Active Directory Replication

Active Directory Replication |
|
Although replication within sites is optimized for LAN connectivity and requires little or no management, you have control over when and how replication between sites occurs. You want to maximize efficiency and minimize cost, and there are decisions that must be made on the basis of your network environment, physical location, and business needs. The KCC generates the intersite topology automatically, but the settings on the site links are the factors that the KCC considers in the process.
When multiple sites participate in the replication topology of domain controllers in the same forest, the default intersite topology is a least-cost spanning tree, where "cost" is administratively set to favor various routes. Replication between sites can occur synchronously by RPC over IP transport or asynchronously by SMTP over IP transport.

Note
A spanning tree algorithm is applied to network connections to eliminate redundant routes and thereby reduce consumption of expensive WAN network bandwidth.
Replication within sites requires little or no planning because it is fully automatic. However, when you have multiple sites, the following steps can be used to plan how replication occurs between them:
Avoid high-frequency times. Site links must have windows of time in common that are available for routing.
For information about planning sites and site topology for Active Directory, see "Designing the Active Directory Structure" in the Deployment Planning Guide.
Connection objects are created automatically by the KCC for replication both within a site and between sites. For connection objects to be created between two sites, however, you must manually create a link that connects the two sites. These links, implemented through site link objects in Active Directory, identify the transport protocol and scheduling required to replicate between two sites. Administrators use Active Directory Sites and Services to create the site links, and the KCC creates the connections accordingly when it generates the intersite topology.
Site link objects can be created in two transport-specific containers within the Inter-Site Transports container in Active Directory Sites and Services. By creating the link in one or the other container, you associate the link with the respective replication transport. The Inter-Site Transports container is a child of the Sites container, and it also has child containers:
When the KCC configures the connection objects for replication between sites, it takes the settings on the site link object into account to create the best connection. For example, one of the site link settings is the cost of the connection. When it has a choice, the KCC chooses a remote site whose link has the lowest cost when it forms connections.
For IP transport, a typical site link connects only two sites and corresponds to an actual WAN link. An IP site link connecting more than two sites might correspond to an ATM backbone that connects, for example, more than two clusters of buildings on a large campus or connects several offices in a large metropolitan area that are connected by leased lines and IP routers.
A site can be connected to other sites by any number of site link objects. Each site in a multi-site directory must be connected by at least one site link. Otherwise, it cannot replicate with domain controllers in any other site, so the directory is disconnected. Therefore, if there is more than one site in the forest, you must configure at least one site link.
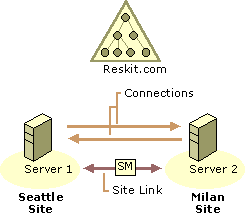
Figure 6.6 shows two sites that are connected by one site link. A single domain has domain controllers in both sites. When topology generation occurs, connection objects between bridgehead servers in the site are created by the KCC and replication occurs according to the settings on the site link.
Figure 6.6 Two Sites That Are Connected by a Site Link
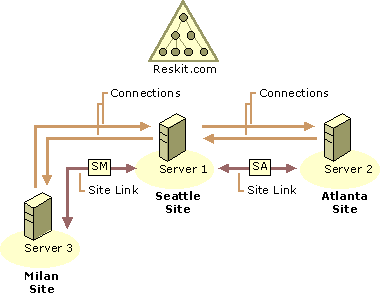
Figure 6.7 shows three sites connected by two site links. By default, site links are transitive. Therefore, replication messages can flow from the Atlanta site, through the Seattle site, and on to the Milan site. In this scenario, because the Seattle site contains a full replica of reskit.com, there is no need for direct replication between Milan and Atlanta; all replication between them is transitive through the Seattle site.
Figure 6.7 Three Sites That Are Connected by Two Site Links
In Active Directory Sites and Services, the General tab in the Site Link Properties dialog box contains the following options for configuring site links to control the replication topology:
Note
Scheduling information is ignored by site links that use SMTP transports; the mail is stockpiled and then exchanged at the times that are configured for your mail infrastructure.
