Ensuring the Availability of Applications and Services

Ensuring the Availability of Applications and Services |
|
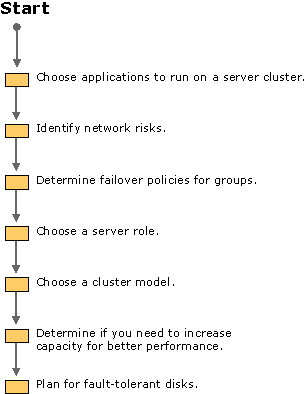
This section discusses guidelines to consider when you plan server clusters in your organization. Consider using the planning process depicted in Figure 18.7.
Figure 18.7 Process for Planning Your Server Clusters
You can deploy any application to run on any server that is in a cluster; however, not all applications fail over. Of those that can, not all need to be set up as cluster resources. This section offers guidelines for making these decisions.
The following criteria will help you determine whether an application can adapt to server clustering failover mechanisms:
Any application that runs on a server cluster must be able to store its data in a configurable location, that is, on the disks attached to shared disk buses. Some applications that cannot store their data in a configurable location can still be configured to fail over. In such cases, however, access to the application data is lost at failover because the data is available only on the disk of the failed node. Replication of this data between the nodes in the cluster might assist in this situation.
During failover, client applications experience a temporary loss of network connectivity. If you configure the client application to recover from temporary network connection problems, it can continue operating after a server failover.
You can divide applications that can fail over into two groups: those that use the Cluster API and those that do not.
Applications that support the Cluster API are defined as "cluster-aware." These applications can register with the Cluster service to receive status and notification information, and they can use the Cluster API to administer clusters.
Applications that do not support the Cluster API are defined as "cluster-unaware." If cluster-unaware applications meet the TCP/IP and remote storage criteria, you can still use them in a cluster and can often configure them to fail over.
In either case, applications that keep significant state information in memory are not the best applications for clustering because information not stored on disk is lost at failover. The outcome is similar to your restarting a server or the server suffering a power failure.
When you configure a cluster, identify the possible failures that can interrupt access to resources. Single points of failure can be hardware, software, or external dependencies, such as power supplied by a utility company and dedicated WAN lines.
In general, you provide maximum availability when you:
With Windows 2000 Advanced Server, you can use server clusters and new administrative procedures to provide increased availability. However, server clusters are not designed to protect all components of your workflow in all circumstances. For example, clusters are not an alternative to backing up data; they protect only the availability of data, not the data itself.
Windows 2000 Advanced Server has built-in features that protect certain computer and network processes during failure. These features include mirroring (RAID 1) and striping with parity (RAID 5). When planning your cluster, look for places where these features can help you in ways that server clusters cannot.

Note
Software RAID, offered by Logical Volume Manager in Windows 2000, cannot be used to protect disks managed by the Cluster service. Use hardware RAID to protect these disks.
To further increase the availability of network resources and prevent loss of data, consider the following:
A resource group is an association of dependent or related resources. Dependent resources require other resources in order to operate successfully. Individual resources cannot fail over independently. Resources fail over together with all other resources in the same resource group.
You assign failover policies for each group of resources in a cluster. Failover policies determine exactly how a group behaves when failover occurs. You can choose which policies are most appropriate for each resource group you set up.
Failover policies for groups include three settings:
You can set a group for immediate failover when a resource that is set to affect the group fails, or you can instruct the Cluster service to attempt to restart the failing resource a number of times before initiating a failover. If it is possible that the resource failure can be overcome by restarting all resources within the group, then set the Cluster service to restart the group.
You can set a group so that it always runs on a designated node whenever that node is available. This is useful if one of the nodes is better-equipped to host the group. Note that this setting only takes effect when failover occurs resulting from a node failure. Otherwise, you have to manually set the node that is hosting the resource group.
Failback is the process of moving resources, either individually or in a group, back to their preferred node after the node has failed and come back online.
You can configure for a group to failback to its preferred node as soon as the Cluster service detects that the failed node has been restored, or you can instruct the Cluster service to wait until a specified hour of the day, such as after peak business hours.
For more information about planning resource groups, see "Planning Your Resource Groups" later in this chapter.
Nodes in a server cluster can be member servers or domain controllers. However, in either case, both nodes must belong to the same domain.
If you configure your cluster nodes as domain controllers, you must first ensure that you have the hardware to support them. For more information, see "Determining Capacity Requirements for Cluster Service" later in this chapter.
