure 4. A covering index applied to an index intersection
Microsoft SQL Server 7.0 introduces intra-query parallelism, the ability to break a single query into multiple subtasks and distribute them across multiple processors in a SMP machine for execution.
The architecture uses a generic parallelization operation that creates multiple, parallel threads on the fly. Each operation (scan, sort, or join) does not know about parallelism but can be executed in parallel simply because it is combined with the parallelization operation, resulting in "parallel everything." The exception to parallel everything is parallel updates, which Microsoft will add in a future release of SQL Server. All other operations (scans, sorts, joins, GROUP BYs) are done in parallel.
SQL Server detects that it is running on an SMP machine and determines the best degree of parallelism for each instance of a parallel query execution. By examining the current system workload and configuration, SQL Server determines the optimal number of threads and spreads the parallel query execution across those threads. Once a query starts executing, it uses the same number of threads until completion. SQL Server decides on the optimal number of threads each time a parallel query execution plan is retrieved from the procedure cache. As a result, one execution of a query can use a single thread, and another execution of the same query (at a different time) can use two or more threads.
The automatic decision whether to employ parallel query processing in SQL Server 7.0 depends on the answers to these questions:
In addition to parallel queries, Microsoft SQL Server 7.0 supports parallel load using multiple clients, parallel backup, and parallel restore.
There are many aspects to the innovative and state-of-the-art query optimizer included in Microsoft SQL Server 7.0.
The SQL Server 7.0 query optimizer proceeds in multiple phases. First, it looks for a simple but reasonable plan of execution that satisfies the query. If that plan takes less time than a cost threshold value (for example, a fraction of a second), the query optimizer doesn't bother looking for more efficient plans. This prevents over-optimization, where the query optimizer uses more resources to determine the best plan than is required to execute the plan.
If the first plan chosen takes more time than the cost threshold value, then the optimizer will continue to look at other plans, always choosing the least-cost plan. The use of multiple phases provides a good tradeoff between the time it takes to choose the most efficient plan and the time it takes to optimize for that plan.
Most query processors allow you to precompile and store an execution plan. An example is compiling a stored procedure. Precompiling is more efficient because it allows reuse of the execution plan. The execution plan allows the user to submit variables as parameters to the plan. A new Open Database Connectivity (ODBC) interface for preparing requests for repeated execution also exploits this efficiency.
Many commercial applications and all ad hoc queries, however, do not use stored procedures. Instead, they use dynamic SQL. SQL Server 7.0 implements a new feature, called automatic parameters, that caches a plan created for dynamic SQL, turning constants into parameters. The result is less compilation effort, providing many of the efficiencies of stored procedures, even for those applications that don't employ stored procedures.
SQL Server 7.0 also introduces full support for parameterized queries, where the application identifies the parameters. This is typical with ODBC, OLE DB, and prepare/execute.
From early math classes, you may remember the transitive property of numbers. If A = B and B = C, then, by the transitive property, A = C. This property can be applied to queries:
SELECT *
FROM part, partsupp, lineitem
WHERE ps_partkey = l_partkey and l_partkey = p_partkey and
ps_availqty > l_quantity and ps_supplycost > p_retailprice
Because both ps_partkey and p_partkey are equal to l_partkey, then ps_partkey must be equal to p_partkey. The query processor takes advantage of this by deriving the third join predicate (ps_partkey equal to p_partkey). For example, in this query (depicted in figure 5 below), the query processor begins by joining the partkey in the parts table to the partkey in the partsupp table, even though this particular join predicate is never specified in the query. It can do so because of transitive predicates.
