
Steve Land
Senior Developer, Initiatives Lead
Corbis (http://www.corbis.com/)
May 1999
Click here to download the sample application that accompanies this article.
Summary: Discusses the use of Extensible Markup Language (XML) as a means of transferring data in both Web and application development. (19 printed pages)
Introduction
Teach Yourself XML in Five Minutes
Style with Substance
A Parser for All Occasions
The DOM
You Have to Walk Before You Can Fly
The Bones of the X-Ray Sample
The Code Behind the Interface
Give Me Some Values: Getting Values from the DOM
Tag! You're It! Adding Tags and Attributes
Querying the DOM
XML Is for Developers On and Off the Web
There's a problem with XML. The problem is that XML, at first glance, looks like technology that Someone Else is supposed to use.
Take your typical Internet company. Some developers are busy building Web pages. Other developers are working on network architecture and database-driven applications. Until recently, many Web developers saw XML and said, "Great, but how does it help me make Web pages?" Application developers saw XML and said, "Great, those Web folks will really like that technology." And nobody (until recently) saw XML as applicable to their problems.
When I first saw XML, I (naively) dismissed it, too, because I thought it was meant to replace HTML as a standard. I saw lots of hype, but I largely ignored it. I had apps to build. I had a site to launch.
About six months ago, I saw the first practical application for XML and immediately realized that it could solve one of my real problems: refreshing editorial content on Web pages. My colleague built a sample Web site that uses XML for content and Active Server Pages (ASP) for display. The XML could be edited in XML Notepad, and ASP parses the content and spits out a flat Web page. The sample is elegant because it effectively separates the content from the display. For this application, when the content must be updated but not stored long-term, XML was the perfect solution.
Suddenly, XML was no longer something that Someone Else is supposed to use. I was using server-side XML to simplify a task that would have taken some rather elaborate code to simplify otherwise.
XML skills in hand, I set out to do something even more interesting: separate both layout and data from the ASP layer. I made a tiny .xml file that stored both cascading style sheets formatting parameters and database query syntax. When the application runs, the XML is parsed and the database queries are run, resulting in a flat HTML page. Whenever someone wants to redesign the presentation of the data, or even to add new data, I don't need to touch the ASP code. I just open up the .xml file, which is, in essence, simply a structured text file, make some tweaks here and there, and the app performs its generic magic.
Finally, I thought, I've discovered the value of XML. I don't need to wait for browsers to be XML-enabled, I can simply create semi-structured text-based .xml files and create generic server-side applications to parse the file and format Web pages. Then, my generic .asp files simply use XML to handle the aspects of the page that might change, whether formatting or content.
I was using XML, but I still didn't see the big picture.
I didn't see it until I attended the Xtech '99 conference. In a session led by Tim Bray, co-editor of the XML 1.0 specifications, I heard something that I might otherwise have regarded as pure hype: "XML is the ASCII of the future." He was talking about using XML to exchange data across the Web. He described using XML to create data structures that can be shared between and among disparate and otherwise incompatible systems. Most of the speakers at this conference agreed that XML is to be a common meta-language that will enable data to be transformed from one structure to another. Even ASCII, or American Standard Code for Information Interchange, was not this ambitious.
I realized that XML is useful even if you don't have a Web page.
XML implements a not-so-new idea: Data should be exchanged in the form of documents, such as product catalogs, invoices, purchase orders, contracts, and more. Businesses are already familiar with document exchange. End users can understand the concept of documents more easily than they can understand abstract data structures. Companies and individuals can agree on common document formats much more easily than they could rearchitect their back-end data structures.
Although XML was designed primarily for the Web, its usefulness extends beyond the confines of a browser's window or an HTML page. For example, XML separates data from layout in a way that hides both the data source and the formatting from one another. It doesn't matter whether the XML came from a database or from someone typing it in Notepad; if the file is well-formed (that is, conforms to XML syntax rules), any XML parser can read it. This is not always the case with other types of data exchange. Often, a developer must deal with the back-end data structure in order to extract the data he or she wants. With XML, a developer locally consumes, creates, or modifies data from a logical data structure that is independent of all back-end implementation. Multiple data sources may feed data into a single type of XML structure, allowing seamless integration of disparate systems. Because XML is plain text, this integration may take place through the Web via HTTP.