The site link settings let you control replication topology and timing independently:
You assign cost values to site links to favor inexpensive connections over expensive connections. The costs of providing bandwidth is a factor that is to be taken into account when you define site boundaries; it is recommended that these costs be defined on a sitewide basis. Cost is usually based not only on the total bandwidth of the link but also on the availability, latency, and monetary cost of the link.
For example, a
Table 6.2 shows the speeds for different types of networks; you can use these network speeds to estimate cost.
Table 6.2 Network Speeds for Estimating Cost
| Network Type | Speed |
|---|---|
| Very slow | 56 Kbps |
| Slow (typical in Europe) | 64 Kbps |
| ISDN | 64 Kbps or 128 Kbps |
| Frame relay | Variable rate, commonly between 56 Kbps and 1.5 megabits per second (Mbps) |
| T1 | 1.5 Mbps |
| T3 | 45 Mbps |
| Asynchronous Transfer Mode (ATM) | Variable rate, commonly between 155 Mbps and 622 Mbps |
| Gigabit Ethernet | 1 gigabit per second (Gbps) |
Before you assign any costs, define a model for your WAN. On the basis of the cost plus other factors (availability and replication latency), you can establish a set of costs that can be implemented throughout the forest. Where a cost is assigned, it must always mean the same thing in any other place where the same cost is assigned. Table 6.3. shows an example of the cost breakdown in a forest for a network where a high speed has a lower cost.
Table 6.3 Example of Cost Breakdown for a Forest on a High-Speed Network
| Network Type | Cost Value |
|---|---|
| T1 to backbone | 1 |
| 500 | |
| Branch office | 1,000 |
| International link | 5,000 |
The Cost setting on a site link provides a relative value for the cost of communication between all sites that are part of the link. (By default, site link settings are transitive between the sites that they connect.) For example, if you create an IP site link object XYZ that connects the sites X, Y, and Z with cost 5, you establish that an IP message can be sent between all pairs of sites (X to Y, X to Z, Y to X, Y to Z, Z to X, Z to Y) with cost 5.
Note
By default, all site links are transitive; that is, all site links for a specific transport implicitly belong to a single site link bridge for that transport. (For information about site link bridges, see "Site Link Bridges" later in this chapter.) If your IP network is not fully routed, you can turn off the transitive site link feature for the IP transport, in which case all IP site links are considered nontransitive and you can configure site link bridges.
The KCC determines the least-cost path from each site to every other site for each directory partition. The KCC then reviews the comparison of multiple paths to and from every destination and computes the spanning tree of the least-cost path.
For information about IP routing, see "Determining Network Connectivity Strategies" in the Deployment Planning Guide.
For each site link object, you can specify a value for the replication period, which determines how often replication occurs over the site link during the time that the schedule allows. For example, if the schedule allows replication between 02:00 hours and 04:00 hours, and the replication period is set for 30 minutes, replication can occur up to four times during the scheduled time.
The default replication period is 180 minutes, or 3 hours. When the KCC creates a connection between a domain controller in one site and a domain controller in another site, the replication period of the connection is the maximum period along the minimum-cost path of site link objects from one end of the connection to the other.
In the case of RPC transport between sites, the replication between sites can be scheduled. Site links are associated with a schedule, which opens one or many windows for when replication can occur. If replication goes through multiple site links, there must be at least one common window; otherwise, the connection is treated as not available. For example, if site link 1 has a schedule (window of opportunity) of 18:00 hours to 24:00 hours and site link 2 has a schedule (window of opportunity) of 17:00 hours to 20:00 hours, the resulting window of opportunity is 18:00 hours through 20:00 hours, which is the intersection of site link 1 and site link 2.
The path that replication takes between sites is computed from the information on the site link objects. When a change is made to a site link setting, the following events must occur before the change takes effect:
As the path of connections is transitively figured through a set of site links, the attributes (settings) of the site link objects are "aggregated" along the path as follows:
Note
Options are the values of the options attribute on the site link object. The value of this attribute determines special behavior of the site link, such as reciprocal replication and intersite change notification. (For more information about these behaviors, see "Reciprocal Replication" and "Change Notification" later in this chapter.)
