Henry Lau
Microsoft Corporation
November 1998
Summary: Shows SAP R/3 database administrators and others who work on very large databases how to tune Microsoft® SQL Server™ version 7.0 for the workload conditions of the SAP R/3 environment. (22 printed pages) Covers:
Note "Microsoft SQL Server 7.0 Performance Tuning Guide" is companion reading to the index analysis section. Index analysis tends to be an involved process that will need to be performed on an ongoing basis for best database performance.
Windows 2000 Configurations
SQL Server Configurations
Index Design and Maintenance
File and File group Design
Finding More Information
The Windows 2000 page file should be sized at least three times larger than the amount of RAM installed on the server and be at least 1 gigabyte (GB).
To set the page file size
Usually, the VMM (Virtual Memory Manager) is already configured properly by the default setting for SQL Server installation.
To check and/or configure VMM setting
To configure minimal impact screen saver and wallpaper
Some multiprocessor servers can dynamically distribute networking I/O requests to the least busy processor. This hardware feature is helpful in preventing processor bottlenecks and poor network performance in systems that service many networking requests. This feature is often referred to as symmetric interrupt distribution and is designed to improve scaling and to prevent a single processor from becoming a bottleneck while other processors have excess capacity. It is available on the Windows NT® 4.0 Hardware Abstraction Layer (HAL) for the Pentium family of processors. This functionality will also be supported in Microsoft Windows 2000.
Different processor platforms use different methods to distribute interrupts. The distribution of interrupts from network adapter cards is controlled by the HAL for each processor platform. The interrupt scheme implemented by the HAL depends on the capability of the processor. Some processors include interrupt control hardware, such as the Advanced Programmable Interrupt Controller (APIC). The APIC allows processors to route interrupts to other processors on the computer. For more information about the distribution method used for a specific processor platform, consult with that platform's vendor.
In the default case, Windows NT 4.0 does not take advantage of symmetric interrupt distribution and assigns deferred process call (DPC) activity associated with network adapter cards (NICs) to the highest numbered processor in the system. In systems with more than one installed and active NIC, each additional NIC's activity is assigned to the next highest numbered processor.
If a processor frequently operates at capacity (indicated in Performance Monitor Processor: % Processor Time = 100%) and more than half of its time is spent servicing DPCs (if Processor: % DPC Time > 50%), it is possible to improve the performance by adjusting ProcessorAffinityMask.
Warning Using Registry Editor incorrectly can cause serious problems that may require reinstallation of the operating system. Use Registry Editor very carefully. Microsoft cannot guarantee that problems resulting from the incorrect use of Registry Editor can be solved. It is recommended that you back up the contents of the registry prior to performing modifications so that the contents can be restored in case of problems with registry modifications. Instructions for backing up and restoring registry information can be found in the online Help of Registry Editor.
On a multiprocessor server that is capable of symmetric interrupt distribution, set the ProcessorAffinityMask value entry in the Windows NT registry to zero. This distributes the network I/O requests dynamically to the processor that has the most capacity to process the request. ProcessorAffinityMask is located in HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\NDIS\Parameters.
To start the Registry Editor to set ProcessorAffinityMask
To find the appropriate key in the Registry Editor
To enter zero for ProcessorAffinityMask
The recommended settings for SQL Server memory depend upon the usage of the database server by the R/3 instance. With SQL Server running as a dedicated database server, it is recommended that SQL Server dynamically adjust the memory it requires, which is the default.
| R/3 Instance | Minimum value | Maximum value |
| Dedicated database server | Default | Default |
| Update Instance | 40 percent of installed RAM | 65 percent of installed RAM |
| Central Instance | 45 percent of installed RAM | 45 percent of installed RAM |
Example of setting memory on a Central Instance with 2 GB of RAM (Enterprise Manager)
After memory has been configured for SQL Server, it is recommended that the set working set size option be used to reserve physical memory space for SQL Server that is equal to the SQL Server memory setting. Setting this option means that Windows 2000 does not swap out SQL Server pages.
Example of configuring the set working set size option (Enterprise Manager)
SAP testing has indicated that a network packet size of 8,192 bytes is optimal for performance under most R/3 database server operating environments. This option needs to be set using SQL Server Query Analyzer.
To set network packet size (Query Analyzer)
On dedicated database servers, it is recommended that the SQL Server priority boost option be used.
To set the priority boost option (Enterprise Manager)
It is recommended that the SQL Server index create memory option be configured to 16 megabytes (MB). This option needs to be set using SQL Server Query Analyzer.
