Microsoft Corporation
June 1999
Summary: Describes the changes made for the Microsoft® Windows® CE operating system, version 3.0, to enhance its real-time performance characteristics. Discusses the tools available to test the real-time performance, and provides real-time performance test results. (18 printed pages)
Introduction
Changes to the Kernel
Real-Time Measurement Tools
For More Information
Real-time performance is essential for the time-critical responses required in such high-performance embedded applications as telecommunications switching equipment, medical monitoring equipment, and space navigation and guidance. Such applications must deliver their responses within specified time parameters in real time.
What is real-time performance? For Windows CE, Microsoft defines real-time performance as:
It is important to distinguish between a real-time system and a real-time operating system (RTOS). The real-time system consists of all system elements—the hardware, operating system, and applications—that are needed to meet the system requirements. The RTOS is just one element of the complete real-time system and must provide sufficient functionality to enable the overall real-time system to meet its requirements.
Although previous versions of Windows CE offered some RTOS capabilities, changes made to the kernel of Windows CE 3.0 have greatly enhanced real-time performance. This paper describes the following changes made for Windows CE 3.0:
In addition, this paper describes tools used to test the real-time performance of the kernel and provides real-time performance test results.
The kernel is the inner core of the Windows CE operating system. The kernel is responsible for scheduling and synchronizing threads, processing exceptions and interrupts, loading applications, and managing virtual memory. In Windows CE 3.0, the kernel has undergone many changes to increase performance and reduce latencies, including:
This section describes more changes made to the kernel to enhance the real-time performance of Windows CE 3.0.
Assigning priority levels to threads is one way to manage the speed of execution. The kernel's scheduler runs a thread with a higher-priority level first and runs threads with the same priority in a round-robin fashion.
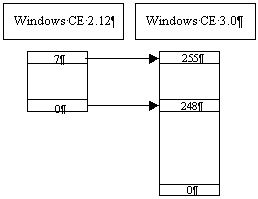
Windows CE 3.0 increases the number of priority levels available for threads from 8 to 256, with 0 being the highest priority and 255 the lowest. Priority levels 0 to 7 of the previous version of Windows CE correspond to levels 248 to 255 in Windows CE 3.0, as shown in the following figure:
To assign these new priorities, Windows CE 3.0 introduces two new functions: CeSetThreadPriority and CeGetThreadPriority. The new functions look exactly like SetThreadPriority and GetThreadPriority, except that the new functions take a number in the range of 0 to 255.
Windows CE 3.0 has one-millisecond accuracy in the timer and Sleep function calls, and applications can set a quantum for each thread.
The timer (or system tick) is the rate at which a timer interrupt is generated and serviced by the operating system. Previously, the timer was also the thread quantum, the maximum amount of time that a thread could run in the system without being preempted. In Windows CE 3.0, the timer is not directly related to the thread quantum.
Previously, the OEM set the timer and the quantum as a constant in the OEM Adaptation Layer (OAL), and it was usually 25 milliseconds. When the timer fired, the kernel scheduled a new thread if one was ready. In Windows CE 3.0, the timer is always set to one millisecond and the quantum can be set for each thread.
Changing the timer from OEM-defined to one millisecond lets an application do a Sleep (1) and expect to receive approximately one-millisecond accuracy. Of course, this is dependent on the priority of the thread, the priority of other threads, and whether ISRs are running. Previously, a Sleep (1) returned on a system tick, which meant a Sleep (1) was really a Sleep (25) if the timer was set to 25 milliseconds.
The kernel has a few new variables that determine whether a reschedule is required on the system tick. A fully implemented system tick ISR can prevent the kernel from rescheduling by returning SYSINTR_NOP instead of SYSINTR_RESCHED, when appropriate. Nk.lib exports the following variables that are used in the Timer ISR:
In the Timer ISR, additional logic optimizes the scheduler and prevents the kernel from doing unnecessary work. The return code logic looks like this:
if (ticksleft || (dwSleepMin && (DiffMSec >= dwSleepMin)) ||
(dwPreempt && (DiffMSec >= dwPreempt)))
return SYSINTR_RESCHED;
return SYSINTR_NOP;
The OEM implements the OEMIdle function, which is called by the kernel when there are no threads to schedule. In previous releases, the timer tick forced the operating system out of an Idle state and back into the kernel to determine if threads were ready to be scheduled. If no threads were ready, the kernel again called OEMIdle. This operation caused the kernel to be activated every 25 milliseconds—or other quantum specified by the OEM—to determine that there were still no threads to schedule. On a battery-powered device, such an operation uses valuable battery life.