If you configure all of the cluster nodes as member servers, then the availability of the cluster depends on the availability of the domain controller. The cluster is available only when the domain controller is available. Plan for sufficient domain controllers to provide the desired level of availability. For more information about increasing availability, see "Identifying Network Risks" earlier in this chapter.
You need to account for the additional overhead that is incurred by the domain controller services. In large networks running Windows 2000 Advanced Server, substantial resources can be required by domain controllers for performing directory replication and server authentication for clients. For this reason, many applications, such as SQL Server and Message Queuing, recommend that you do not install application on domain controllers for best performance. However, if you have a very small network in which account information rarely changes and in which users do not log on and off frequently, you can use domain controllers as cluster nodes.
Server clusters can be categorized in three configuration models in order of increasing complexity. This section describes each model and gives examples of the types of applications that are suited to each. These models range from a single node cluster to a cluster in which all servers are actively providing services. Choose the cluster model that best matches the needs of your organization.
Model 1 shows how you can use the virtual server concept with applications on a single node server cluster.
This cluster model does not make use of failover. It is merely a way to organize resources on a server for administrative convenience and for the convenience of your clients. The main advantage of this model is that both administrators and clients can readily see descriptively-named virtual servers on the network rather than having to navigate a list of actual servers to find the shares they need.
Other advantages of this model include:
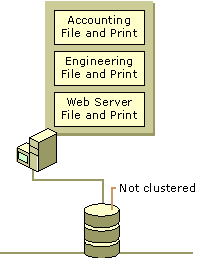
Figure 18.8 represents an example of a single node cluster that does not makes use of failover.
Figure 18.8 Single Node Server Cluster Configuration
For example, you can use this model to locate all the file and print resources in your organization on a single computer, establishing separate groups for each department. When clients from one department need to connect to the appropriate file or print share, they can find the share as easily as they would find an actual computer.
Note
Some applications, such as SQL Server versions 6.5 and 7.0, cannot be installed on a single node cluster.
Model 2 provides maximum availability and performance for your resources but requires an investment in hardware that is not in use most of the time.
One node, called a "primary node," supports all clients, while its companion node is idle. The companion node is a dedicated server that is ready to be used whenever a failover occurs on the primary node. If the primary node fails, the dedicated secondary node immediately picks up all operations and continues to service clients at a rate of performance that is close or equal to that of the primary node. This approach is often referred to as an active/passive configuration. The exact performance depends on the capacity of the secondary node. Figure 18.9 represents an example of the dedicated secondary node approach.
Figure 18.9 Active/Passive Configuration
Model 2 is best suited for the most important applications and resources in your organization. For example, if your organization relies on sales over the World Wide Web, you can use this model to provide secondary nodes for all servers dedicated to supporting Web access, such as those servers running Internet Information Services (IIS). The expense of doubling your hardware in this area is justified by the ability to protect client access to your organization. If one of your Web servers fail, another server is fully-configured to take over its operations.
If your budget allows for a secondary server with identical capacity to its primary node, then you do not need to set a preferred server for any of the groups. If one node has greater capacity than the other, setting the group failover policies to prefer the larger server keeps performance as high as possible.
If the secondary node has identical capacity to the primary node, set the policy to prevent failback for all groups. If the secondary node has less capacity than the primary node, set the policy for immediate failback or for failback at a specified off-peak hour.
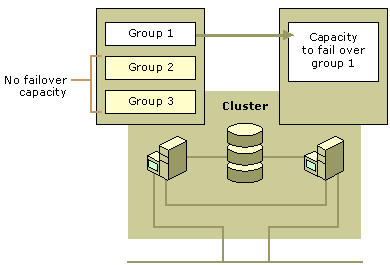
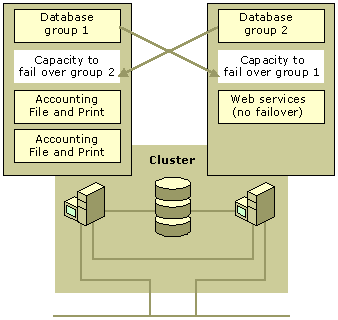
An active/passive split configuration represents one example of a dedicated secondary node. An active/passive split configuration demonstrates that nodes in a server cluster are not limited to providing applications that use clustering. Nodes that provide clustered resources can also provide applications that are not cluster-aware and that will fail if the server stops functioning.
One of the steps in planning resource groups is to identify applications that you will not configure to fail over. Those applications can reside on servers that form clusters, but they must store their data on local disks, not on disks on the shared bus. If high availability of these applications is important, you must find other methods of providing it. Figure 18.10 represents an example of an active/passive split configuration.