To set the index create memory option (Query Analyzer)
To disable page locks on tables VBHDR, VBMOD, and VBDATA (Query Analyzer)
exec sp_indexoption 'VBHDR','allowpagelocks','false'
exec sp_indexoption 'VBMOD','allowpagelocks','false'
exec sp_indexoption 'VBDATA','allowpagelocks','false'
If all of the processors on the database server are being very highly utilized (Performance Monitor indicates that Processor Utilization for all processors on the multiprocessor server are consistently greater than 95 percent), it is worthwhile to turn on SQL Server lightweight pooling. The lightweight pooling option can help recover from approximately 5 through 7 percent CPU when all processors are very close to being fully utilized.
To turn on SQL Server lightweight pooling (Enterprise Manager)
The SQL Server affinity mask configuration option provides for the specification of specific processors on which SQL Server threads cannot execute. It is best to take advantage of the default setting for SQL Server affinity mask, which is zero. The zero setting for affinity mask indicates that SQL Server threads are allowed to execute on all processors. In almost all situations, best performance results from this setting because it avoids trapping very busy SQL Server connections on a single processor while there is excess capacity available on other processors. Microsoft's Information Technology (IT) organization and SAP R/3 customers participating in the SQL Server 7.0 Early Adopter's program have made use of the default setting for affinity mask with good performance results.
"Microsoft SQL Server 7.0 Performance Tuning Guide" provides important information about SQL Server indexes and performance tuning. More on this companion article is discussed in the section "Finding More Information" at the end of this document.
Large SAP R/3 installations will have some SQL Server tables that contain a very large number of rows. With large tables, indexes have a sizable effect on database I/O performance.
Operations that search and operate upon a single database row or small number of database rows should have a nonclustered or clustered index defined upon the column or columns that provide the highest level of selectivity. This is so the SQL Server query processor and storage engine can minimize the I/O required to retrieve the rows. For example, if a single order record must be retrieved regularly from a very large Orders table based on the orderid, it would make sense to define an index on the orderid column to speed up the query.
Operations that search and operate upon a large number of database rows should have a clustered index defined upon the column that defines the range scan. An example of a range scan would be a query that retrieves all orders from a very large Orders table for the month of July. In this case, the date column of the Orders table would be the best column for the clustered index.
The upcoming 4.5B release of SAP R/3 will have an important feature that affects the flexibility of SQL Server clustered index selection. In the 4.5B release, there will be passive support in the R/3 Data Dictionary for clustered indexes on columns besides primary key columns. Passive support means that the SAP R/3 Data Dictionary will recognize and remember the location of a SQL Server clustered index if a database table is altered such that the clustered index is moved from the primary key to another column or set of columns. The creation of the clustered index needs to be done with SQL Server tools versus R/3 tools. But the location of the clustered index after it is created will not be lost during database conversions and R/3 version upgrades.
Future versions of SAP R/3 following 4.5B will likely contain active support for SQL Server clustered indexes. Active support means that R/3 tools will support the creation of clustered indexes on SQL Server tables on columns besides the primary key columns in addition to the support by the R/3 Data Dictionary as described earlier.
These changes in clustered index support have important ramifications for R/3 database administrators looking to improve the performance of their R/3 reporting queries. Month-end and quarterly reports for large companies running SAP R/3 will likely employ range scans on the database server. Often, it may be the case that the range scan being performed on a large table will not be based upon the same columns that define the primary key of the table. Currently, SAP R/3 SQL Server database implementation configures the primary keys on all tables to be a clustered primary key. There may be situations where it is very advantageous to test the use of a clustered index on a column that is not part of the primary key and is frequently used on a large table for reporting purposes. The ALTER TABLE command is used to change a primary key from clustered to nonclustered.
The following index analysis example discusses a scenario where it would make sense to change a clustered primary key to a nonclustered primary key so the clustered index can be defined on another column and walk through the steps involved in changing a clustered primary key to a nonclustered primary key.
See "Microsoft SQL Server 7.0 Performance Tuning Guide" for more details about clustered and nonclustered index selection.
SAP R/3 provides the MSSTATS tool within transaction ST04 to help R/3 database administrators track the resource consumption of SQL Server stored procedures being executed on the database server. All normal R/3 interactions with the database server are performed using stored procedures. MSSTATS provides information that helps differentiate stored procedures based on resource usage. Examples of the information that MSSTATS returns includes the number of times a stored procedure is called, average and maximum amount of time spent calling stored procedures, average and total rows returned from stored procedure calls, whether cursors were used by a stored procedure, time spent fetching versus idle for the stored procedures, and more.