You can write an .xml file in Notepad, but you don't want to have to write custom parsers for every application. That's where Microsoft Internet Explorer 5.0 comes in. Internet Explorer 5 launched with full support for the World Wide Web Consortium (W3C) XML standard and it includes a parser—the Internet Explorer 5 XML component—that not only works in the browser, but can work in any server-side application using standard COM interfaces. If you're already familiar with general XML concepts, which I'll outline briefly in the next section, you may still be interested in the last section of this article, where I will describe how I built the sample application, X-Ray, using the Internet Explorer 5 XML parser. The X-Ray sample is a Microsoft Visual Basic® version 6.0 application that demonstrates some of the core features of the Internet Explorer 5 XML component.
In this section, I'll outline some of the essential concepts of XML and relate them with the DOM, or Document Object Model, which is the basis of the Internet Explorer 5 XML interface. If you are hungry for details about XML, visit http://msdn.microsoft.com/xml/.
Unlike HTML, which uses Markup Language to describe the structure of a document and implies layout, XML markup describes a document's content. Consider the following product description in HTML:
<HEAD>
<TITLE>Printer
</HEAD>
<BODY>
<H1>KomputerSource's Wizbang 3000 dot matrix printer</H1>
<UL>Features:
<LI>40 pages per minute
<LI>60 dpi printing
</UL>
<P>$200.00
<P>10 lbs.
</BODY>
The same product description in XML might look like this:
<?xml version="1.0"?>
<MANUFACTURER>KomputerSource
<PRODUCT>
<CLASS>Printer
<TYPE>dot matrix</TYPE>
</CLASS>
<NAME>Wizbang3000</NAME>
<FEATURES>
<SPEED Units="ppm">40</SPEED>
<QUALITY Units="dpi">60</QUALITY>
</FEATURES>
<PRICE Units="USD">
<RETAIL>200</RETAIL>
<WHOLESALE>110</WHOLESALE>
</PRICE>
<WEIGHT Units="lbs">10</WEIGHT>
</PRODUCT>
</MANUFACTURER>
The XML markup tells nothing about how the XML will be formatted, but it richly describes the contents of the document, both through explicit descriptions (the tag names and attributes) and through implicit structure (how the tags are nested within one another). Because XML separates information from its end use, any system that can read an XML document can extract relevant content.
A bit about the XML structure in this example: the <PRODUCT> is a child of the <MANUFACTURER>. This would be a reasonable structure if you are a manufacturer and have many products in your XML catalog. If, instead, you are a wholesaler and have many products from many manufacturers, you might have <PRODUCT> be the parent of <MANUFACTURER>. The beauty of XML is that you can define different data views with different XML structures based on the needs of the data consumers. As my company worked to define an XML schema for our product catalog, we realized that we had two different types of consumers. Rather than attempting to force-fit the two data requirements into a single schema, we decided to publish two catalogs. Because the Internet Explorer 5 XML component will do the heavy lifting of creating the .xml file, publishing two catalogs will not require twice the effort.
The good news is that XML is a standard. If your information is encoded into a well-formed XML document, any XML-enabled system can scan and repurpose the information in your document. The contents may be formatted for people to read, translated into database tables, or converted into a different XML structure. In the XML example just shown, a wholesaler could easily read the products from a <MANUFACTURER>-centric XML structure and rearrange that manufacturer's tags and data to fit into a <PRODUCT>-centric structure. In fact, the next section of this article will show you the code to do this. The tags and structure allow for automated processing: U.S. dollars may be converted to euros, keyword searches can be made more intelligent, and many XML-tagged products can be sorted by any combination of criteria, such as price, speed, quality, and so on.
Another extremely useful feature that is built into XML is the idea that documents contain information about themselves—metadata. If the tags and attributes are well-designed, both people and computers can read and use the information contained in the XML document. Document Type Definitions, or DTDs, formally declare the type of document an .xml file represents. DTDs describe explicitly the elements that may be allowed, in what quantity and sequence, in that DTD's XML document type. Specifically, a DTD defines such things as the valid tag names and attribute names, which fields are optional, which are required, and which may occur multiple times in the document. In a vertical marketplace, companies may define a common DTD to describe products, processes, customers, and so on. Once standard DTDs are established, data consumers will be able to rely on a specific document structure. There won't need to be such an emphasis on translating .xml files from one company's schema to another's.