To allow low-power consumption with a higher tick rate in Windows CE 3.0, the OEMIdle function can put the CPU in standby mode for longer than one millisecond. The OEM reprograms the timer to wake up on the first timeout available—dwSleepMin - DiffMSec—where DiffMSec is the current millisecond value since the last interval time was retrieved from the TimerCallBack function.
The hardware timer is likely to have a maximum timeout that is less than MAX_DWORD milliseconds, so the timer may be programmed for its maximum wait time. In all cases, when the system returns from idle, the OEMIdle function must update CurMSec and DiffMSec with the actual number of milliseconds that have elapsed. CurMSec is the current value for the interval time, the number of milliseconds since startup.
In Windows CE 3.0, the thread quantum is flexible enough to enable an application to set the quantum on a thread-by-thread basis. This lets a developer adapt the scheduler to the current needs of the application. To adjust the time quantum, two new functions have been added: CeGetThreadQuantum and CeSetThreadQuantum. This change enables an application to set the quantum of a thread based on the amount of time needed by the thread to complete a task. By setting the thread quantum of any thread to zero, a round-robin scheduling algorithm can change to a run-to-completion algorithm. Only a higher-priority thread or a hardware interrupt can preempt a thread that is set to run-to-completion.
The default quantum is 100 milliseconds, but an OEM can override the default for the system by setting the kernel variable dwDefaultThreadQuantum to any value greater than zero during the OEM initialization phase.
To help improve response time, Windows CE 3.0 has a different approach to priority inversion, which occurs when a low-priority thread owns a kernel object that a higher-priority thread requires. Windows CE deals with priority inversion using priority inheritance, where a thread that is blocked holding a kernel object needed by a higher-priority thread inherits the higher priority. Priority inversion enables the lower-priority thread to run and free the resource for use by the higher-priority thread. Previously, the kernel handled an entire inversion chain. In Windows CE 3.0, the kernel guarantees only to handle priority inversion to a depth of one level.
There are two basic cases of priority inversion. The first is a simple case where the processing of priority inversion has not changed from Windows CE 2.12 to Windows CE 3.0. This case can be seen when, for example, you have three threads all in a runable state. Thread A is at priority 1 and threads B and C are at a lower priority. If thread A is running and becomes blocked because thread B is holding a kernel object that thread A needs, then thread B's priority is boosted to A's priority level to allow thread B to run. If thread B then becomes blocked because thread C is holding a kernel object that thread B needs, thread C's priority is boosted to A's priority level to allow thread C to also run.
In a more interesting case, thread A is runable at a higher priority than B and C; thread B holds a kernel object needed by A; thread B is blocked waiting for C to release a kernel object that it needs; and C is in a runable state. In Windows CE 2.12, when A runs and then is blocked on B, the priorities for both B and C are boosted to A's priority to enable them to run. In Windows CE 3.0, when A is blocked on B, only thread B's priority is boosted. By reducing the complexity and changing the algorithm, the largest Kcall in Windows CE was greatly reduced and bounded.
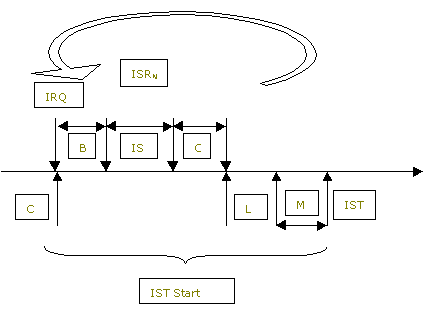
Real-time applications use interrupts as a way to ensure that external events are quickly noticed by the operating system. Within Windows CE, the kernel and the OAL are tuned to optimize interrupt delivery and event dispatching to the rest of the system. Windows CE balances performance and ease of implementation by splitting interrupt processing into two steps: an ISR and an IST.