MSSTATS provides an important tool for identifying the most costly stored procedures running on a R/3 database server. Performance analysis should be focused on these most costly queries.
The following SQL Server table example is designed to resemble a data pattern very similar to many SAP R/3 tables. Two sample queries will be analyzed using this test table. The goal is to demonstrate how to take best advantage of SQL Server indexes in the R/3 database server environment.
The following script creates a table called saptest1 and loads 100,000 records into it. The first column, named col1, has no selectivity. Every row has the same value for col1 ("000"). This is designed to simulate the very common MANDT column in SAP R/3, which is usually not very selective. The second column, named col2, is designed to have some selectivity because a value of 'a' is inserted every one hundred rows. The SQL Server modulo ("%") operator is used to detect every one hundredth row insert. The final column, named col3, is a very high selectivity. Every row has a unique value for col3.
To create the sample data (Query Analyzer)
create table saptest1 (
col1 char(4) not null default '000',
col2 char(4) not null default 'zzzz',
col3 int not null, filler char(300) default 'abc' )
declare @counter int
set nocount on
set @counter = 1
while (@counter <= 100000)
begin
if (@counter % 1000 = 0)
PRINT 'loaded ' + CONVERT (VARCHAR(10),@counter)
+ ' of 100000 record'
if (@counter % 100 = 0)
begin
insert saptest1 (col2,col3) values ('a',@counter)
end
else
insert saptest1 (col3) values (@counter)
set @counter = @counter + 1
end
SAP R/3 default configuration for SQL Server primary keys is to make the primary key a clustered primary key. This provides excellent performance in most situations. But there may be some isolated tables that would benefit greatly from placing the clustered index on a column besides the columns that comprise the primary key for the table.
The clustered primary key column defined for saptest1 is typical of the R/3 database environment because it places the completely nonselective column, col1 (which is modeled after the MANDT in typical R/3 environments), in the beginning of the index.
The nonclustered index nkey2 is modeled after typical R/3 indexes in that it is a multiple column index.
To create the sample indexes (Query Analyzer)
alter table saptest1 add constraint sapt_c1
PRIMARY KEY clustered (col1,col2,col3)
create index nkey2 on saptest1(col2,col3)
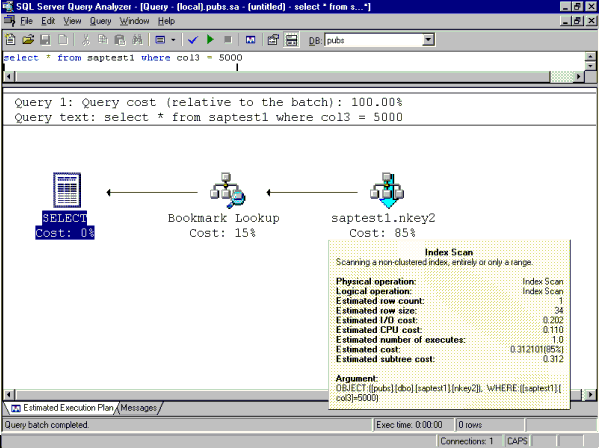
select * from saptest1 where col3 = 5000
Query 1 fetches a single row from the test table based on a matching value for col3.
select * from saptest1 where col2 = 'a'
Query 2 is a range scan that fetches 1,000 rows from the table based on a matching value for col2.
SQL Server Query Analyzer has the capability of providing valuable I/O statistics from each query executed in the Query window. This is commonly referred to in the SQL Server documentation as Statistics IO. To enable this functionality, you can either execute a T-SQL command or set Query Analyzer menu options.
To use the SET STATISTICS IO option via T-SQL command (Query Analyzer)
set statistics io on
To use the SET STATISTICS IO option via menu options (Query Analyzer)
Single Row Fetch: select * from saptest1 where col3 = 5000
Text-based ShowPlan output:
|--Bookmark Lookup(BOOKMARK:([Bmk1000]),
OBJECT:([pubs].[dbo].[saptest1]))
|--Index Scan(OBJECT:([pubs].[dbo].[saptest1].[nkey2]),
WHERE:([saptest1].[col3]=5000))
Figure 1. Equivalent graphical Showplan output
Query result set and database I/O from Stats I/O (Query Analyzer):
col1 col2 col3 filler
000 a 5000 abc
(1 row(s) affected)
Table 'saptest1'. Scan count 1, logical reads 240, physical reads 0,
read-ahead reads 0.