An .xml file may include its DTD in the file or link to an external .dtd file. XML does not require that all files have a DTD, but all .xml files must be well-formed.
A DTD for the preceding XML example might include the following content model for the PRODUCT element:
…
<!ELEMENT PRODUCT (CLASS, NAME, FEATURES, PRICE, WEIGHT)>
…
Translated, this means that a PRODUCT element must contain a CLASS, NAME, FEATURES, PRICE, and WEIGHT. For more information about DTD syntax, visit http://msdn.microsoft.com/xml/.
If two or more users decide to share a common DTD, the XML documents they produce will be completely interchangeable because the documents share a common structure. For example, if Company A manufactures computers and Company B makes printers, and if they both use the same DTD to describe their products, a third company, Company C, could receive XML product catalogs from both companies and could easily combine the product lines into a single catalog. Updating this catalog would be a piece of cake, too.
But what if everyone begins using their own DTDs? What if everyone makes up different and competing XML structures? What if we all don't get along after all?
In the world of XML, this is not such a big problem. XML can be transformed easily using the Extensible Style Language (XSL). The W3C working draft for XSL describes two types of XSL: XSL for formatting and XSL for data transformation. XML documents may be converted into a formatted, human-readable document, or transformed into another data structure, including another XML document with a different DTD. For data, the XML working groups are in the process of defining syntax standards for XML-Data schemas. When their work is complete, there will be a standard way to work with XML structures as data. For the latest status of the XSL and XML-Data standards, visit http://www.w3.org/.
XSL transformations are exciting stuff. This article will give a taste for what XSL can do, but is by no means comprehensive. If you wish to find out more about XSL, visit http://msdn.microsoft.com/xml/.
Suppose we wanted to create an HTML page that displays this information about PRINTER products:
Wizbang3000
Retails for only $200.00
Prints at 60 dpi
Our HTML would look something like this:
<HTML xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<BODY>
<P><b>Wizbang3000</b></P>
<P>Retails for only $200.00 </P>
<P>Prints at 60 dpi </P>
</BODY>
</HTML>
To translate the XML example just shown into this HTML format, we could use this .xsl file. When this .xsl file is applied to the sample XML product catalog at the beginning of this article, the XSL tags (those that begin with <xsl: ... > ) will be replaced with values, leaving behind well-formed HTML. Notice how XSL uses patterns to make reference to the tags in the XML structure:
<?xml version="1.0" ?>
<HTML xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<BODY>
<!-- this for-each will loop for every PRODUCT node
underneath MANUFACTURER. If the MANUFACTURER had
many products, they would each be displayed using
the same HTML tagging. //-->
<xsl:for-each select="MANUFACTURER/PRODUCT">
<P><b>
<xsl:value-of select="NAME" />
</b></P>
<P>Retails for only
$<xsl:value-of select="PRICE/RETAIL" />.00
</P>
Prints at <xsl:value-of select="FEATURES/QUALITY" /> <xsl:value-of select="FEATURES/QUALITY/@Units" />.
<!-- the @Units refers to the attribute of the QUALITY tag //-->
</xsl:for-each>
</BODY>
</HTML>
You may apply the style sheet on the server using the Internet Explorer 5 XML component's transformNode() method, returning generic HTML. Or, you may apply the XSL in Internet Explorer 5 on the client. As you can see in the preceding example, the XSL tags are scattered among regular HTML tags, much like ASP. Because both HTML and XML are text-based documents, you could intersperse XSL inside a new XML structure to transform the .xml file—for example, if your wholesale company wanted to translate our sample .xml file into a format that had <MANUFACTURER> as a child of <PRODUCT>, like this:
<product xmlns:dt="urn:schemas-microsoft-com:datatypes">
<manufacturer>KomputerSource</manufacturer>
<name>Wizbang3000</name>
<wholesale>110</wholesale>
</product>
Note I changed the node names to lowercase. Because XML is case-sensitive, this matters. I chose to change the case to make the post-transformation .xml file look visually distinct from the original.
The .xsl file to follow, applied to our sample .xml file, will accomplish the transformation for you. Note that XSL may be used to transform XML into text, too.