Thus the site link schedule is the "overlap" of all of the schedules of the subpaths. If none of the schedules overlap, the path is not used.
The schedule determines the time intervals during which the site link is available, and the replication period determines how often replication can occur during those intervals. The interaction of these factors determines the replication latency. For sites where the maximum replication period within the site is 15 minutes, the worst-case, end-to-end replication latency from a source domain controller to a destination domain controller in a remote site is the sum of the replication period settings for the connections between the source and destination sites, plus 15 minutes for each site in the path (including the source and destination sites). This sum assumes that the RPC transport is used between sites and that the required physical connections are available.
When multiple site links are required to complete replication for all sites, the replication periods on each link combine to affect the entire length of the connection between sites. In addition, when schedules on each link do not coincide, replication can occur only during the window of opportunity where the schedules intersect.
Suppose that site A and site B have site link AB, and site B and site C have site link BC. When a domain controller in site A replicates with a domain controller in site C, it can do so only as often as the maximum period set for site link AB and site link BC allow. Table 6.4 shows the site link settings that determine how often and during what times replication can occur between domain controllers in site A, site B, and site C.
Table 6.4 Replication Period and Schedule Settings for Two Site Links
| Site Link | Replication Period | Schedule |
|---|---|---|
| AB | 30 minutes | 12:00 hours to 04:00 hours |
| BC | 60 minutes | 01:00 hours to 05:00 hours |
Given the settings in Table 6.4, a domain controller in domain A can replicate with a domain controller in site B according to the AB site link schedule and period, which is once every 30 minutes between the hours of 12:00 and 04:00. However, assuming that there is no site link AC, a domain controller in site A can replicate with a domain controller in site C once every 60 minutes, which is the greater of the two replication periods, and between the hours of 01:00 and 04:00, which is where the schedules on the two site links intersect.
The times that you can set in the Schedule setting on the site link are in one-hour increments. For example, you can schedule replication to occur between 00:00 hours and 01:00 hours, between 01:00 hours and 02:00 hours, and so forth. However, each block in the actual connection schedule is 15 minutes. For this reason, when you set a schedule of 01:00 hours to 02:00 hours, you can assume that replication is queued at some point between 01:00 hours and 01:14:59 hours.
Note
RPC synchronous inbound replication is serialized so that if the server is busy replicating this directory partition from another source, replication from a different source does not begin until the first synchronization is complete. SMTP results are processed serially by order of arrival.
Specifically, a replication event is queued at time t + n, where t is the replication period that is applied across the schedule and n is a pseudo-random number between 1 minute and 15 minutes, inclusive. For example, if the site link indicates that replication can take place between 02:00 hours and 07:00 hours (inclusive), and the replication period is 2 hours (120 minutes), t is 02:00 hours, 04:00 hours, and 06:00 hours. A replication event is queued between 02:00 hours and 02:14:59 hours, and another replication event is queued between 04:00 hours and 04:14:59 hours. Assuming that the first replication event that was queued is complete, another replication event is queued between 06:00 hours and 06:14:59 hours. If the synchronization took longer than two hours, the second synchronization would be ignored because there is already an event in the queue.
Note
The replication queue is shared with other events, and the time at which replication takes place is approximate. Duplicate replication events are not queued for the same directory partition and transport.
For information about how to create and configure site links, see Windows 2000 Server Help.
Bridgehead servers must be able to accommodate more replication traffic than non-bridgehead servers, and you might want to choose which servers are to carry out this task. Knowing which system is acting as a bridgehead also can be useful for troubleshooting.
When you manually configure a single domain controller as the bridgehead server for a site, the KCC uses only that server. When multiple domain controllers in a site are configured to be preferred bridgehead servers, the KCC ultimately selects one of these servers on the basis on other variables.
Depending on what transports are available, which directory partitions must be replicated, and the availability of Global Catalog servers, multiple bridgehead servers might be required to replicate full copies of data from one site to another.