Each hardware interrupt request line (IRQ) is associated with one ISR. When interrupts are enabled and an interrupt occurs, the kernel calls the registered ISR for that interrupt. The ISR, the kernel-mode portion of interrupt processing, is kept as short as possible. Its responsibility is primarily to direct the kernel to launch the appropriate IST.
The ISR performs its minimal processing and returns an interrupt identifier to the kernel. The kernel examines the returned interrupt identifier and sets the associated event that links an ISR to an IST. The IST is waiting on that event. When the kernel sets the event, the IST stops waiting and starts performing its additional interrupt processing if it is the highest-priority thread ready to run. Most of the interrupt handling actually occurs within the IST.
In the previous versions of Windows CE, when an ISR was running, all other interrupts were turned off. This prevented the kernel from handling any additional interrupts until one ISR had completed. So if a high-priority interrupt were ready, the kernel would not handle the new interrupt until the current ISR had completed operations and returned to the kernel.
To prevent the loss and delay of high-priority interrupts, Windows CE 3.0 supports nesting interrupts based on priority, if the CPU and/or additional hardware support it. When an ISR is running in Windows CE 3.0, the kernel runs the specified ISR, the same as before, but only disables the same and lower-priority ISRs. If a higher-priority ISR is ready to run, the kernel saves the state of the running ISR, and lets the higher priority ISR run. The kernel can nest as many ISRs as supported by the CPU. ISRs nest in order of their hardware priority.
In most cases an OEM's current ISR code does not change because the kernel takes care of the details. If the OEM is sharing global variables between ISRs, changes may be required, but in general ISRs are not aware that they have been interrupted for a higher-priority ISR. Where an ISR performs an action periodically, a noticeable delay may occur but only if a higher-priority IRQ is fired.
After the highest-priority ISR ends, any pending lower-priority ISRs are executed. Then the kernel resumes processing any Kcall that was interrupted. If a thread was being scheduled and was interrupted in the middle of its Kcall, the scheduler resumes processing the thread. This enables the kernel to pick up where it left off and not totally restart the scheduling of a thread, saving valuable time. Once the pending Kcall is complete, the kernel reschedules the threads for execution and starts executing the highest-priority thread that is ready to run.
Interrupt latency refers primarily to the software interrupt handling latencies; that is, the amount of time that elapses from the time that an external interrupt arrives at the processor until the time that the interrupt processing begins.
Windows CE interrupt latency times are bounded for threads locked in memory, if paging does not occur. This makes it possible to calculate the worst-case latencies—the total times to the start of the ISR and to the start of the IST. The total amount of time until the interrupt is handled can then be determined by calculating the amount of time needed within the ISR and IST.
ISR latency is the time from the point when an IRQ is set at the CPU to the point when the ISR begins to run. Three time-related variables affect the start of an ISR:
The start of the ISR that is being measured can be calculated based on the current status of other interrupts in the system. If an interrupt is in progress, calculating the start of the new ISR to be measured must account for two factors: the number of higher-priority interrupts that will occur after the interrupt of interest has occurred and the amount of time spent executing an ISR. The resulting start time of ISR is as follows:
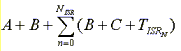
where
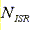
is the number of higher-priority interrupts that will occur after the interrupt of interest has occurred.
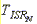
is the amount of time needed to execute an ISR.
The formula is graphically shown as follows:
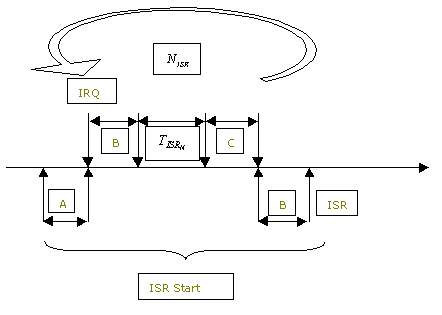
If no higher priority interrupts occur, as in
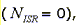
the previous formula reduces to:
start of ISR equals
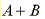
Both Windows CE and the OEM affect the time to execute an ISR. Windows CE is in control of the variables A, B, and C, all of which are bounded. The OEM is in control of
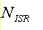
and
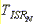
both of which can dramatically affect ISR latencies.