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<xsl:template match="/">
<product xmlns:dt="urn:schemas-microsoft-com:datatypes">
<xsl:for-each select="MANUFACTURER/PRODUCT">
<manufacturer>
<xsl:value-of select="//MANUFACTURER/textnode()" />
</manufacturer>
<name>
<xsl:value-of select="NAME" />
</name>
<wholesale>
<xsl:value-of select="PRICE/WHOLESALE" />
</wholesale>
</xsl:for-each>
</product>
</xsl:template>
</xsl:stylesheet>
If XML is the common syntax that allows disparate data sources to communicate, the XML parser is the translator. A good XML parser would make it simple to read the tags, attributes, values, text, and structure of an XML document. It would tell you if the .xml files were well-formed (syntax) and valid (conforms to the rules of its DTD, if it has one). A good XML parser would let you group things based on shared features. It would allow you to manipulate the XML "tree" by adding tags and attributes. This all-purpose translator would allow applications to work seamlessly with XML documents.
The Internet Explorer 5 XML component is just such a parser; it does all these things and more. Although this component is part of Internet Explorer 5.0, once it is installed it may be used, server-side, by any application.
As I learned more about the Internet Explorer 5 XML parser, I found that my understanding of the parser depended on my understanding an interface established by the W3C: the Document Object Model (DOM). This model exposes an XML document as a tree structure composed of nodes. The Internet Explorer 5 XML component works with XML documents through four basic interfaces: the Document, the Node, the NodeList, and the NamedNodeMap. Although the foundation of any XML DOM instance is the Document, the Node interface is the one you'll probably find yourself using the most.
A node is a discrete piece of the XML tree structure and can be one of many NodeTypes, listed below. These NodeTypes are enumerated constants; the numeric value of each constant is in parentheses next to the name. NodeTypes that are beyond the scope of this article are noted with an asterisk (*). XML snippets that correspond to each enumerated NodeType are in bold.
| NODE_ELEMENT (1) | <ELEMENT> … </ELEMENT> |
| NODE_ATTRIBUTE (2) | <ELEMENT ATTRIBUTE="This is a node attribute" /> |
| NODE_TEXT (3) | <ELEMENT>This is Node text.</ELEMENT> |
| NODE_CDATA_SECTION (4) * | <ELEMENT><![CDATA[a CDATA section is used to escape a block of text that would otherwise be recognized as markup.]]></ELEMENT> |
| NODE_ENTITY_REFERENCE (5) * | <Element>&ent;</Element> |
| NODE_ENTITY (6) * | <!ENTITY % textgizmo "fontgizmo"> |
| NODE_PROCESSING_INSTRUCTION (7) * | <?XML version="1.0" standalone="yes" ?> |
| NODE_COMMENT (8) * | <!-- This is a comment --> |
| NODE_DOCUMENT (9) | <XMLROOTELEMENT> …(entire xml tree) … </XMLROOTELEMENT> |
| NODE_DOCUMENT_TYPE (10) * | <!DOCTYPE INVOICE SYSTEM "http://www.xml.com/product.dtd"> |
| NODE_DOCUMENT_FRAGMENT (11) * | <ELEMENT> … (subtree) … </ELEMENT> |
| NODE_NOTATION (12) * | <!NOTATION gif SYSTEM "viewer.exe"> |
* Not covered in this article. All NodeTypes are listed for reference only.
The NodeTypes that you will encounter most often in XML are NODE_ELEMENT, NODE_ATTRIBUTE, NODE_TEXT, NODE_DOCUMENT, and NODE_CDATA_SECTION. Figure 1 shows another view of some of the preceding NodeTypes, this time in the context of a full XML document.
Figure 1. NodeTypes within an XML document
After fully understanding the DOM, I rolled up my sleeves and began building my sample application, X-Ray. X-Ray demonstrates four general tasks you might want the to do using the Internet Explorer 5 XML parser:
Even if an XML document arrives on my shores via a transmission over the Web, it will need to be parsed—server-side—into something meaningful for my enterprise. XML is exchangeable, reusable, transformable; the X-Ray application demonstrates how the Internet Explorer 5 XML parser makes it easy to find relevant information, do something useful with it, and alter or add information.