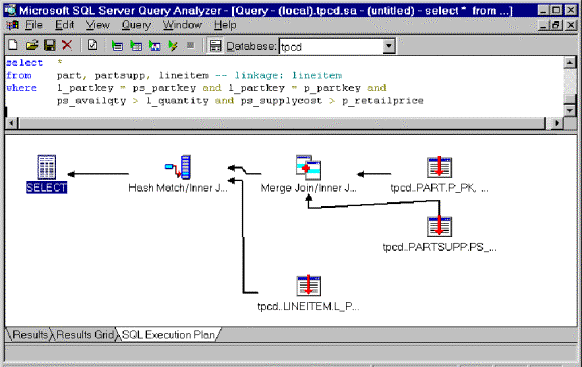
Figure 5. Deriving third join predicates
Correlated subqueries present special challenges for any SQL query processor. SQL Server applies some specific techniques to correlated subqueries, and it flattens them to semi-joins if possible. The advantage of flattening is that all the join algorithms can be applied. For large queries, this means that the query optimizer can consider hash joins or merge joins, rather than using the less efficient nested iteration join.
The SQL standards require processing a query in a particular order:
Any plan that produces the same result is also correct. Therefore, in some queries, you can evaluate the GROUP BY clause earlier, before one or more join operations required for the WHERE clause, thus reducing the join input and the join cost. This is called a GROUP BY clause. Here is an example:
SELECT c_name, c_custkey, count (*), sum (l_tax)
FROM customer, orders, lineitem
WHERE c_custkey = o_custkey and o_orderkey = l_orderkey and
o_orderdate between '9/1/1994' and '12/31/1994'
GROUP BY c_name, c_custkey
Looking at the GROUP BY clause, the query processor determines that the primary key c_custkey determines c_name, so there is no need to group on c_name in addition to c_custkey. The query optimizer then determines that grouping on c_custkey and o_custkey will produce the same result. Since the orders table has a customer key (o_custkey), the query processor can group by customer key as soon as it has the records for the orders table and before it joins to the customer table. This becomes evident in the following execution plan, depicted in figure 6:
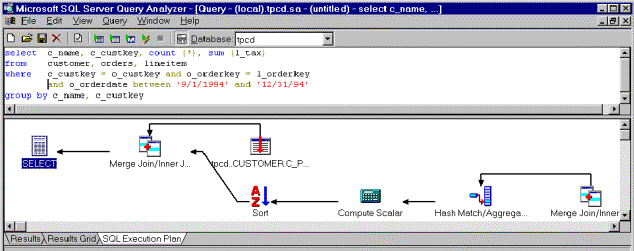
Figure 6. Employing the GROUP BY clause in the query
The query processor first uses a merge join of the orders table (within the specified date range) and the lineitem table to get all order line items. The second step is a hash aggregation, that is, the grouping operation. In this step, SQL Server aggregates the order line items at the customer key level, counting them and calculating a sum of l_tax. SQL Server then sorts the output of the hash join and joins to the customer table to produce the requested result. The advantage of this query plan is that the input into the final join is substantially reduced due to the earlier grouping operation.
Microsoft SQL Server 7.0 supports partitioning using filegroups. This architecture takes advantage of many of the benefits of partitioning, particularly the ability to administer at a lower granularity than an entire database. The architecture will support on-disk partitioning in a later release of SQL Server. For large decision support queries, however, SQL Server 7.0 implements partitioning views, which allow the database administrator to create multiple tables with constraints, essentially one table for each partition. The tables are then logically reunited through a partitioning view. An example will demonstrate this:
CREATE table Sales96Q1 … constraint "Month between 1 and 3"
CREATE table Sales96Q2 … constraint "Month between 4 and 6"
…
CREATE view Sales96 as
SELECT * from Sales96Q1 union all
SELECT * from Sales96Q2 union all
…
This data definition language (DDL) creates four tables, one for each quarter of sales, each with an appropriate constraint. The DDL then creates a view that reunites all four tables. Programmers must be aware of the partitioning for updates, but for decision support queries the partitioning is transparent. When the query processor receives a query against the view Sales96, it automatically identifies and removes tables that do not fall within the constraints of the query.