The Showplan output indicates that the query processor needed to perform an index scan of the nonclustered index nkey2. An index scan means that SQL Server needed to read part or all of the leaf level of the nkey2's B-tree structure in order to find the key value 5000. This operation required 240 I/Os out of the SQL Server data cache. That means 240 8-kilobyte (KB) pages had to be read from the SQL Server buffer cache. The zeros indicated for physical reads and read-ahead reads indicated that it was not necessary to read from disk to retrieve the data for this query.
Note The I/O statistics are run-specific. While on one run of a query, all reads may come out of buffer cache and be counted as logical reads; on other runs, it may be possible that the exact same query needs to use read-ahead reads and/or physical reads to statisfy the I/O requirements of the query. This fluctuation in I/O statistics may be due to many factors, the most common of which is the fact that other connections may be performing queries and bringing data into the buffer cache that displace data pages being used by the monitored query. When analyzing queries, it is helpful to run the query several times with I/O statistics turned on and compare the results.
The percentages indicated in the graphical Showplan labeled Cost indicate the amount of time spent on each particular part of the query as a percentage of the total time spent executing the query.
Range Scan: select * from saptest1 where col2 = 'a'
Text-based ShowPlan output:
|--Clustered Index Scan(OBJECT:([pubs].[dbo].[saptest1].[sapt_c1]),
WHERE:([saptest1].[col2]='a'))
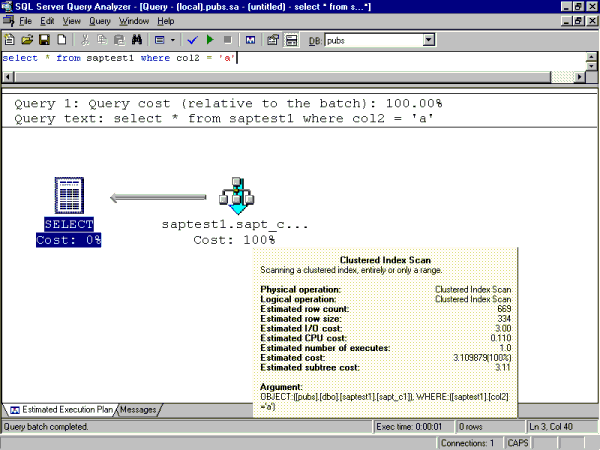
Figure 2. Equivalent graphical Showplan output
Query result set and database I/O from Stats I/O (Query Analyzer):
col1 col2 col3 filler
000 a 100 abc
000 a 200 abc
000 a 300 abc
.
.
.
000 a 99800 abc
000 a 99900 abc
000 a 100000 abc
(1000 row(s) affected)
Table 'saptest1'. Scan count 1, logical reads 4500,
physical reads 1, read-ahead reads 4010.
The Showplan output indicates that the query processor needed to perform an index scan of the clustered index sapt_c1. An index scan means that SQL Server needed to read all or part of the leaf level of sapt_c1's B-tree structure (which are the actual rows of the table) in order to find the key values 'a'. This operation required 4,500 8-KB pages to be read from the buffer cache. The read-ahead reads of 4010 indicates that SQL Server read in 4,010 8-KB pages in 64-KB chunks using the Read-Ahead Manager. Read-ahead reads are more efficient than physical reads. The physical read of 1 indicates that SQL Server needed to read one 8-KB page as a single 8-KB page from disk. Because they are both physical disk reads, read-ahead reads and physical reads are much slower than logical reads, which are reads from buffer cache. That is why it should be your primary performance tuning goal to limit physical disk reads and try to satisfy all database page reads from buffer cache.
The goal of index design is to minimize I/O to maximize performance. In the examples shown earlier, index scans occur. It is more efficient to perform index seeks versus index scans. To make this happen, it is important to focus attention on the WHERE clauses of the queries.
In the single-row fetch case, col3 is the column being searched on. Because col3 has excellent selectivity, it is a good candidate for a nonclustered index. It is best for I/O performance if the nonclustered is defined on col3 such that col3 is either the only column or the first in the index.
In the range scan case, col2 is the column being searched on. Col2 has okay selectivity (1,000 rows out of 100,000 with the value of 'a'). Because all of the 'a' rows are required, col2 is a good candidate for the clustered index.
The ALTER TABLE statement is used to change a clustered primary key to a nonclustered primary key.