Figure 2 is an overview diagram of the interface for the sample application, X-Ray.
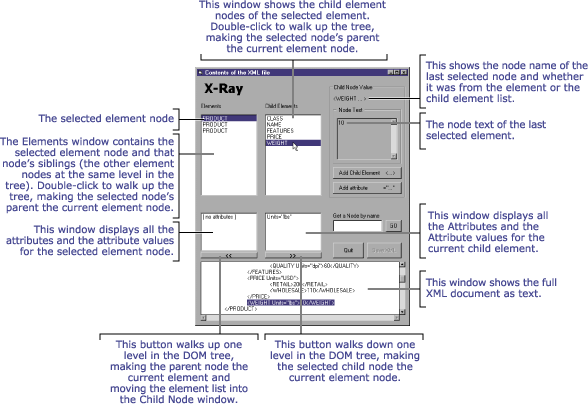
Figure 2. The interface for the X-Ray sample
The sample application allows users to double-click element nodes to walk up a level to the parent node or down a level to the next set of child nodes. Although many XML applications, such as Microsoft's XML Notepad, use a file tree-style interface, this two-window parent/children view of the XML document more closely mirrors the logic used behind the scenes to navigate the DOM.
In the sample X-Ray application, I decided to walk the tree without a net. I decided that I would use the current element node as my context for walking the tree. I would not track how deep under the document root I was or in what order the nodes were traversed to get to the current element. If I had tracked the context within the document, I would have a record of clicks, which would tell me how far currNode is from the documentNode, the parent's ancestry, where in the list of each level's siblings each parent lives, and more. I chose not to track this so as to challenge myself to create a generic code base that could be applied to any XML document.
Being generic is not without a price: When a user selects an element, X-Ray must look to the selected element's parent node in order to determine which node, among a collection of sibling nodes, was actually selected. Nodes, as I just described, are not always element nodes. For example, if the second node in a list of sibling element nodes is selected, it may not be the second node in its parent's childNodes collection. The first node could be a NODE_TEXT type node, the second node may be a NODE_ATTRIBUTE type, the third may be a NODE_ELEMENT, and the fourth may be the second NODE_ELEMENT underneath the parent node. In this case, the second node in the NODE_ELEMENT list would be the fourth node in the parent node's childNodes collection. As you might guess, because the UI only displays element nodes and doesn't keep track of them in relation to all the other types of nodes, I had a bit of extra work to do.
The first step to walking the tree is to create a new MSXML DOMDocument. In Visual Basic, this is done like so:
Dim xDoc As New DOMDocument
...
' load the DOMDocument from a file
' Note: You could also use the Load method to load a
' remote XML file using
' xDoc.Load("http://www.XMLHOST.com/XMLFILE.xml")
' however, in order to process remote files you would
' need an additional function to check
' the document's readyState property.
xDoc.Load (GetXML.Text1.Text)
' we are at the root node. refer to the document element
' xDoc should only have one child, the root element
...
Set currNode = xDoc.firstChild
...
Conceptually, at any point in the XML tree, X-Ray keeps track of where it is by means of a single node, currNode. The Internet Explorer 5 XML parser provides enough contextual information from a single node for you to be able to walk the tree, including the answers to the following questions:
For this sample, these three questions provide enough context to be able to navigate the entire XML tree. If the parent nodeType is a NODE_DOCUMENT (9), the currNode is at the top of the XML tree. If the currNode has children, I store them all in an IXMLDOMNodeList collection—a collection of IXMLDOMNode objects. Because X-Ray displays all the nodeType=Element children in the Child Node window, this collection makes coding a little more convenient because I can access the child nodes directly in the list rather than having to constantly traverse down through the currNode's childNodes NodeList. The same is not true for the currNode's siblings, which is why the application needs to look at the currNode's parent every time a user wants to do something in the left-hand Element window.
Whew! I have to keep track of a big family of parents, siblings, and children. Once you start using the component, you'll see that it's simple to manage these relationships.
The collection of currNode's childNodes, stored in the IXMLDOMNodeList object currNodeList, makes it very simple to move up and down the tree. I do this with two small functions (the meat of each function is in bold):
Private Function WalkDownDOM()
...
