MDAC 2.5 SDK - Technical Articles
May 1999
By Leland Ahlbeck and Don Willits
This article discusses the benefits, features, and behavior of pooling within the context of the Microsoft® Data Access Components (MDAC) architecture, including technology-specific tips for OLE DB, Microsoft ActiveX® Data Objects (ADO), and Open Database Connectivity (ODBC) developers. (Both ODBC and OLE DB support pooling of database connections, although the exact behavior and features differ slightly.)
The article begins with a general discussion of what pooling is and the benefits it provides. Next, the following topics are discussed in detail, with "how-to" code examples:
The Microsoft Data Access Components architecture provides a universal framework for exposing both traditional SQL-based database sources and non-SQL data stores such as documents or multidimensional sources. The architecture requires nothing of data except that it can be exposed in tabular form from an OLE DB data provider or ODBC data source. Microsoft ActiveX Data Objects (ADO), Remote Data Service (RDS), or even OLE DB itself can then expose that data to the consumer application.
Pooling enables an application to use a connection from a pool of connections that do not need to be reestablished for each use. Once a connection has been created and placed in a pool, an application can reuse that connection without performing the complete connection process.
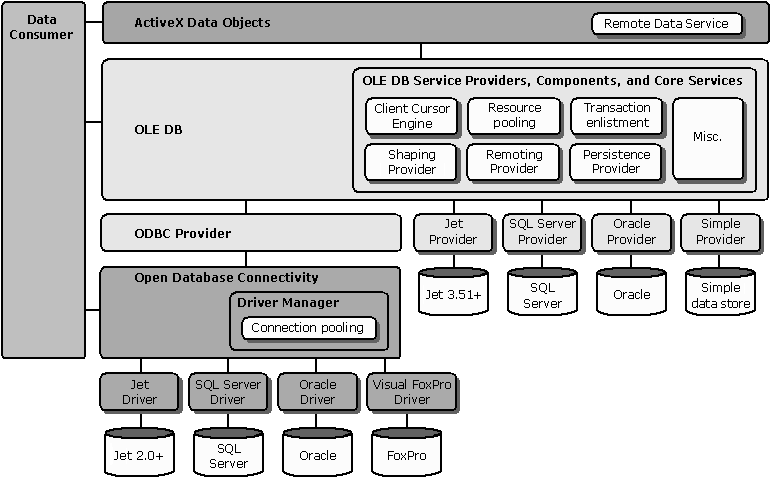
Figure 1 shows the MDAC architecture and how pooling fits into it.
Figure 1: The MDAC Stack of Components and Pooling
For either ODBC or OLE DB, pooling creates and maintains a group of connections to a database or other data store and hands them out to consumers requesting a connection to that data store. As applications open connections to a given data store and subsequently release them, a pool of open connections is built with complete authentication information and connection properties. Then, if available, connection requests to the same data store (with the same user authentication and connection properties) are satisfied from the pool rather than by making the connection on demand. Connections are held open for a period of time after a consumer application has released them. They are released by the pooling mechanism when they time out.
The main benefit of pooling is performance. Making a connection to a database can be very time-consuming, depending on the speed of the network as well as on the proximity of the database server. When pooling is enabled, the request for a database connection can be satisfied from the pool rather than by (re)connecting to the server, (re)authenticating the connection information, and returning (again) a validated connection to the application.
Pooling is available in two forms for applications that use the Microsoft Data Access Components: ODBC offers connection pooling through the ODBC Data Source Administrator, and OLE DB core components provide resource pooling as well as additional services such as shaping and the client-side cursor.
You cannot use both ODBC connection pooling and OLE DB resource pooling for a given connection to the database. You should choose which form of pooling you want to use and stick with it exclusively within a given application. However, you can disable OLE DB resource pooling and use connection pooling if you are using the OLE DB Provider for ODBC.
ODBC connection pooling was first introduced with ODBC version 3.0. With the release of MDAC 2.0 (which included OLE DB 2.0 and ODBC 3.51), OLE DB resource pooling was introduced and was available to any provider that supported COM aggregation and the OLEDB_SERVICES registry key. However, by default, resource pooling for the OLE DB Provider for ODBC was disabled, so any ADO or OLE DB data consumer using this provider actually ended up using ODBC connection pooling. This changed with the release of MDAC 2.1, and the OLE DB Provider for ODBC now uses resource pooling by default. If you prefer to use connection pooling, you can still disable resource pooling for the OLE DB Provider for ODBC.