Suppose that there are two sites, site A and site B, and each site has a single domain controller from each of two domains, domain X and domain Y. In this case, the only way that replication of the respective domain directory partitions can occur between the two sites is if the domain controllers for domain X and domain Y are selected as bridgehead servers in each site. Therefore, if there is a single domain controller for a specific domain in a specific site, that domain controller must be a bridgehead server in its site because it can replicate domain data to only a domain controller in its own domain. In addition, that single domain controller must be able to connect to a bridgehead server in the alternative site that also holds the same domain directory partition.
If you want the KCC to consider certain domain controllers over others as bridgehead servers, you can specify a domain controller and an associated transport to indicate this preference by using the server object properties in Active Directory Sites and Services.
You specify the server when you select its server object, and then you add each transport for which the selected domain controller is a preferred bridgehead (IP for RPC over IP, or SMTP for SMTP over IP). If you select more than one server for a specific transport that can replicate a particular domain directory partition, the KCC chooses one arbitrarily. For information about how to specify preferred bridgehead servers, see Windows 2000 Server Help.
When a bridgehead server goes down, potentially it can cut off replication between this site and the other site. In most cases, the KCC selects a different bridgehead server automatically.
Unless you specify a preferred bridgehead server or servers, the KCC selects them automatically. When the KCC selects bridgehead servers automatically and the current bridgehead server fails, after a time interval (the point at which a failure has occurred and the time since the last successful replication is greater than 2 hours), the KCC selects another bridgehead server to take its place. If all potential bridgehead servers are unavailable, the KCC logs an event that describes the condition.
If you explicitly set a preferred bridgehead server or servers and none is available, the KCC does not select alternative bridgehead servers automatically. In this case, the KCC logs an error message that states that you have designated preferred bridgehead servers that can replicate a specific directory partition, but none of them is available.
If you want the KCC to be able to fail over to other domain controllers but there are no other preferred bridgehead servers available, you must do one of the following at a domain controller in each site:

Important
The KCC creates only inbound connections. A bridgehead server cannot create an outbound connection to another bridgehead server. For this reason, unless there is already a functioning replication path to the other site, changes to preferred bridgehead server status must be made on a domain controller in each affected site so that inbound connections are created in each site.
If the only preferred bridgehead server that is available for a specific directory partition and transport fails and you want to assign a new bridgehead server to replace it, you must add the new bridgehead server twice — once on a domain controller in the site of the failed bridgehead server, and once on a domain controller in the site on the other end of the affected site link. This process might involve two administrators if the site locations are far away from each other.
Note
If there are preferred bridgehead servers available and you want to add another preferred bridgehead server in the site, you do not have to add the server in both sites because the change replicates to the other site through the currently available bridgehead servers.
If you remove all preferred bridgehead servers so that the KCC can select bridgehead servers automatically, you must remove them for each domain directory partition and for each transport on a domain controller in each affected site.
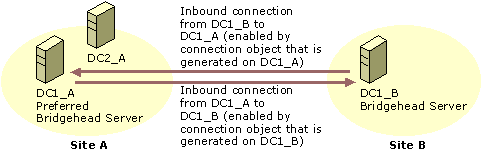
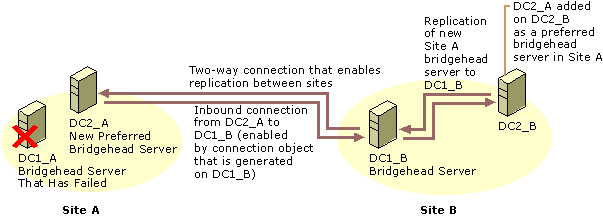
Figure 6.8 shows the connections between bridgehead servers in two sites. The bridgehead server in site A is a preferred bridgehead server.