IST latency is the period from the point when an ISR finishes execution (signals a thread) to the point when the IST begins execution. Four time-related variables affect the start of an IST:
The start time of the highest-priority IST begins after the ISR returns to the kernel and the kernel performs some work to begin the execution of the IST. The IST start time is affected by the total time in all ISRs after the ISR returns and signals IST to run. The resulting start time is as follows:
start of highest priority IST equals
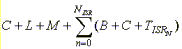
The formula is graphically shown as follows:
Both Windows CE and the OEM affect the time required to execute an IST. Windows CE is in control of the variables B, C, L and M, all of which are bounded. The OEM is in control of
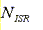
and
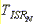
both of which can dramatically affect IST latencies.
Windows CE 3.0 also adds restrictions to ISTs: The event handle that links the ISR and IST can only be used in the WaitForSingleObject function. Windows CE 3.0 prevents the ISR-IST event handle from being used in a WaitForMultipleObjects function, which means that the kernel can guarantee an upper bound on the time to trigger the event and time to release the IST.
The updates to the kernel for Windows CE 3.0 include two kernel-level tools, Interrupt Timing Analysis (IntrTime) and Scheduler Timing Analysis (CEBench), to test the real-time performance of the kernel and measure specific latencies. Performance numbers are hardware-specific, depending on CPU type and speed, memory architecture, and cache organization and size.
The measurements of ISR and IST latencies have been combined in the IntrTime test tool that is freely available in source code and also distributed with Microsoft Windows CE Platform Builder. The measurements are done using the system clock timer in an effort to make IntrTime available to all hardware platforms on which Windows CE runs, because some platforms do not provide for a separate available unused timer.
Under normal circumstances, the system clock interrupts the kernel in regular intervals. The associated system timer ISR then processes the tick and returns either SYSINTR_NOP directing the kernel to ignore the tick or SYSINTR_RESCHED to wake up scheduler.
The IntrTime test tool measures the latencies by taking every nth tick of the system clock—defaults to every fifth system tick—and signaling a special SYSINTR_TIMING interrupt identifier event. The IntrTime application's main thread waits on the SYSINTR_TIMING interrupt event, thus becoming the IST. The ISR and IST measurements are derived from time stamps, that is, the counter values of the high-resolution timer since the last system tick.
Because IntrTime requires special modifications to the OAL only and not the kernel, it can be easily adapted and can run on any OEM platform.
The IntrTime command prompt parameters allow for the introduction of the following variations:
The IntrTime command prompt parameters are as follows:
Usage: intrtime [ options ]
Options:
-p num Priority of the IST (default 0 ; highest)
-ni no idle priority thread (default: idle priority thread spins)
-ncs no CacheSync call (default: flush cache after each interrupt)
-i0 no idle thread (same as -ni)
-i1 Run idle thread type 1
-i2 Run idle thread type 2
-i3 Run idle thread type 3
-i4 Run idle thread type 4
-sp Starts a secondary process
-t num SYSINTR_TIMING interval (default 5)
-n num number of interrupts (default 10)
-all print all data (default: print summary only)
-o file output to file (default: output to debug)
The IST can be run at different priority levels (-p). By default, the application flushes the cache before each run. The option -ncs disables the CacheSync call. The -t option sets the ISR rate, and the system tick ISR returns SYSINTR_TIMING every nth tick.
IntrTime can also create one or more idle threads running in the background. This affects the IST latencies by allowing the kernel to be in a nonpreemptible kernel call that must finish before the IST is run. Four types of idle threads are available:
For quick assessment of the day-to-day real-time performance of the system, the interrupt timing analysis tool is enough to determine the ISR and IST interrupt latencies. This convenient method works across all supported processors but relies on the timer on the device itself, which may affect the measurements.
Thus, a more elaborate setup can be used to accurately measure ISR and IST latencies. Two machines can be set up:
Testing is performed under various stress levels, running anywhere from one to hundreds of threads of varying priorities on the test device.