In this article, user refers to someone who makes a connection with a specific set of credentials used to access the database. In this case, user does not refer to the logon credentials—such as the Microsoft Windows® domain account and the password used to log on to Microsoft Windows 2000—used to access an operating system. The logon credentials for the MDAC user include both the connection string for ADO and any properties or attributes set prior to connection. However, pooling in MDAC also recognizes attributes you set in ODBC prior to the connection as well as properties set in OLE DB or ADO beyond the actual connection string used. Below is an example of two almost identical connection strings, with each resulting in different user authentication:
"DSN=LocalServer;UID=sa;PWD=;DATABASE=Pubs"
"DSN=LocalServer;UID=sa;PWD=;DATABASE=QFE"
In addition, setting the value of dynamic ADO properties can affect user authentication. Consider the PROMPT property, which corresponds to the OLE DB property DBPROP_INIT_PROMPT and from there maps to the DriverCompletion argument of the ODBC SQLDriverConnect function. Changing the value of this property between two different connection objects that otherwise share an identical connection string will create two different user authentications.
Any application that makes frequent calls to the data store for connections can benefit from pooling. Figure 2 shows how both a typical Web-based and a three-tier application use pooling. Notice that multiple connections to the database are open. Further, notice that a given connection is either in a pool for OLE DB providers or in a pool for ODBC drivers, but not both. When a user releases a connection, it is returned to the pool rather than being released. The connections are freed when the database activity and the load on the Web server drops.
Figure 2: Benefits of Pooling
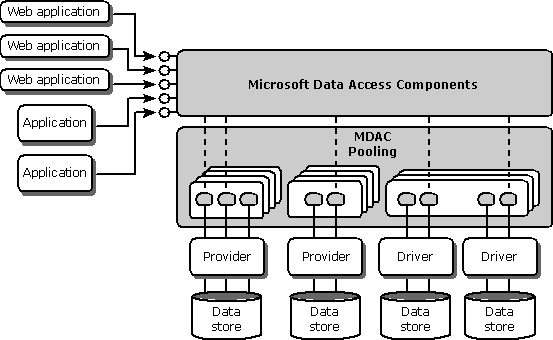
In developing an application that will run in a Web-based or multi-tier environment, pooling becomes very important. Making connections to the database can be one of the application's most time-consuming activities. Maintaining connections to the database in the resource state of the Web server can create scalability problems because all users are forced through the same connection object (not to mention that Web servers are almost by definition "stateless"). Opening a new connection on every page of a Web server is bad because it's slow. MDAC pooling provides a way to get the best of both scenarios: a limited number of connections (just enough to match your system's current load) without introducing a scalability bottleneck.
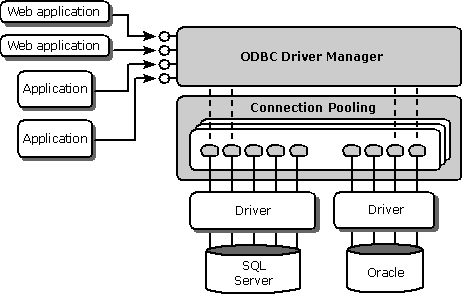
When an application makes its database connections by using ODBC database drivers, the connections are cached through the ODBC connection pool. When the first request for a connection to a database is made, the connection passes through the pooling components and then user information and any properties configured prior to making the connection are cached. The connection request is next passed on to the back-end server, and a live connection is handed to the user to satisfy the connection request. The rest of the application will be unaffected by pooling.
When the application releases the connection, the pool returns S_OK to the user, simulating a successful disconnection from the database. However, the actual connection is not released by ODBC but instead waits in the pool. When the next request for a connection to the database that has the same data source and user information comes in, it is satisfied from the connection in the pool rather than by making a full connection to the database. However, if the connection has already timed out or if there are no connections in the pool matching the request, a new connection is opened. In this respect, connection pooling is transparent to the calling application; the exception to this is pool configuration, which will be covered in the section "Configuring ODBC Connection Pooling."