Figure 6.8 Two Sites and Two Bridgehead Servers with Inbound Connections from Each Other
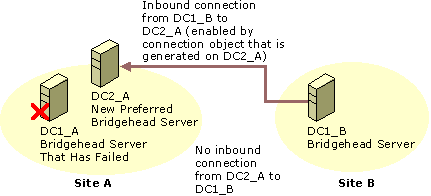
If the preferred bridgehead server in site A fails, the bridgehead server in site B loses its inbound connection from the failed server and, thus, is disconnected from the site. If you assign a server to replace the failed bridgehead server in site A, the new bridgehead server creates only inbound connections. This change cannot replicate to site B because there is no inbound connection at the bridgehead server in site B. Figure 6.9 shows the connection that is created when you add a new bridgehead server in site A.
Figure 6.9 New Inbound Connection from the Existing Server with No Inbound Connection from the New Bridgehead Server
Until you add the new site A bridgehead server to a domain controller in site B, there is no inbound connection possible from site A to site B, even though you have added the bridgehead server in site A. The reason is that the KCC creates only inbound connections and has no knowledge of the new server.
In Figure 6.10, the new bridgehead server for site A has been added to a domain controller in site B. The figure shows the new inbound connection that results. The sequence of events is as follows:
Figure 6.10 Two-Way Connection Between Sites After Adding the New Site A Bridgehead Server in Site B
If you have configured preferred bridgehead servers but none of them is capable of replicating a directory partition that must be replicated, the KCC logs an event for a configuration error. (A domain that has servers in the site is not represented by a bridgehead server.) The KCC then proceeds to select an alternative in the same manner as if no preferred bridgehead servers are configured.
A site link bridge object represents a set of site links, all of whose sites can communicate through some transport. A site link bridge usually corresponds to a router (or a set of routers) in an IP network.
Note
If no bridgehead server that is capable of the site link bridge transport is available in two linked sites, a route is not available.
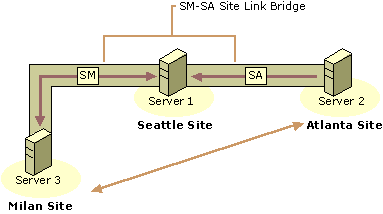
By default, all site links that you create are bridged ("transitive"); all site links for a specific transport implicitly belong to a single site link bridge for that transport. Therefore, in the common case of a fully routed IP network, you do not need to configure any site link bridges. Figure 6.11 shows a case where three sites are connected by two site links and the site link bridge allows connections to be created between two sites that are not connected by an explicit site link.
Figure 6.11 Site Link Bridge That Enables Connections Between Milan and Atlanta Sites
If your IP network is not fully routed, you can turn off the Bridge all site links for IP transport (on the General tab in the IP transport object property sheet or SMTP transport object property sheet). In this case, all IP site links are considered nontransitive, and you can configure site link bridges to model the actual routing behavior of your network.
You create a site link bridge object for a specific transport by specifying two or more site links for the specified transport.
To understand what a site link bridge means, consider the following example:
In this simple example, the site link bridge
Each site link in a bridge must have at least one site in common with another site link in the bridge. Otherwise, the bridge cannot compute the cost from sites in one link to the sites in other links of the bridge. For example, if you have four sites (W, X, Y, and Z), a site link WX that connects W and X, and a site link YZ that connects Y and Z, a site link bridge that connects WX and YZ serves no purpose.
Separate site link bridges, even for the same transport, are independent. To illustrate this independence, the following objects are added to the Milan-Seattle-Atlanta example:
The presence of this additional bridge means that an IP message can be sent from the Seattle site to the Detroit site with cost 2 + 3 = 5; but it does not imply that an IP message can be sent from the Detroit site to the Milan site with cost 2 + 3 + 4 = 9. In almost all cases, you use a single site link bridge to model the entire IP network.
Any network that you can describe by a combination of site links and site link bridges also can be described by site links alone. The advantage to bridging all site links is that your network description is much smaller and easier to maintain because you don't need a site link to describe every possible path between pairs of sites.
However, when the number of sites exceeds 200, periods of high CPU activity occur every 15 minutes when the KCC runs. The Bridge all site links setting creates a single bridge for the entire network, which generates more routes that must be processed than if site link bridges are not used or are applied selectively.