SELECT *
FROM Sales96 -- remember, this view has four tables
WHERE s_date between '6/21/1996' and '9/21/1996'
If you issue this query, the query processor will generate a plan that touches only two of the tables in the view (Sales96Q2 and Sales96Q3), because the WHERE clause contradicts the constraints on the other two tables, which therefore are irrelevant for this query. Moreover, different access paths may be used for the individual quarters, for example, an index scan for the few days in Q2 and a table scan for Q3. This is a useful method of improving the performance of queries that tend to select subsets of large tables on a well-known column. Time and location are typical examples.
SQL Server detects all empty results when a constraint contradicts the selection criteria. Even in cases where the administrator has not declared a view, if the selection criteria are at odds with the constraint, the optimizer recognizes this and generates an appropriate plan.
Databases designed for decision support, particularly data warehouses and data marts, often have very different table structures than OLTP databases. A common approach is to implement a star schema, a type of database schema designed to allow a user to intuitively navigate information in the database, as well as to provide better performance for large, ad hoc queries.
A star schema begins with the observation that information can be classified into facts, the numeric data that is the core of what is being analyzed, and dimensions, the attributes of facts. Examples of facts include sales, units, budgets, and forecasts. Examples of dimensions include geography, time, product, and sales channel. Users often express their queries by saying "I want to look at these facts by these dimensions," or "I want to look at sales and units sold by quarter."
A star schema (depicted in figure 7 below) takes advantage of this observation by organizing data into a central fact table and surrounding dimension tables.
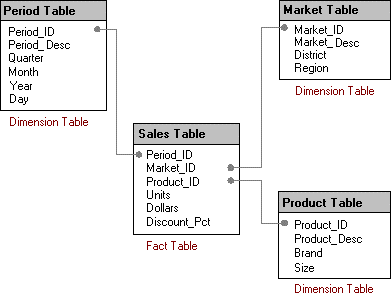
Figure 7. Star schema
Microsoft SQL Server 7.0 has several techniques for optimizing queries against star schemas. The query processor automatically recognizes these queries and applies any and all of the techniques discussed here, as well as combinations of these techniques. It is important to understand that the choice of which technique to apply is entirely cost-based; no hints are required to force these optimizations.
The tables in a star schema do not contain equal numbers of records. Typically, the fact table has many more records. This difference becomes important in many of the query optimization techniques.
A straightforward execution strategy is to read the entire fact table and join it in turn to each of the dimension tables. If no filter conditions are specified in the query, this can be a reasonable strategy. However, when filter conditions are present, the star query optimizations avoid having to read the entire fact table by taking full advantage of indexes.
Since dimension tables typically have fewer records than the fact table, it can make sense to compute the Cartesian product and use the result to look up fact table rows in a multicolumn index.
This technique is easiest to understand by looking at an example. Referring to the earlier example, assume that the fact table, or sales table, has 10 million rows. The period table has 20 rows, the market table has 5 rows, and the product table has 200 rows. A user uses a front-end tool to generate this query:
SELECT sales.market_id, period.period_id, sum(units), sum(dollars)
FROM sales, period, market
WHERE period.period_id = sales.period_id and
sales.market_id = market.market_id and
period.period_Desc in ('Period2','Period3','Period4','Period5')
and market.market_Desc in ('Market1','Market2')
GROUP BY sales.market_id, period.period_id
A simple approach is to join the period table to the sales table. Assuming an even distribution of data, the input would be 10 million rows, the output would be 4/20 (4 periods out of a possible 20) or 2 million rows. This can be done using a hash join or merge join, and involves reading the entire 10 million rows in the fact table or retrieving 2 million rows through index lookups, whichever costs less. This partial result is then joined to the reduced market table to produce 800K rows of output, which are finally aggregated.
If there is a multicolumn index on the fact table, for example, on the period_id or market_id columns, then the Cartesian product strategy can be used. Since there are four rows selected from the period table and two rows from the market table, the Cartesian product is eight rows. These eight combinations of values are used to look up the resulting 800K rows of output. Multicolumn indexes used this way are sometimes called star indexes.