The Windows NT® 4.0–based workstation, equipped with a National Instruments PC-TIO-10 digital I/O timer/counter card, is used to generate interrupts and time responses, and a CEPC target platform equipped with an identical card is used to respond to those interrupts. The Windows NT software takes advantage of the driver library supplied by National Instruments, while the Windows CE software is written by Microsoft.
The theory of operation is simple: the PC-TIO-10 card has two sets of five timers. Each set contains one timer that provides 200-nanosecond resolution, while the other timers have one-microsecond granularity. In addition, the card contains two sets of eight digital I/O lines, with each set providing one line that can be used to interrupt on edge or level triggering. One output line from the Windows NT 4.0–based machine is wired both to the external interrupt pin of the CEPC target platform and back to the timers on the Windows NT 4.0–based workstation's card.
As the Windows NT 4.0–based workstation asserts one of its output lines, it generates an interrupt on the CEPC target platform and starts ISR and IST timers on the Windows NT card. The ISR on the CEPC target platform acknowledges the receipt of the interrupt by asserting an output line on the card, which stops the ISR timer on the Windows NT 4.0–based workstation and notifies the kernel to schedule the IST. When the IST starts running, it asserts a different output line, stopping the second timer on the Windows NT–based workstation. At this point, the Windows NT 4.0–based workstation can read the values on the timer counters to determine the intervals between an interrupt being generated and the CEPC target platform's responses. As soon as the Windows NT 4.0–based workstation has read the counter values, it issues another interrupt that the CEPC target platform uses to bring all output lines to the standby state, ready for another cycle.
Preliminary results gathered using the above measurements confirm the accuracy of the IntrTime testing results.
CEBench is the new performance tool for Windows CE 3.0. For scheduler performance timing, tests focus on measuring the time required to perform basic kernel operations such as synchronization actions: how long to acquire a critical section, how long to schedule a thread waiting on an event that another thread has just set, and so on. Wherever appropriate, the test runs two sets of metrics: thread-to-thread within a process and thread-to-thread across processes. If appropriate, a stress suite may be applied while running the test.
CEBench collects timing samples for the following performance metrics in Windows CE:
Metrics that are a bit different from the above yield/run scenarios are timings for interlocked APIs and the system call overhead. These metrics are Interlocked Increment/Decrement, Interlocked Exchange, and System API call overhead.
The CEBench command-prompt parameters are as follows:
Usage: cebench [ options ]
Options:
-all Run all tests (default: run only those specified by -t option)
-t num ID of test to run (need separate -t for each test)
-n num Number of samples per test (default = 100)
-m addr Virtual address to write marker values to (default = <none>)
-list List test ID''s with descriptions
-v Verbose : show all measurements
-o file Output to CSV file (default: output only to debug)
CeBench -list
TestId 0 : CriticalSections
TestId 1 : Event set-wakeup
TestId 2 : Semaphore release-acquire
TestId 3 : Mutex
TestId 4 : Voluntary yield
TestId 5 : PSL API call overhead
As with IntrTime measurements, the QueryPerformanceCounter function call is used to obtain timing information. In addition, at every timing point where QueryPerformanceCounter is invoked, a user can specify that a specific marker value be written to the virtual address. Providing the virtual address at the command prompt when CEBench is started enables this hardware verification feature. Markers written at the virtual address can then be monitored by an analyzer, independently timed by external device, and the results used to double-check the QueryPerformanceCounter timing accuracy. The setup similar to the external measurements of interrupt latency can be used for this purpose.
Using the QueryPerformanceCounter function call to get time stamps is not free. The frequency of the counter on a particular platform and the overhead of calling this function have to be taken into account when analyzing the results. Care needs to be exercised to provide for proper exclusions of the measuring overhead in the final timing numbers. The QueryPerformanceCounter call is looped for a number of iterations before every test and the average is subtracted from the final result.
In cases where the operation takes a very short time to complete, the overhead of the QueryPerformanceCounter function call becomes significant. In those cases, the operation is looped for a fixed number of iterations per sample (IPS), clear indication of which is provided with every test, and the result is then averaged. A special submarker value is provided for these cases if hardware verification was enabled. A side effect of this looping is that the cache cannot be flushed between the iterations of the operation. For other tests where the IPS is equal to 1, the test is run twice, once with and once without cache flush for each iteration.