Warning Do not change the columns that are associated with the primary key of a table under any circumstances. It is all right to change a clustered primary key to a nonclustered primary key and it is all right to create new nonclustered indexes on columns that are also part of the primary key if the performance benefits warrant the change, but the primary key columns must remain the same under all circumstances. This is extremely important to remember.
Note In the SAP R/3 environment, it is recommended that transaction SE11 be used to define nonclustered, nonprimary key indexes so that the index information is maintained in the R/3 Data Dictionary. For more information about index creation using transaction SE11, see the SAP online Help accessed from transaction SE11 on the menu item Help -> Extended Help. Click Indexes, and then follow the online instructions.
To execute index changes (Query Analyzer)
alter table saptest1 drop constraint sapt_c1
alter table saptest1 add constraint sapt_c1 PRIMARY KEY NONCLUSTERED
(col1,col2,col3)
create clustered index ckey1 on saptest1(col2)
create index nkey1 on saptest1(col3)
Single Row Fetch with Improved Index: select * from saptest1 where col3 = 5000
Text-based ShowPlan output:
|--Bookmark Lookup(BOOKMARK:([Bmk1000]),
OBJECT:([pubs].[dbo].[saptest1]) WITH PREFETCH)
|--Index Seek(OBJECT:([pubs].[dbo].[saptest1].[nkey1]),
SEEK:([saptest1].[col3]=5000) ORDERED)
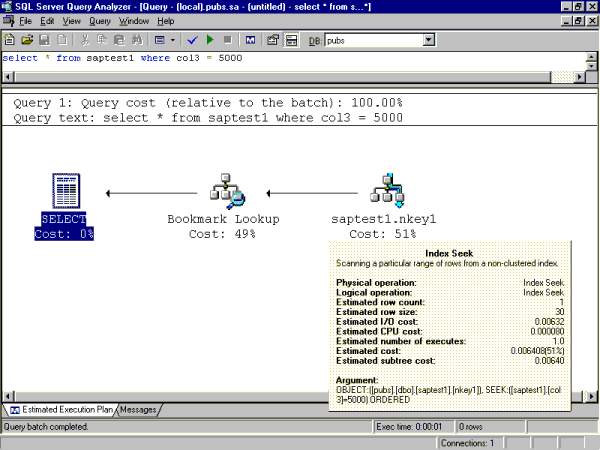
Figure 3. Equivalent graphical Showplan output
Query result set and database I/O from Stats I/O (Query Analyzer):
col1 col2 col3 filler
000 a 5000 abc
(1 row(s) affected)
Table 'saptest1'. Scan count 1, logical reads 5,
physical reads 0, read-ahead reads 0.
Showplan is now indicating that the SQL Server is using an index seek on index nkey1 versus an index scan. An index seek means that SQL Server was able to navigate the nkey1 B-tree structure quickly (versus scanning the leaf level of the index as was the case earlier) and use a bookmark lookup to find the data row associated with the key value of 5000. This change from index scan to index seek has a large effect on I/O performance. Only 5 I/Os from SQL Server data cache were required to execute the query as compared to 240 I/Os in the earlier case.
Range Scan with Improved Index: select * from saptest1 where col2 = 'a'
Text-based ShowPlan output:
|--Clustered Index Seek(OBJECT:([pubs].[dbo].[saptest1].[ckey1]),
SEEK:([saptest1].[col2]='a') ORDERED)
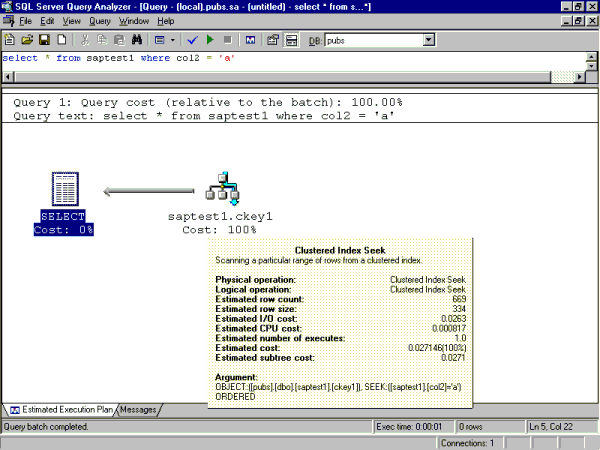
Figure 4. Equivalent graphical Showplan output
Query result set and database I/O from Stats I/O (Query Analyzer):
col1 col2 col3 filler
000 a 100 abc
000 a 200 abc
000 a 300 abc
.
.
.