For example, under the conditions identified in Figure 6.11, the following factors affect KCC performance:
Thus, in a large network where processing time is a concern, there are performance advantages to turning off Bridge all site links and configuring site link bridges only where they are advantageous. If you still experience delays, the next step is to replace the bridges with a large number of sites that have explicit site links. For more information about KCC scaling recommendations, see the Microsoft Knowledge Base link on the Web Resources page at http://windows.microsoft.com/windows2000/reskit/webresources. Search the Knowledge Base by using the keyword "Q244368."
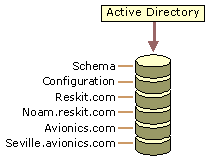
A Global Catalog server is a domain controller that stores specific information about all objects in the forest. The Global Catalog is required for the logon process, so it is best to have at least one Global Catalog server per site. The Global Catalog stores a replica of every directory partition in the forest: It stores full replicas of the schema and configuration directory partitions, a full replica of the domain directory partition for which the domain controller is authoritative, and partial replicas of all other domain directory partitions in the forest. When an attributeSchema object has the isMemberOfPartialAttributeSet attribute set to TRUE, the attribute is replicated from the domain directory partition to the corresponding directory partition replicas on all authoritative domain controllers and also to all Global Catalog servers.
Figure 6.12 depicts logical directory partitions in the Active Directory database of a Global Catalog server. (The database itself, Ntds.dit, is not actually partitioned.) The top three segments represent directory partitions that are full replicas for the domain controller. The bottom three segments represent directory partitions that are partial replicas for the Global Catalog.
Figure 6.12 Directory Database on a Domain Controller That Is a Global Catalog
Global Catalog servers request updates from a source domain controller for each domain directory partition in the forest. This source domain controller can be either a normal domain controller or another Global Catalog server.
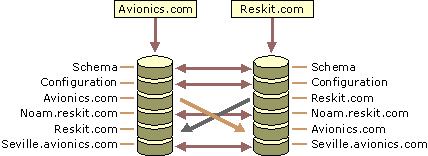
Figure 6.13 shows the partner associations between directory partitions in two Global Catalog servers that are authoritative domain controllers for different domains. As is true for all domain controllers, the Global Catalog uses a single topology to replicate the schema and configuration directory partitions, and it uses a separate topology for each domain directory partition. Replication is two-way between the domain directory partitions.
One server is authoritative for avionics.com; the other server is authoritative for reskit.com. As such, the avionics.com domain controller can be the source for replication to the partial replica of avionics.com on the reskit.com Global Catalog server, and the reskit.com domain controller can be the source for replication to the partial replica of reskit.com on the avionics.com Global Catalog server. The connection arrows indicate the one-way flow of replication from the read-write sources to the read-only destinations. In the case of the noam.reskit.com domain, neither domain controller is authoritative for that domain, so the Global Catalog servers replicate these partial replicas to and from each other.
Figure 6.13 Directory Partition Connections Between Two Global Catalog Servers in Different Domains
When you want to remove an attribute from the Global Catalog, you must set its isMemberOfPartialAttributeSet value to FALSE. The attribute then is removed from the Global Catalog immediately after the next replication cycle.
If an attribute has been added to the partial attribute set, the domain controller must replicate the value of this attribute for each of its partial directory partition replica objects. This is accomplished by performing a full synchronization across all of the Global Catalog's replication connections. If the partial directory partition replica can be synchronized over an RPC connection, the domain controller attempts a full synchronization over an RPC connection before it uses any other connections; if full synchronization is completed, the up-to-dateness vector that it creates optimizes later full synchronization on other connections.

Caution
Caution should be exercised when you add attributes to the Global Catalog attribute set because doing so causes full synchronization of the Global Catalog on all Global Catalog servers in the forest. Although interruption of service does not occur, this replication causes higher bandwidth consumption than is required for usual day-to-day replication. The resulting bandwidth consumption for each Global Catalog server is equivalent to that caused by promoting a regular domain controller to the role of Global Catalog server.