The following is CEBench example test output:
============================================================
| 1.00 | IP = NO | CS = NO | 1 IPS
------------------------------------------------------------
Event intraprocess :
Time from SetEvent in one thread to a blocked WaitForSingleObject()
waking in another thread in the same process.
------------------------------------------------------------
| Max Time = 10.057 us
| Min Time = 5.867 us
| Avg Time = 6.823 us
============================================================
In the example of test number 1.00, the output of which is shown above, the operation was timing of the intraprocess event synchronization object. The IPS was 1; CacheSync (CS) was not done after each run; interprocess status (IP) shows that a second process was not used—both threads were in the same process. The maximum, minimum, and average results for 100 operations—the default if nothing is specified at the command prompt—are given in microseconds. The basic suite of tests and the overall layout of the CEBench program allow for easy additions of new test cases and measurements, augmenting the implementation for particular kernel functions that might be of special interest.
Performance measurements were taken on three x86 CPUs. All measurements are in microseconds, and the results could vary depending on system load.
The following table shows the ISR and IST latencies.
| ISR Latency in Microseconds | IST Latency in Microseconds | |||||
| CPU | Min | Avg | Max | Min | Avg | Max |
| 486-SX 33MHz | 10.8 | 12.8 | 53.6 | 99.7 | 115.7 | 152.5 |
| Pentium – 90MHz | 3.3 | 4.5 | 7.5 | 23.4 | 29.8 | 42.7 |
| Pentium II – 350MHz | 3.3 | 3.5 | 5 | 10 | 12.1 | 14.2 |
The CEBench tests were run on all three CPUs and used two basic variations to calculate the performance numbers:
The following table shows the results for the CEBench tests. The results are times in microseconds to perform a specific test, which is represented by a number in column one and defined following the table.
| CEBench Test Results (microseconds) | |||||||||
| 486-SX 33MHz | Pentium – 90MHz | Pentium II – 350MHz | |||||||
| Test | Min | Avg | Max | Min | Avg | Max | Min | Avg | Max |
| (1) | 148.343 | 156.622 | 182.705 | 36.876 | 38.272 | 48.609 | 7.543 | 7.966 | 11.734 |
| (2) | 159.238 | 161.591 | 165.105 | 37.714 | 38.831 | 42.743 | 7.543 | 8.677 | 10.058 |
| (3) | 1.616 | 1.630 | 1.641 | 0.151 | 0.152 | 0.158 | 0.226 | 0.227 | 0.232 |
| (4) | 1.480 | 1.468 | 1.492 | 0.116 | 0.117 | 0.125 | 0.207 | 0.208 | 0.212 |
| (5) | 180.190 | 189.714 | 216.229 | 87.162 | 90.09 | 99.733 | 20.953 | 21.74 | 27.658 |
| (6) | 184.381 | 186.497 | 188.571 | 82.133 | 85.35 | 89.676 | 20.115 | 21.553 | 22.629 |
| (7) | 124.038 | 130.903 | 154.209 | 29.333 | 30.458 | 33.524 | 5.867 | 6.484 | 15.924 |
| (8) | 165.105 | 174.035 | 197.790 | 42.743 | 43.411 | 52.8 | 7.543 | 8.618 | 18.438 |
| (9) | 172.648 | 185.168 | 215.390 | 87.162 | 89.955 | 98.895 | 20.115 | 21.469 | 27.658 |
| (10) | 215.390 | 225.667 | 250.591 | 109.79 | 111.771 | 120.686 | 24.305 | 25.752 | 26.819 |
| (11) | 133.257 | 140.918 | 167.619 | 29.333 | 30.213 | 31.847 | 6.705 | 7.678 | 17.6 |
| (12) | 176.838 | 185.413 | 211.200 | 43.581 | 44.96 | 56.152 | 8.381 | 9.43 | 18.438 |