Figure 18.10 Active Passive Split Configuration
The applications in the other groups also serve clients on one of the servers, but because they are not cluster-aware, you do not establish failover policies for them. For example, you might use a node to run a mail server that has not been designed to use failover, or for an accounting application that you use so infrequently that availability is not important.
When node failure occurs, the applications that you did not configure with failover policies are unavailable unless they have built-in failover mechanisms of their own. They remain unavailable until the node on which they run is restored; you must either restart them manually or set Windows 2000 Advanced Server to automatically start them when the system software starts. The applications that you configured with failover policies fail over as usual according to those policies.
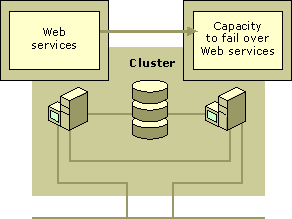
Model 3 provides reliability and acceptable performance when only one node is online, and high availability and performance when both nodes are online. This configuration allows maximum use of your hardware resources.
In this deployment example, each node makes its own set of resources available to the network in the form of virtual servers, which can be detected and accessed by clients. In a server cluster, a virtual server is a set of resources, including a Network Name resource and an IP Address resource, that are contained by a resource group. The capacity for each node is chosen so that the resources on each node run at optimum performance, but so that any node can temporarily take on the burden of running the resources if failover occurs. Depending on resource and server capacity specifications, all client services remain available during and after failover, but performance can decrease. Figure 18.11 represents an example of the active/active configuration.
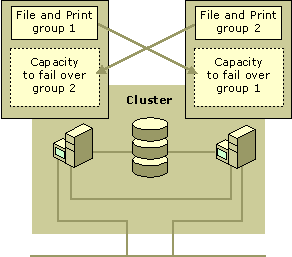
Figure 18.11 Active/Active Configuration
For example, you can use this configuration for a cluster dedicated to file-sharing and print-spooling services. Multiple file and print shares are established as separate groups, one on each node. If one node fails, the other nodes temporarily take on the file-sharing and print-spooling services for all nodes. The failover policy for the group that is temporarily relocated is set to prefer its original node. When the failed node is restored, the relocated group returns to the control of its preferred node, and operations resume at normal performance. Services are available to clients throughout the process with only minor interruption.
The following deployment examples represent a few types of high-availability configurations
This example demonstrates how you can solve two challenges that typically occur in a large computing environment. The first challenge occurs when a single server is running multiple large applications, causing a degradation in network performance. To solve the problem, you cluster one or more servers with the first server, and the applications are split across the servers.
The second challenge involves related applications running on separate servers. The problem of availability arises when servers are not connected. By placing them in a cluster, the client is ensured greater availability of both applications.
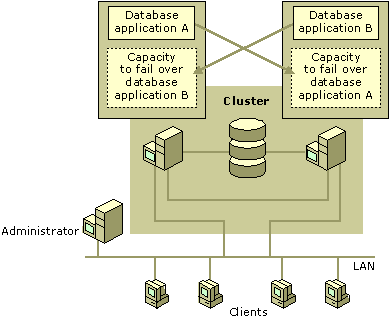
Suppose your corporate intranet relies on a server that runs two large database applications. Both of these databases are critical to hundreds of users who repeatedly connect to this server throughout the day. The challenge is that during peak connect times, the server cannot keep up with demand and performance often declines.
You can alleviate the problem by attaching a second server to the overloaded server, forming a cluster, and balancing the load. You now have multiple servers, each running one of the database applications. If one server fails, you might experience degraded performance, but only temporarily. When the failed server is restored, the application it was running fails back and operations resume. Figure 18.12 represents the solution.
Figure 18.12 Attach Another Server to Your Overloaded Server to Form a Cluster
Suppose your retail business relies on two separate servers, one that provides messaging services and another that provides a database application for inventory and ordering information.
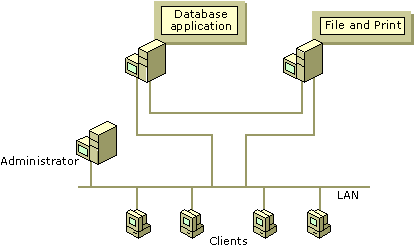
Both of these services are essential to your business. Employees rely on messaging services to conduct business on a daily basis. Without access to the database application, customers cannot place orders, and employees cannot access inventory or shipping information. Figure 18.13 shows a typical configuration when mission-critical applications and services rely on separate servers, thus putting the applications and services at risk.