A universal group can have members from any domain in the forest, and thus the membership for universal groups cannot be stored on every domain controller (each domain controller stores objects for only one domain), but only on Global Catalog servers, which store every object in the forest. Therefore, the Global Catalog servers are the only domain controllers that can enumerate the membership of a universal group. For this reason, a Global Catalog server is required for logging on to domains that use universal groups. During the logon process, the Global Catalog enumerates the membership of universal groups and attaches any found membership to the security token of the user. Other types of groups (global and local) are not enumerated by the Global Catalog; only the group object name is listed. The enumeration of global and local groups is the responsibility of the resource domain controller. For replication, this arrangement means that the replication of global and local group memberships is not required by Global Catalog servers, which significantly reduces replication traffic.
The following scenarios combine different approaches to using site links and site link bridges.
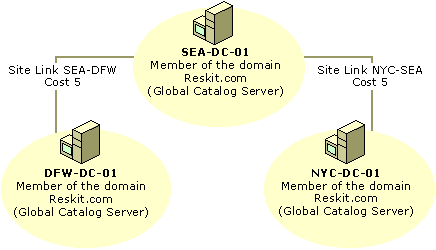
In Figure 6.14, two site links have been defined, NYC-SEA and SEA-DFW. In this environment, the default behavior of transitive site links has been disabled because the network is not fully routed, so there is no site link bridge. For this reason, the KCC can create connections only between NYC and SEA and between SEA and DFW. Because all domain controllers are in the same domain and therefore maintain a full copy of the same domain directory partition, replication can occur through the hub site SEA without requiring a connection between DFW and NYC. As a change occurs in NYC, this change (in its entirety) is replicated to SEA. Because domain controllers that are holding full domain directory partition replicas can replicate inbound changes from only another full domain replica,
Figure 6.14 A Single Domain in Three Sites Connected by Nontransitive Site Links
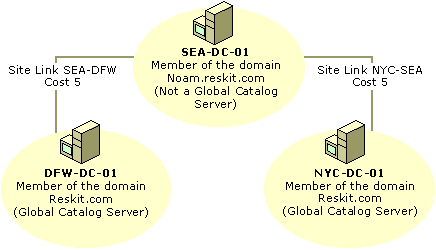
Figure 6.15 shows that the SEA site contains a domain controller for the noam.reskit.com domain but not for the reskit.com domain. In this case, how would changes replicate from NYC to DFW?
If transitive site links were enabled or if a site link bridge were created manually between NYC-SEA and SEA-DFW, the KCC could create a connection object to replicate data between DFW and NYC. If neither condition were true,
Figure 6.15 Site Links Between Three Sites for Two Domains
In Figure 6.15, if
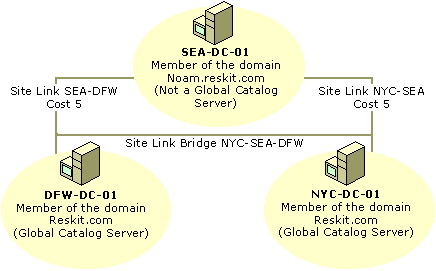
In Figure 6.16, with transitive site links disabled, adding a site link bridge that contains DFW-SEA and SEA-NYC changes the rules on the possible replication partners that the KCC can select. The bridge gives the KCC a route from DFW to NYC in which to create a connection object that allows replication to occur, even if no domain controller for the same domain directory partition exists in SEA. Schema and configuration changes can be replicated over this connection.
Figure 6.16 Site Link Bridge That Connects SEA-DFW and SEA-NYC
By default, all site links are defined as transitive and do not require definitions of site link bridges. Without a site link bridge, the KCC still constructs connection objects between sites such that replication is the most efficient, based on the defined costs for each site link. However, with a site link bridge, the connection objects might reflect a direct connection from a domain controller in one site to a domain controller in another site where there is no site link.
For information about network routing, see "Unicast IP Routing" in the Microsoft® Windows® 2000 Server Resource Kit Internetworking Guide and see "Determining Network Connectivity Strategies" in the Deployment Planning Guide.