Set currNode = currNodeList(ChildNodesList.ListIndex)
Set currNodeList = currNode.childNodes
' call functions to populate the listboxes in the interface.
' Because what was a child is now the parent, X-Ray will make
' this the selected element and populate the ChildNodesList
' accordingly.
FillRootNodesList
FillChildNodesList
End Function
Private Function WalkUpDOM()
...
If currNode.parentNode.nodeType = NODE_DOCUMENT Then
' it's the root
MsgBox ("You are at the top of the XML tree.")
Else
' go up the tree
Set currNode = currNode.parentNode
Set currNodeList = currNode.childNodes
' call function to populate Element listbox
' in the interface. Because no elements are selected,
' the ChildNodesList will not be populated right now.
FillRootNodesList
End If
End Function
Another major part of the X-Ray sample involves displaying the contents of the XML tree as you walk through it. This is slightly more complicated than moving the currNode around because we not only want to show the currNode's children, we also want to show the currNode's siblings. The following chart shows the strategy used to get all the siblings of the currNode.
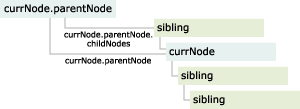
The following function spins through the siblings of the currNode by walking up to the parentNode and then back down through all the parentNode's childNodes. When it comes to a NODE_ELEMENT type node, it adds the node name to the list box called RootNodes (in the UI, this is the left-hand Elements window).
Private Function FillRootNodesList()
...
For i = 0 To currNode.parentNode.childNodes.length - 1
If currNode.parentNode.childNodes(i).nodeType = _
NODE_ELEMENT Then
' don't show non- NODE_ELEMENTS
' add to RootNodes listbox
RootNodes.AddItem _
(currNode.parentNode.childNodes(i).nodeName)
End If
Next
End If
FillChildNodesList
End Function
The Internet Explorer 5 XML parser allows an alternate way of viewing a node's siblings: the nextSibling and previousSibling node properties. For my generic walk through an XML DOMDocument, these properties were not my first choice because I don't know which sibling in the list the currNode is. It may be the first, it may be in the middle, or it may be at the end; for data fidelity I wanted the application to show the nodes in the same sequence as the original document. If I were to use the nextSibling and previousSibling properties, I might have to back up, turn around, and walk to the other end of the Sibling list. Starting from the parentNode is clean and you'll get the nodes in the proper sequence, as long as you are sure to check for the top of the document!
The attributes and values for the selected currNode and the selected childNode in the Child Node window are displayed from the subroutine RootNodes_Click(). The largest task for this routine is to match the selected list item in the UI to the corresponding child node of the parent. Because the parent has more child nodes than the list box displays, a variable called selectedIndex must be set to the index of the selected element node in the parent's childNodes NodeList. Because the application does not explicitly associate the displayed items and the childNodes collection, it must do some fancy footwork at the time of the click.
Private Sub RootNodes_Click()
...
selectedIndex = RootNodes.ListIndex
For p = 0 To currNode.parentNode.childNodes.length - 1
If currNode.parentNode.childNodes(p).nodeType _
<> NODE_ELEMENT Then
' to account for invisible non-Element nodes
selectedIndex = selectedIndex + 1
End If
Next
...
Set currNode = currNode.parentNode.childNodes(selectedIndex)
Set currNodeList = _
currNode.parentNode.childNodes(selectedIndex).childNodes
' Call the function to show childNodesList in the interface
FillChildNodesList
...
End Sub
The preceding subroutine also takes care of displaying the selected node's text, if it exists, and the node's attributes. The overhead of having to go up to the parent to track down which node matches the list box item is a byproduct of the application's design. If all nodeTypes were listed, there would be no need to set the selectedIndex; the RootNodes.ListIndex would suffice. I could have saved myself some trouble if I'd kept an array to keep track of the nodes that are visible and those that are not from the time that the items are added to the list box.