000 a 99800 abc
000 a 99900 abc
000 a 100000 abc
(1000 row(s) affected)
Table 'saptest1'. Scan count 1, logical reads 48,
physical reads 0, read-ahead reads 0.
Again, Showplan is indicating that the SQL Server is using an index seek on index ckey1 versus an index scan. In the case of clustered index seeks, no bookmark lookup is required because the leaf level of the clustered index B-tree already contains the table data. Once again the change from index scan to index seek has a significant and positive impact on I/O performance. Only 48 reads from SQL Server buffer cache were required to fetch the 1,000 rows, as compared to 4,500 I/Os in the earlier case. The I/Os have been reduced dramatically, therefore no physical disk I/O was required to complete this query because the required pages were already present in the SQL Server data cache. This is indicated by the fact that both physical reads and read-ahead reads are zero. Remember that read-ahead reads are physical disk reads that are 64 KB per read and physical reads refer to physical disk reads that are 8 KB per read.
What should be clear from the earlier example is that index design plays a large part in the I/O performance of SQL Server queries. The range scan example in particular was designed to illustrate that there may be scenarios in your R/3 environment that may lend themselves to a clustered index on columns besides the primary key columns. This is particularly likely for large tables on which reporting is performed. For example, if a large table is used for reporting based on a date column, but the date column is not included in the clustered primary key, it may be very beneficial to test the use of the date column for the clustered index.
In SQL Server 7.0, the more columns and bytes that are included in the clustered index, the bigger the nonclustered indexes for that particular table become. This is because the column(s) that form the clustered index are used not only by the clustered index but also by the nonclustered indexes for that table. Nonclustered indexes contain the clustering key and use the clustering key to locate row data. If there is no clustered index on a table, this situation does not apply. Instead, the table is managed as a heap. For more information, see SQL Server Books Online.
There are two implications to be aware of now that nonclustered indexes contain the clustering keys within the nonclustered B-tree structures. First, it is important to keep the size of the clustered index smaller because it affects not only the size and performance of the clustered index but also of all the nonclustered indexes for that table. Second, it is useful to remember that nonclustered indexes contain the clustering key because that key value column can be used by the query processor to help cover queries if the nonclustered index contains all of the columns required to satisfy a query except the clustering key.
The following is a simple example, which shows that if the clustering key contains the only other information that the nonclustered index requires to cover a given query, the query processor uses the nonclustered index as a covering index and does not need to use bookmark lookups to fetch data from the table. For more information about covered queries and index design, see "Microsoft SQL Server 7.0 Performance Tuning Guide."
Build the following table (Query Analyzer)
create table saptest2 (col1 int, col2 char(4)
default 'a', filler char(300) default 'zzzz')
declare @counter int
set @counter = 1
while (@counter <= 1000)
begin
insert saptest2 (col1) values (@counter)
set @counter = @counter + 1
end
insert saptest2 values (1001,'sap','R/3')
create clustered index sap_CK1 on saptest2(col1)
create nonclustered index sap_NCK1 on saptest2(col2)
Display and compare the following two query plans (Query Analyzer)
select * from saptest2 where col2 = 'sap'
select col1,col2 from saptest2 where col2 = 'sap'
When troubleshooting long-running R/3 processes, one potential action item to keep in mind is the use of sp_recompile to mark stored procedures for recompilation quickly. The sp_recompile command takes very little time to execute and can be very helpful. The sp_recompile command marks the stored procedure quickly so that a new query plan is generated for the stored procedure—one that reflects the most current state of the table's data, indexes, and statistics.
Note Under most normal R/3 operating conditions, there is no need to run sp_recompile because SQL Server recompiles stored procedures automatically when it is advantageous to do so. But there have been circumstances in the R/3 environments, where SAP and Microsoft have observed very positive benefits to running sp_recompile on tables that have long running and poorly performing update and batch processes running on them.
One of the most convenient ways to use sp_recompile is to submit the table name as the parameter for the command. This will mark for recompilation all stored procedures associated with the table name. For example, if CCMS reveals that update processes operating on the table VBRP are taking an unusually long time to execute, it is worthwhile to run sp_recompile on the table.
Example of executing sp_recompile (Query Analyzer)
SQL Server 7.0 provides automatic generation and maintenance of column and index statistics. Statistics assist the query processor in determining optimal query plans. By default, there are statistics created for all indexes, and SQL Server creates single-column statistics automatically when compiling queries for columns where column statistics would be useful and the optimizer would have to guess them.