If the joins to the fact table occur on fields other than those contained in a composite index, the query optimizer can use other indexes and reduce the number of rows read from the fact table by performing an intersection of the qualifying rows from joins to each dimension table.
For example, if the selection is on period_id and product_id, the query optimizer cannot use the composite index because the two fields of interest, period_id and product_id, are not a leading subset of the index. However, if there are separate single-column indexes on period_id and product_id, the query optimizer may choose a join between the period table and the sales table (retrieving 2 million index entries) and, separately, a join between the product table and the sales table (retrieving 4 million index entries). In both cases, it will do the join using an index; thus, these two preliminary joins compute sets of record IDs for the sales table but not full rows of the sales table. Before retrieving the actual rows in the sales table (remember, this is the most expensive process), an intersection of the two sets is computed to determine the truly qualifying rows. Only rows that satisfy both joins end up in this intermediate result of 800K rows and, in the end, only these rows are actually read from the sales table.
Occasionally, semi-join reduction can be combined with Cartesian products and composite indexes. For example, if you select from three dimension tables, where two of the three tables are the initial fields of a composite index but the third dimension has a separate index, then the query optimizer may use Cartesian products to satisfy the first two joins, use semi-joins to satisfy the third join, and then combine the results.
Several factors influence the effectiveness of these techniques. These factors include the size of the indexes to be used, compared to the base table, and whether or not the set of indexes used covers all the columns required by the query, obviating the need to look up rows in the base table. These factors are taken into account by the query optimizer, which will choose the least-expensive plan.
If that plan is more expense than the cost threshold for parallelism, all required operations, including scans, joins, intersection, and row fetching, can be executed by multiple threads in parallel.
If a row in a table is updated, any indexes on that table also must be updated. For small updates, such as OLTP operations, it is appropriate to update the indexes row-by-row as you update each row of the base table.
For large updates, such as a data warehouse refresh, row-by-row updates can be inefficient, resulting in a high volume of random I/O to the index records. A better approach is to delay updating the indexes until all the base tables are updated, then presort the changes per index and simultaneously merge all the changes into the index. This assures that each index leaf page is touched once at most and that SQL Server traverses each B-tree index sequentially.
The query optimizer takes this approach if it is the least-expensive approach. The benefit is that large data warehouse refreshes can be accomplished more efficiently.
The query optimizer also plans the join operations required to enforce referential integrity constraints, making a cost-based choice between (index) nested loops join, merge join, and hash join.
Microsoft SQL Server 7.0, in addition to storing and searching data locally, can also be used as a gateway to many other data stores, both relational databases and non-relational data sources.
SQL Server 7.0 performs distributed queries, that is, queries that involve data from two or more servers. It supports retrievals, updates, and cursors across servers, and ensures transaction semantics across nodes using the Microsoft Distributed Transaction Coordinator (MS DTC). It also maintains security across servers.
If any remote servers support indexes or SQL queries, then the SQL Server query optimizer determines the largest possible query that can be sent to each remote server. In other words, the query optimizer assigns the maximum possible data reduction to each remote server. For example, if a remote query is issued against a 1-million row table, with a WHERE clause or an aggregation that returns only 10 records, the 1 million rows are processed at the remote server, and only 10 records are sent across the network. This reduces network traffic and overall query time. Typical operations that are pushed toward the data source are selections, joins, and sorts.
Distributed queries may be heterogeneous, supporting any OLE DB or ODBC data source. The SQL Server 7.0 compact disc includes OLE DB drivers for Oracle 7.x, Oracle 8.x, Microsoft Excel, Microsoft Access, dBASE, Paradox, and Microsoft Visual FoxPro® database development system, as well as an OBDC gateway for other relational databases. OLE DB Providers for other server databases (IBM DB2, SYBASE, and Informix) are available from third parties.
If a remote server supports non-SQL standard syntax, or if the remote data source supports a query language other than SQL, the OPENQUERY operator is provided to pass through the query syntax unchanged.
In addition to improved query processing capabilities in the server, Microsoft SQL Server 7.0 also offers improved tools to work with database queries.