Once we have found the selectedIndex, we can look at the properties of the selected node:
Nodeinfo.Text = "<" + currNode.parentNode.childNodes(selectedIndex).nodeName + " ... >"
If an XML node has text between two tags, you may access the text with the currNode.Text interface. However, if that node has other child nodes that also contain text between tags, currNode.Text will return all of the child text as well. So, if you simply ask for the SOMETAG element's text in the following XML node, you'd probably want to get "this is some text", but instead you'd get "this is some text and more text":
<SOMETAG>this is some text
<CHILDELEMENT>and more text</CHILDELEMENT>
</SOMETAG>
To display the text only from the top element node (in the preceding example, SOMETAG), walk through all the childNodes of the selectedIndex node. The currNode.Text property gets all NODE_TEXT values together. By finding the specific NODE_TEXT child that is directly associated with currNode, you will retrieve only that node's text; in this example, elemTxt would be set to "this is some text" if currNode is the element node SOMETAG:
For j = 0 To currNode.childNodes.length - 1
If currNode.childNodes(j).nodeType = NODE_TEXT Then
elemTxt = currNode.childNodes(j).Text
End If
Next
One of the best things about the new Internet Explorer 5 XML parser is that .xml files can be manipulated directly—no more tacking tags and values together as a long string!
Adding tags is very simple. X-Ray's function fnAddChildElem is long because it must do some validation to make sure the chosen tag name is valid and because it must determine which tag to add the node to. Once you've done that, it's a piece of cake: Create a new node, append it to another NODE_ELEMENT, and you're done!
A modification of the X-Ray code shows the basic steps in creating a new node:
' Assumes: xDoc is an existing MSXML.DOMDocument
' currNode is a NODE_ELEMENT inside xDoc
' Append a new NODE_ELEMENT to currNode
Dim node1 As IXMLDOMNode
' This syntax--"element" instead of NODE_ELEMENT --
' works the same as the line after:
'---> Set node1 = xDoc.createNode("element", "NEWNODENAME", "")
Set node1 = xDoc.createNode(NODE_ELEMENT, "NEWNODENAME", "")
Set node1 = currNode.appendChild(node1)
Although the calling document, xDoc, does the job of creating the node, the node exists in the document without being attached to any other node—it has no parent. Once the node is appended to currNode using currNode's appendChild method, the node exists in a context inside xDoc.
Adding attributes is just as simple:
This simplified code shows how to add a new attribute to an existing element node:
' Assumes: xDoc is an existing MSXML.DOMDocument
' currNode is a NODE_ELEMENT inside xDoc
' Add a new attribute to currNode
Dim node1 As IXMLDOMAttribute
Dim node2 As IXMLDOMNode
' Create a new attribute in the document
Set node2 = xDoc.createAttribute("NewAttrName")
node2.Text = "Attribute value"
' Associate that attribute with an ELEMENT_NODE
Set node1 = currNode.Attributes.setNamedItem(node2)
Now currNode has a new attribute that looks like this: NewAttrName="Attribute value".
When you've added all your tags and attributes, you can save your .xml file back to disk using this method:
xDoc.save (destination)The X-Ray sample uses the IXMLDOMDocument getElementsByTagName() method to return a collection of nodes, in the form of an IXMLDOMNodeList, filtered by tag name. The getElementsByTagName method uses XSL patterns for queries, so you can either search by a tag name, such as "PRODUCT," or you may do scoped queries, such as "PRODUCT/FEATURES."
For example, if a node named "CLASS" was being used to describe both COMPANY and PRODUCT classes, a generic query for "CLASS" wouldn't suffice. Consider this example:
<?xml version="1.0"?>
<COMPANY>KomputerSource
<CLASS>Retail
<TYPE>Computer Store</TYPE>
</CLASS>
<PRODUCT>
<CLASS>Printer
<TYPE>dot matrix</TYPE>
</CLASS>
...
</PRODUCT>
</COMPANY>
Both the <COMPANY> and the <PRODUCT> contain <CLASS> elements. XSL pattern queries allow you to search for just the CLASS you want.
Armed with my trusty Internet Explorer 5 XML parser, I can share my data with others in a standard way. I can write generic applications that convert data into presentations. I can transform data into variable values for my server-side applications. I can even transform the data into different XML structures. XML is a meta-language that may be used for transferring data, but the real magic happens when the data contained inside the XML is morphed into something useful. That magic can happen in an Internet Explorer 5 browser or through an Internet Explorer 5 XML-enabled server-side application.
Steve Land is Senior Developer, Commerce Initiatives Lead at Corbis (www.corbis.com), where he develops commerce Web sites. His head is filled with metadata.