As companies begin to implement new Web-based information systems, data access technology must satisfy complex new scenarios. Whereas a previous generation of applications accessed data only on the mainframe, now developers building Web-based applications need access to data distributed throughout their organization — on different hardware platforms, different operating systems, and different data stores.
Valuable company information is available from a wide variety of sources and data stores, including those in the following list:
Each of these types of data may be needed by your enterprise application, yet each is in a different format, stored in a variety of data storage methods, and accessed in a fundamentally different way.
Wouldn't it be nice to have a common way to access data stored in different formats? This would mean you could use the same data access technology to access a relational database, a mainframe database, an Excel spreadsheet, and a text document.
As an application design issue, effectively using different data stores is more complicated than it appears. You must not only code different data access methods, but the many different data access application programming interfaces (APIs), COM interfaces, Automation interfaces, and procedural interfaces keep you from using transactions as a way to safely make changes. In this kind of situation, there is simply no way to package a transaction.
One solution is to put all of the different types of data into a single data store, such as a relational database. While this approach gives you a common data access method, it's unrealistic for a number of reasons. First, you must move huge amounts of data to the common database and rewrite all of the user tools to access data only at the common location. Second, each user would need training to use the new tools. Third, you probably don't own most of the data anyway, so arranging for ownership and control would be difficult. Fourth, a relational database — or any single data storage technology — is not the best way to deal with all types of data because the appropriate data structure depends on what the data is and how the data is used and managed.
If a single data store for all types of data isn't the answer, what's the alternative? The solution to accessing different kinds of data throughout the enterprise is to use OLE DB as a data provider and ActiveX® Data Objects (ADO) as the data access technology. Data access based on OLE DB and ADO is suitable for a wide range of application design requirements, from small single-workstation processes to large-scale Web applications.
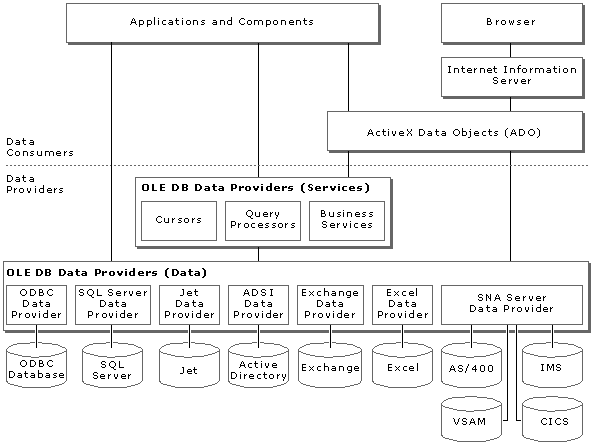
OLE DB is an extensive set of Component Object Model (COM) interfaces that can provide uniform access to data stored in diverse information sources. The interfaces, in turn, are enhanced to uniquely support the access functionality appropriate to each data source. The OLE DB interfaces allow an individual data store to easily expose its native functionality.
OLE DB is suitable for relational and nonrelational data sources, including mainframe VSAM and AS/400 files, data in CICS regions, IMS hierarchical databases, and many other data stores as shown in the following illustration.
OLE DB components consist of data providers that expose their data, data consumers that use data, and service components that process and transport data (such as query processors, cursor engines, and business services).
Because the OLE DB and ADO interfaces are based on COM, they support a rich set of integrated services (including transactions, security, and message queuing) to support the broadest range of application data access scenarios. This provides developers with a rich and consistent substrate of data access design functionality. The component methods, properties, and events are uniformly usable by all application development languages and Microsoft® Office products.
As an indication of how universal this approach is, the following list identifies all of the Microsoft scripting and application development languages that can use the COM-based OLE DB and ADO data access technologies.
It's worth noting that OLE DB with ADO provides a significant development cost and performance advantage over Open Database Connectivity (ODBC) in two ways. First, ODBC drivers have to implement an SQL relational engine to expose nonrelational data. Second, services such as cursors and query processing must be implemented by every ODBC driver. This represents development cost for the ODBC driver as well as resource consumption in the form of multiple cursor engines and query processors. With OLE DB, reusable service components handle the processing chores for a variety of data providers.
To integrate ODBC data with all other data types, Microsoft provides the OLE DB-ODBC data provider. This ensures continued support for the broad range of ODBC relational database drivers available today. You can access the data through OLE DB with the same performance that you would get if you accessed it through ODBC.
Your application will probably use ADO to talk to differing data stores through existing OLE DB providers, although you can use OLE DB interfaces directly if you choose. As a general rule, you won't need to develop custom OLE DB providers. However, if your enterprise application requires special data access not currently supported by an existing OLE DB provider, the best engineering choice is to write a custom data provider using OLE DB.
Note Because the OLE DB interfaces use pointers, structures, and explicit memory handling for optimizing how data is exposed and shared between components, they are not suitable for calling directly from Visual Basic or Visual J++ applications or components. Additionally, coding directly to the OLE DB interfaces entails a significant learning curve. As a general guideline, you should use ActiveX Data Objects (ADO) to access and manipulate OLE DB data stores.
By using OLE DB data providers with ADO, you can:
In general, the idea of universal data access is about an easily built, lower-cost application model using a consistent OLE DB with ADO data access approach that will work with all of a company's data sources.
Let's take a brief look at how OLE DB and ADO can be used to modernize an existing application. Suppose that your application accesses some data from a proprietary Indexed Sequential Access Method (ISAM) data store and also uses data from an Oracle relational database using Oracle's application programming interface (API). This application is hard to write, maintain, and extend due to the two proprietary interfaces and the code necessary to extend functionality not provided by the different types of data stores (such as ISAM's lack of a query processor). If your application now requires SQL Server data access, you must add a third interface.
The first step in adapting your application is to replace those proprietary APIs with OLE DB data providers and ActiveX Data Objects (ADO). You place an OLE DB data provider in front of each data store and use ADO to access the data with a common approach. The application is now simpler to write because it uses only one interface, and it's more versatile because it's easily extendable to other data stores.
At this point your application still has the original user interface and some business services. It still has the client cursor component because it is still talking to some types of data, like SQL data, that may not be able to support scrolling backwards, and the application still has a query processor for doing queries over HTML.
The next step is to add a query processor, which in this case is an OLE DB service component. When the application talks to a data provider that supports querying, such as a relational database, the application can talk directly to that SQL data through ADO. When the application talks to ISAM data, which doesn't have an SQL query processor, it still talks through ADO, but the new query processor is invoked on the application's behalf in order to implement the queries. That is important for a couple of reasons. Putting that query processor anywhere else would mean that every application would have to write its own query processor for every data store. As a general strategy, you can insert different query processors to support different query syntaxes or functionality.
Why not take the business services out of the application? Business services generally don't vary from application to application. Rather than re-creating similar business services in each separate application, you can implement them as reusable components. The model of OLE DB is that business services don't have to exist in the application. Rather, they can sit off to the side and, through notifications that OLE DB supports in order to coordinate different users, let other components know when certain designated events happen.
Congratulations! Your application's architecture has been upgraded to a modern, flexible, reusable collection of cooperating software components that is easily modified to support future data access requirements.