Figure 18.13 Relying on Separate Servers for Mission-Critical Applications and Services
To ensure the availability of all services, you join the computers into a cluster.
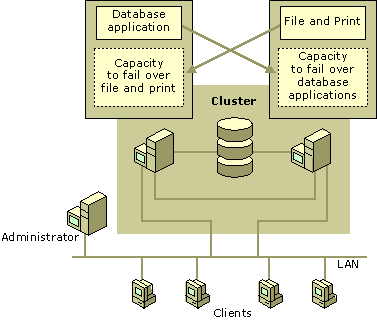
You create a cluster that contains two groups, one on each node. One group contains all of the resources needed to run the messaging applications, and the other group contains all of the resources for the database application, including the database. Figure 18.14 represents a solution that ensures the availability of applications in this case.
Figure 18.14 Clustering Multiple Applications
In the failover policies of each group, specify that both groups can run on either node, thereby assuring their availability if one node fails.
In Windows 2000 Advanced Server, the Cluster service detects loss of connectivity between the servers and client systems. If the Cluster service software can isolate the problem to a specific server, the Cluster service declares a failure of the network and fail dependent groups over to the other server (by means of the functioning networks).
The complex hybrid configuration is a hybrid of the other models. The hybrid configuration allows you to incorporate the advantages of previous models and combine them into one cluster. As long as you have provided sufficient capacity, many types of failover scenarios can coexist on all the nodes. All failover activity occurs as normal, according to the policies you set up. Figure 18.15 represents an example of multiple database shares, allowing somewhat reduced performance when the shares are on a single node.
Figure 18.15 The Complex Hybrid Configuration
For administrative convenience, the file-and-print shares in the cluster (which do not require failover ability) are grouped logically by department and configured as virtual servers. Finally, an application that cannot fail over resides on one of the clusters and operates as normal (without any failover protection).
After you assess your clustering needs, you are ready to determine how many servers you need and with what specifications, such as how much memory and hard disk storage.
Because all resources in a group move between nodes as a unit, dependent resources never span a single group boundary (resources cannot be dependent on resources in other groups).
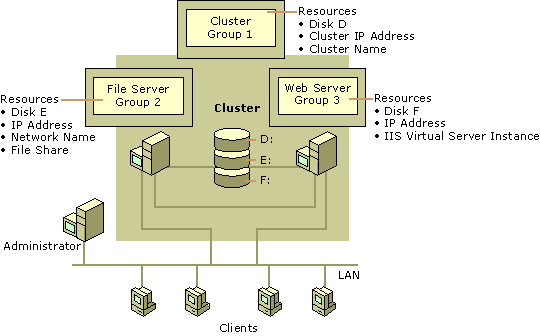
Figure 18.16 shows how dependent resources are joined to form a group. The node on the right contains the Web Server group, which is made up of four resources on which IIS depends: a Network Name, an IP Address, an IIS Virtual Service, and Disk E.
Figure 18.16 A Group of Dependent Resources
Typical clusters include one group for each independent application or service that runs on the cluster. Typical cluster groups contain the following types of resources:
There are six steps you can take to organize your applications and other resources into groups:
Most groups contain one or more applications. Make a list of all applications in your environment, regardless of whether you plan to use them with the Cluster service. Determine your total capacity requirements by adding the total number of groups (virtual servers) you plan to run in your environment together with the total amount of software you plan to run independently of groups.
Also list applications that will reside on cluster nodes but which will not use the failover feature, because it is inconvenient, unnecessary, or impossible to configure the applications for failover. Although you do not set failover policies for these applications or arrange them in groups, they still use a portion of the server capacity.
Before clustering an application, review the application license, or check with the application vendor. Each application vendor sets its own licensing policies for applications running on clusters.
Determine which hardware, connections, and operating system software a server cluster can protect in your network environment.
For example, the Cluster service can fail over print spoolers to protect client access to printing services. Another example is a file server resource, which you can set to fail over so that you maintain client access to files. In both cases, capacity is affected, such as the RAM required to service the clients when failover occurs.
Cluster service maintains a hierarchy of resource dependencies to guarantee that all resources on which a particular application depends are brought online before the application. It also guarantees that the application and all the resources it depends on will either restart or fail over to another node if one of these resources fails.