To avoid long-term maintenance of unused statistics, SQL Server ages the automatically created statistics (only those that are not a byproduct of the index creation). After several automatic updates, the column statistics are dropped rather than updated. If they are needed in the future, they may be created again. There is no substantial cost difference between statistics update and create. This aging does not affect user created statistics.
It is recommended that automatic statistics be used for best performance. Automatic statistics creation and update are the default configuration for SQL Server 7.0. The only exceptions to this recommendation are the tables VBHDR, VBMOD, and VBDATA. For these tables, it is recommended that automatic statistics be turned off. VBHDR, VBMOD, and VBDATA are very dynamic in nature, which means they may change from being empty to becoming very large, and then drop to empty again on a frequent basis. R/3 access to these tables is done only with the primary keys. Additional statistics on these tables will not be helpful because the same query plan using the primary key is used for every access. It is for these reasons that it is advantageous to turn off automatic statistics on these tables.
The following set of commands will prevent any future generation of statistics on the tables VBHDR, VBMOD, and VBDATA.
To turn off automatic statistics for VBHDR, VBMOD, and VBDATA (Query Analyzer)
exec sp_autostats VBHDR,'OFF'
exec sp_autostats VBMOD,'OFF'
exec sp_autostats VBDATA,'OFF'
To drop existing statistics (Query Analyzer)
exec sp_helpindex VBMOD
drop statistics VBRP._WA_Sys_VBELN_0AEA10A3
The DBCC SHOWCONTIG command is used to evaluate the level of physical fragmentation (if any) occurring on a table.
Example of running DBCC SHOWCONTIG (Query Analyzer)
declare @id int
select @id = object_id('saptest1')
dbcc showcontig (@id)
DBCC SHOWCONTIG scanning 'saptest1' table...
Table: 'saptest1' (933578364); index ID: 1, database ID: 5
TABLE level scan performed.
- Pages Scanned................................: 4167
- Extents Scanned..............................: 521
- Extent Switches..............................: 520
- Avg. Pages per Extent........................: 8.0
- Scan Density [Best Count:Actual Count].......: 100.00% [521:521]
- Logical Scan Fragmentation ..................: 11.21%
- Extent Scan Fragmentation ...................: 0.96%
- Avg. Bytes Free per Page.....................: 198.6
- Avg. Page Density (full).....................: 97.55%
DBCC execution completed. If DBCC printed error messages,
contact your system administrator.
Scan Density and Extent Scan Fragmentation help assess how well organized a table is on disk. One hundred percent Scan Density is the best possible value because it indicates that optimal number of extents are in use (for example, each extent is fully utilized with eight pages per extent). Extent Scan Fragmentation provides additional information on page splitting by indicating if the extents associated with the table ever move physically out of sequence on disk. Extent Scan Fragmentation is usable information only when there is a clustered index defined on the table.
Avg. Page Density (full) indicates average amount of data on each SQL Server data page as a percentage. Sometimes this percentage is also referred to as the fullness of the data page. A high percentage means that more data is brought into the SQL Server buffer cache with each 8-KB read. Overall, a high percentage means that the cache will contain more usable information. As an example, consider if the DBCC SHOWCONTIG indicated that there were several tables in your database that had an average page density of 50 percent. If these tables held a majority of the data that is retrieved, the SQL Server buffer cache will contain mostly data pages that only contain 50 percent of useful data. This would mean that a 1-GB buffer cache would contain only 500 MB of SQL Server data. If the average page density across tables being read into buffer cache were to improve to near 100 percent, a 1-GB buffer cache would contain close to 1 GB of SQL Server data, a much better situation.
If response times for queries accessing a table grow to unacceptably high levels, run the DBCC SHOWCONTIG command on that table. If Avg. Pages per Extent is significantly less than 8.0, Extent Scan Fragmentation is greater than 10-20 percent or Avg. Page Density (full) is significantly lower than 100 percent, it is worthwhile to consider rebuilding the clustered index on the table in order to physically resequence the data in the table onto physically contiguous extents. Rebuilding the clustered index also provides the option of choosing a fuller page fill in order to compact more data per 8-KB page.
Having well-compressed and contiguous data on disk helps I/O performance because SQL Server can make use of sequential I/O (which is much faster than nonsequential disk I/O) when fetching from this table and brings the maximum amount of usable SQL Server data into buffer cache with each read.
FillFactor is an option available with the CREATE INDEX statement that allows for control of the fullness of the leaf level of indexes. The leaf level of a table's clustered index are the data pages of the table, so use of the FillFactor option allows for control of the fullness of data pages on tables that use a clustered index.