SQL Server 7.0 provides Query Analyzer, an interactive, graphical tool that enables a database administrator or developer to write queries, execute multiple queries simultaneously, view results, analyze the plan of a query, and receive assistance to improve the performance of a query. The SHOWPLAN option graphically displays the data retrieval methods chosen by the SQL Server query optimizer. This is very useful for understanding the performance characteristics of a query. In addition, query analyzer provides suggestions for additional indexes and statistics on nonindexed columns that would improve the query optimizer's ability to process a query efficiently. In particular, the query analyzer shows what statistics are missing, thus forcing the query optimizer to guess about predicate selectivity, and permits the creation of those statistics with a few clicks.
Query cost refers to the estimated elapsed time, in seconds, required to execute a query on a specific hardware configuration. On other hardware configurations, there will be a strong correlation between cost units and elapsed time, but cost units do not equal seconds. The query governor lets you specify an upper cost limit for a query; a query that exceeds this limit is not run.
Because it is based on estimated query cost rather than actual elapsed time, the query governor does not have any run-time overhead. It also stops long-running queries before they start, rather than running them until they reach a predefined limit.
The Microsoft SQL Server Profiler is a graphical tool that allows system administrators to monitor engine events. Examples of engine events include:
Data about each event can be captured and saved to a file or a SQL Server table for later analysis. Event data can be filtered so that only a relevant subset is collected. For example, only the events that affect a specific database, or those for a particular user, are collected; all others are ignored. Alternatively, data could be collected about only those queries that take longer than 30 seconds to execute.
The SQL Server Profiler allows captured event data to be replayed against SQL Server, thereby effectively re-executing the saved events as they originally occurred. You can troubleshoot problems in SQL Server by capturing all the events that lead up to a problem, and then, by replaying the events on a test system, replicate and isolate the problem.
The Microsoft SQL Server Index Tuning Wizard is a new and powerful tool that analyzes your workload and recommends optimal index configuration for your database.
Features of the Index Tuning Wizard include:
The Index Tuning Wizard creates SQL statements that can be used to drop ineffective indexes or to create new, more effective indexes and statistics on nonindexed columns. The SQL statements may be saved for manual execution as necessary.
When you create an index, Microsoft SQL Server automatically stores statistical information regarding the distribution of values in the indexed columns. SQL Server 7.0 also supports statistics on nonindexed columns. The query optimizer uses these statistics to estimate the size of intermediate query results as well as the cost of using the index for a query.
If the query optimizer determines that important statistics are missing to optimize a query, it automatically creates the required statistics. Such automatically created statistics are saved in the database and can be used to optimize other queries; however, they also vanish after a while if not required again. Moreover, SQL Server automatically updates statistical information as the data in a table changes and these statistics become out of date.
Statistics are created and refreshed very efficiently by sampling. The sampling is random across data pages and taken from a table or nonclustered index for the smallest index containing the columns needed by the statistics. The volume of data in the table and the amount of changing data determine the frequency at which the statistical information is updated. For example, the statistics for a table containing 10,000 rows may need updating when 1,000 rows have changed because 1,000 is a significant percentage of the table. However, for a table containing 10 million rows, 1,000 changes are less significant.
This article has described the innovations and improvements in the Microsoft SQL Server 7.0 query processor. The SQL Server 7.0 query optimizer uses many sophisticated techniques to determine an optimal execution plan and has many new options for executing these plans quickly and efficiently. While some of these query features are available in other commercially available database servers, none are as easy to use or as well integrated with the Microsoft Windows family of operating systems.
---------------------------------------------
The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication.
This document is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS DOCUMENT.
©1998 Microsoft Corporation. All rights reserved.
Microsoft, BackOffice, the BackOffice logo, Visual FoxPro, Windows, Windows NT, and Visual Studio 97 are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries.
Other trademarks and tradenames mentioned herein are the property of their respective owners.
Microsoft Part Number: 098-80763