| (13) | 179.352 | 181.256 | 182.705 | 85.486 | 87.432 | 98.895 | 20.115 | 21.384 | 34.362 |
| (14) | 222.095 | 234.218 | 259.810 | 109.79 | 113.159 | 132.419 | 25.143 | 26.243 | 31.848 |
| (15) | 153.371 | 160.787 | 184.381 | 35.2 | 37.011 | 48.609 | 7.543 | 7.822 | 16.762 |
| (16) | 199.467 | 208.507 | 229.638 | 48.609 | 50.073 | 58.667 | 9.219 | 9.828 | 18.438 |
| (17) | 200.305 | 211.242 | 239.695 | 96.381 | 98.226 | 109.79 | 23.467 | 24.161 | 25.981 |
| (18) | 242.210 | 256.711 | 280.762 | 117.333 | 121.473 | 133.257 | 26.819 | 28.225 | 39.391 |
| (19) | 60.343 | 65.726 | 92.190 | 13.409 | 13.874 | 15.085 | 3.353 | 3.7 | 5.029 |
| (20) | 96.381 | 103.034 | 130.743 | 29.333 | 30.738 | 43.581 | 5.029 | 5.587 | 8.381 |
| (21) | 60.343 | 64.237 | 96.381 | 18.438 | 20.994 | 29.333 | 4.191 | 4.597 | 15.924 |
| (22) | 96.381 | 102.196 | 132.419 | 34.362 | 36.351 | 46.095 | 6.705 | 7.585 | 11.734 |
| (23) | 40.678 | 41.264 | 41.396 | 8.757 | 8.794 | 8.836 | 3.67 | 3.685 | 3.76 |
| (24) | 40.732 | 41.123 | 41.196 | 8.805 | 8.812 | 8.878 | 3.661 | 3.676 | 3.855 |
| (25) | 46.790 | 47.321 | 47.399 | 9.675 | 9.684 | 9.731 | 3.959 | 3.968 | 4.118 |
| (26) | 80.023 | 80.149 | 80.335 | 24.732 | 24.738 | 24.748 | 6.109 | 6.195 | 6.319 |
| (27) | 81.904 | 81.936 | 81.991 | 24.702 | 24.709 | 24.718 | 6.092 | 6.187 | 6.352 |
| (28) | 86.616 | 86.711 | 86.806 | 26.006 | 26.01 | 26.022 | 6.361 | 6.409 | 6.556 |
| (29) | 20.868 | 20.877 | 20.897 | 4.879 | 4.883 | 4.887 | 1.376 | 1.382 | 1.427 |
| (30) | 0.414 | 0.426 | 0.454 | 0.006 | 0.007 | 0.017 | 0.03 | 0.03 | 0.035 |
| (31) | 0.417 | 0.429 | 0.455 | 0.006 | 0.007 | 0.02 | 0.03 | 0.03 | 0.035 |
| (32) | 0.570 | 0.584 | 0.608 | 0.084 | 0.086 | 0.093 | 0.078 | 0.079 | 0.085 |
| (33) | 0.444 | 0.456 | 0.481 | 0.028 | 0.029 | 0.043 | 0.018 | 0.019 | 0.023 |
The CEBench test descriptions are as follows:
(1) EnterCriticalSection traditional blocking with priority inversion: Time from the point when a lower-priority thread calls LeaveCriticalSection to the unblocking of a higher-priority thread waiting on an EnterCriticalSection call.
(2) EnterCriticalSection traditional blocking without priority inversion: Time from the point when a higher priority thread calls EnterCriticalSection (blocked) to the release to run of a lower-priority thread.
(3) EnterCriticalSection fastpath: An uncontested call to EnterCriticalSection.
(4) LeaveCriticalSection fastpath: An uncontested call to LeaveCriticalSection.
(5) EnterCriticalSection with inversion and CachSync: Time from the point when a lower-priority thread calls LeaveCriticalSection to the unblocking of a higher-priority thread waiting on an EnterCriticalSection call.
(6) EnterCriticalSection traditional blocking without priority inversion and CacheSync: Time from the point when a higher-priority thread calls EnterCriticalSection (blocked) to the release to run of a lower-priority thread.
(7) Event intraprocess: Time from the point when the SetEvent function in one thread signals an event to the release of a thread that is blocked on WaitForSingleObject in the same process.
(8) Event interprocess: Time from the point when SetEvent in one thread signals an event to the release of a thread that is blocked on WaitForSingleObject in a different process.