The default value for FillFactor is zero. This default value enforces 100 percent fill in all of the data pages of a table. Microsoft's IT organization has been using the default value for FillFactor for a majority of the SQL Server tables in its SAP R/3 environment with excellent performance results. It is recommended that the default value for FillFactor be used as a starting point for R/3 database server testing.
The key relationship to keep in mind with FillFactor is that the I/O performance benefit of having the maximum amount of data packed into each data and index page should be balanced against the performance benefit of avoiding page splits. Page splits occur when data needs to be inserted into a page but the page is full. A new page has to be used, and data is reorganized across the old and new page. The enhanced storage structures of SQL Server 7.0 make page split operations much more efficient than SQL Server 6.5; there is not as much of a performance penalty from page splits. That is the reason the default FillFactor setting is a good place to start. If the DBCC SHOWCONTIG command reports that there is significant physical fragmentation occurring on a table and response times for the table are poor, the clustered index on that table should be rebuilt in order keep the index B-tree structures in optimal form.
The DROP_EXISTING option of the CREATE INDEX command is required in order to rebuild primary keys. It also provides enhanced performance for any index rebuild. The examples to follow assume that the indexes from the original saptest1 table described earlier are being rebuilt.
Example of rebuilding a clustered primary key (Query Analyzer)
create unique clustered index sapt_c1 on saptest2(col1,col2,col3)
with drop_existing
Example of rebuilding a nonclustered primary key (Query Analyzer)
create unique index sapt_c1 on saptest2(col1,col2,col3)
with drop_existing
Example of rebuilding a clustered index (Query Analyzer)
create clustered index ckey1 on saptest2(col2) with drop_existing
There may be some R/3 environments where insert activity is very high and it will be worthwhile to test the use of a lower percentage fill on data and index pages so that page splitting will be minimized. For more information about the syntax for using FillFactor in the CREATE INDEX statement, see SQL Server Books Online.
It is recommended that SQL Server files be sized such that there will be at least three equally sized SQL Server files per Redundant Arrays of Inexpensive Disks (RAID) array and these files should be set at maximum size to which they are expected to grow. Use autogrow to cover sizing emergencies. Defining three files is helpful for speeding up data redistribution if it is determined that more I/O processing power is required and a new RAID array needs to be brought online. To move data to the new array, the ALTER DATABASE command can be used to modify the database such that one file is located on the new RAID array. Then SQL Server can be shut down, the file can be quickly moved to the new array, and SQL Server can be brought back up.
Use the MAXSIZE option of the ALTER DATABASE command to prevent autogrow from exceeding the capacity of the RAID array. Prior to any file becoming full, use the ALTER DATABASE command to add a new file to the file group.
For best performance, it is recommended that transaction logs be created at the largest size that they will be expected to reach versus using a small initial size and letting autogrow increase the size of the log. This helps keep the number of virtual log files down. Use autogrow to cover emergency growth of the transaction log files. Use the MAXSIZE option of the ALTER DATABASE command, as shown in the next section, for tempdb to limit the growth of transaction log files so they do not exceed the capacity of the physical disk(s).
It is recommended that tempdb be sized at a minimum of 250 MB. Autogrow should be enabled, but if it is known through testing and previous experience that a large tempdb size will be required, it is recommended that tempdb be set to that size, versus letting autogrow expand tempdb to the required larger size, from the initial size of 250 MB.
To limit autogrowth of tempdb to 4 GB (Query Analyzer)
Exec sp_helpdb tempdb
alter database tempdb modify file (name = tempdev, maxsize = 4000)"Microsoft SQL Server 7.0 Performance Tuning Guide" provides valuable information about creating SQL Server indexes, tuning disk I/O, RAID, and use of SQL Server 7.0 performance tools. SAP administrators working with SAP installations running SQL Server are strongly encouraged to review this document.
SQL Server documentation provides information about SQL Server architecture and database tuning, along with complete documentation of command syntax and administration. Install SQL Server Books Online on the hard disk drives of computers that use SQL Server regularly because it is an extremely useful reference.
For the latest information about SQL Server, including other documents, visit the SQL Server Web site at www.microsoft.com/sql/.
R/3 Installation on Windows 2000—Microsoft SQL Server Database—SAP Release 4.0B0—Document Product ID 51002828—available from SAP AG.
Database Conversion: Microsoft SQL Server version 6.5 to 7.0—Document Product ID 51003094—available from SAP AG.