Create a list of dependencies to help you determine how your resources and resource groups depend on each other and the optimal distribution of resources among all groups. Include all resources that support the core resources. For example, if a Web server application fails over, the Web addresses and disks on the shared buses containing the files for that application must also fail over if the Web server is to function. All these resources must be in the same group. This ensures that the Cluster service keeps interdependent resources together at all times.
Note
When grouping resources, remember that a resource and its dependencies must be together in a single group because a resource cannot span groups.
Remember that a resource group is a basic unit of failover. Individual resources cannot fail over independently. Resources fail over together with all other resources in the same resource group.
Because most applications store application data on disk, it is recommended that you create a resource group for each disk. Place one application, together with all the other resources on which it depends, in the group containing the disk on which it stores its data. Place another application in another group, along with its disk. This configuration allows applications to fail over or be moved independently without affecting other applications.
Another reason to assign applications to a single group is for administrative convenience. For example, you might put several applications into one group because viewing those particular applications as a single entity makes it easier to administer the network.
A common use of this technique is to combine file-sharing resources and print-spooling resources in a single group. If you combine these resources, all dependencies for those applications must also be in the same group. You can give this group a unique name for the part of your organization it serves, such as AccountingFile&Print. Whenever you need to intervene with the file-sharing and print-sharing activities for that department, you would look for this group in Cluster Administrator.
Another common practice is to put applications that depend on a particular resource into a single group. For example, suppose that a Web server application provides access to Web pages and that those Web pages provide result sets that clients access by querying an SQL database application. (Querying occurs through the use of Hypertext Markup Language [HTML] forms.) By putting the Web server and the SQL database in the same group, the data for both core applications can reside on a specific disk volume. Because both applications exist within the same group, you can also create an IP address and network name specifically for this resource group.
After you group your resources together, assign a different name to each group, and create a dependency tree. A dependency tree is useful for visualizing the dependency relationships between resources.
To create a dependency tree, write down all the resources in a particular group. Then draw arrows from each resource to each resource on which the resource directly depends.
For example, a direct dependency between resource A and resource B means that there are no intermediary resources between the two resources. An indirect dependency occurs when a transitive relationship exists between resources. If resource A depends on resource B and resource B depends on resource C, there is an indirect dependency between resource A and resource C. However, resource A is not directly dependent on resource C.
In the Web Server group of Figure 18.16, both the Network Name resource and the IIS Virtual Server Instance resource depend on the IP Address resource. However, there is no dependency between the Network Name resource and the IIS Virtual Server Instance resource.
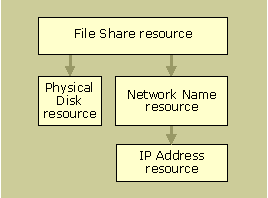
Figure 18.17 illustrates a simple dependency tree that shows some resources in a final grouping assignment.
Figure 18.17 A Simple Dependency Tree
In Figure 18.17, the File Share resource depends on the Network Name resource, which, in turn, depends on the IP Address resource. However, the File Share resource does not directly depend on the IP Address resource.
Note
Physical disks do not depend on any other resource and they can fail over independently.
You are ready to determine your hardware capacity requirements for each server in the cluster after you have done the following:
The paragraphs that follow suggest criteria to help you determine hardware requirements for the computers that you use as cluster nodes.
Hard Disk Storage Requirements Each node in a cluster must have enough hard disk capacity to store permanent copies of all applications and other resources required to run all groups. Calculate this for each node as if all of these resources in the cluster were running on that node, even if some or all of those groups run on the other node most of the time. Plan these disk-space allowances so that any other node can efficiently run all resources during failover.
Note
Cluster service does not support dynamic disks and the new features offered by the Logical Volume Manager. Particularly, the NTFS file system partitions on a disk managed by a cluster service cannot be extended. You need to plan the disk capacity and provide enough room for growth.
CPU Requirements Failover can strain the CPU processing capacity of a node when it takes control of the resources from a failed node. Without proper planning, the CPU of a surviving node can be pushed beyond its practical capacity during failover, slowing response time for users. Plan your CPU capacity on each node so that it can accommodate new resources without unreasonably affecting responsiveness.
RAM Requirements When planning your capacity, make sure that each node in your cluster has enough RAM to run all applications that might run on any other node. Also, make sure you set your Windows 2000 Advanced Server paging files appropriately for the amount of RAM you define for each node.
Some important limitations of Windows 2000 Server clusters are as follows.
You can use Terminal Services for remote administration on a server cluster node. You cannot use Terminal Services for an application server on a server cluster node.

Important
You cannot currently use Network Load Balancing and Cluster service on the same server.