(9) Event intraprocess with CacheSync: Time from the point when SetEvent in one thread signals an event to the release of a thread that is blocked on WaitForSingleObject in the same process.
(10) Event interprocess with CacheSync: Time from the point when SetEvent in one thread signals an event to the release of a thread that is blocked on WaitForSingleObject in a different process.
(11) Semaphore signaling intraprocess: Time from the point when a lower-priority thread calls ReleaseSemaphore to the release of a higher-priority thread that is blocked on WaitForSingleObject in the same process.
(12) Semaphore signaling interprocess: Time from the point when a lower-priority thread calls ReleaseSemaphore to the release of a higher-priority thread that is blocked on WaitForSingleObject in a different process.
(13) Semaphore signaling intraprocess with CacheSync: Time from the point when a lower-priority thread calls ReleaseSemaphore to the release of a higher-priority thread that is blocked on WaitForSingleObject in the same process.
(14) Semaphore signaling interprocess with CacheSync: Time from the point when a lower-priority thread calls ReleaseSemaphore to the release of a higher-priority thread that is blocked on WaitForSingleObject in a different process.
(15) Mutex intraprocess: Time from the point when a lower-priority thread calls ReleaseMutex to the release of a higher priority thread that is blocked on WaitForSingleObject in the same process.
(16) Mutex interprocess: Time from the point when a lower-priority thread calls ReleaseMutex to the release of a higher-priority thread that is blocked on WaitForSingleObject in a different process.
(17) Mutex intraprocess with CacheSync: Time from the point when a lower-priority thread calls ReleaseMutex to the release of a higher-priority thread that is blocked on WaitForSingleObject in the same process.
(18) Mutex interprocess with CacheSync: Time from the point when a lower-priority thread calls ReleaseMutex to the release of a higher-priority thread that is blocked on WaitForSingleObject in a different process.
(19) Yield to thread timing intraprocess: Time from the point when a thread calls Sleep(0) to when a same-priority thread in the same process wakes from a previous call to Sleep(0).
(20) Yield to thread timing interprocess: Time from the point when a thread calls Sleep(0) to when a same-priority thread in a different process wakes from a previous call to Sleep(0).
(21) Yield to thread timing intraprocess with CacheSync: Time from the point when a thread calls Sleep(0) to when a same-priority thread in the same process wakes from a previous call to Sleep(0).
(22) Yield to thread timing interprocess with CacheSync: Time from the point when a thread calls Sleep(0) to when a same-priority thread in a different process wakes from a previous call to Sleep(0).
(23) System API call (roundtrip) intraprocess: Time required to call a system API that is part of the current process with no parameters and have the call return immediately.
(24) System API call (roundtrip) intraprocess: Time required to call a system API that is part of the current process with seven DWORD parameters and have the call return immediately.
(25) System API call (roundtrip) intraprocess: Time required to call a system API that is part of the current process with seven PVOID parameters and have the call return immediately.
(26) System API call (roundtrip) interprocess: Time required to call a system API that is in a different process with no parameters and have the call return immediately.
(27) System API call (roundtrip) interprocess: Time required to call a system API that is in a different process with seven DWORD parameters and have the call return immediately.
(28) System API call (roundtrip) interprocess: Time required to call a system API that is in a different process with seven PVOID parameters and have the call return immediately.
(29) System API call (roundtrip) to Nk.exe: Time required to call a system API in the kernel that returns immediately.
(30) InterlockedIncrement: Time to call the InterlockedIncrement API.
(31) InterlockedDecrement: Time to call the InterlockedDecrement API.
(32) InterlockedExchange: Time to call the InterlockedExchange API.
(33) InterlockedTestExchange: Time to call the InterlockedTestExchange API.
For the latest information about Windows CE and embedded development tools, see the Windows CE developer Web site at http://www.microsoft.com/windowsce/embedded/
The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication. This document is for informational purposes only.
This White Paper is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS DOCUMENT.
Microsoft, ActiveX, Visual Basic, Visual C++, Visual J++, Win32, Windows, and Windows NT are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries.
Java is a trademark of Sun Microsystems, Inc.
Other product and company names mentioned herein may be the trademarks of their respective owners.