Figure 3: ODBC Connection Pooling and Web/Multi-Tier Applications
To take advantage of connection pooling, a driver must be thread-safe. (If you are unsure about whether a driver is thread-safe, check with the manufacturer.) For an ODBC driver to be thread-safe, the underlying components it uses must be thread-safe as well. For example, an Oracle ODBC driver relies on SQL*Net and the Oracle Call Level Interface, and the Microsoft Access ODBC driver relies heavily on both the Microsoft Jet database engine and the Microsoft Visual Basic® for Applications Expression Service. Earlier versions of these drivers were not thread-safe because either they or their underlying components were not thread-safe. Any previous version of either driver will not work correctly. However, the ODBC driver for Oracle shipping with ODBC 3.5 (MDAC version 1.5 and later) and the ODBC driver for Access shipping with ODBC 3.51 (MDAC version 2.0 and later) are both thread-safe.
Finally, the behavior of ODBC connection pooling can be programmatically controlled by an ODBC-based application. That is, the scope of the pool can be configured to be one pool per environment handle or to be driverwide. (If you develop using the OLE DB Provider for ODBC, this cannot be configured. Only if you use the native ODBC API can you modify this behavior.) If configured by environment handle, multiple connections to different drivers can be created off that handle and all of these connections will share the same pool.
Connection pooling can be enabled or disabled from the following locations:
Within ODBC connection pooling, the following two configurable settings can affect how pooling works. Both can be set by editing the registry directly, but with ODBC 3.5 (MDAC 1.5) and later, you can use the ODBC Data Source Administrator, which is the preferred method.
In a multithreaded environment, blocking the pool avoids a situation such as the one described in the following example.
Suppose there are no connections in the pool when the first user tries to get a connection to the server that is not responding. Now 10 more users try to get their own connection to the same server, creating a race condition where the server and network are flooded with connection requests, none of which can succeed. In this situation, the Wait Retry setting helps to keep traffic on the network down and gives the server a chance to respond to the connection request. Therefore, if the server is not responding, the pooled connection for that specific user information is blocked and E_FAIL is returned to any request for a connection. Then, depending on the value of Wait Retry, a connection to the server is retried every n seconds.
The value of the Wait Retry setting will apply to all drivers on your system, not just the one you are configuring it for in the Data Source Administrator. The Wait Retry setting is stored in the registry under HKEY_LOCAL_MACHINE/SOFTWARE/ODBC/ODBCINST.INI/ODBC Connection Pooling. Changes to this setting will not take effect until the pool is released. It might be necessary to reboot your machine to put your changes into effect.
Connection pooling can be configured on a per-driver basis. For example, you can have pooling enabled for one driver and off for another driver. By setting the connection time-out value to 0 in the registry for a specific driver, pooling will be disabled for that driver. Conversely, setting CPTimeout to a nonzero value will turn on pooling for that driver.
For ODBC version 3.5 (MDAC 1.5) or later, in the ODBC core components connection pooling can be configured from the Data Source Administrator (or ODBC Data Source Administrator). The ODBC Data Source Administrator is found in the Control Panel of Microsoft Windows 95, Microsoft Windows 98, and Microsoft Windows NT® 4.0. With Windows 2000 (available in beta only at this writing), the location has moved to Administrative Tools in the Control Panel.
Alternatively, you can start the ODBC Data Source Administrator by entering Odbcad32 at the Run prompt: Click Start and then click Run.
The tab for managing connection pooling is found on the ODBC Data Source Administrator dialog box in version ODBC 3.5x (MDAC 1.5 and later).
For versions prior to version 3.5 of the ODBC core components, you need to modify the registry directly to control the connection pooling CPTimeout value. To do so, start the registry editor and locate the CPTimeout value for your driver in the appropriate registry key. For example, the CPTimeout value for SQL Server is located in the registry under HKEY_LOCAL_MACHINE/SOFTWARE/ODBC/ODBCINST.INI/SQL Server. You can find the CPTimeout value for all drivers in the registry under the HKEY_LOCAL_MACHINE/SOFTWARE/ODBC/ODBCINST.INI/Driver_Name key.
The default time-out value for connection pooling is 60 seconds, and this value should be adequate for most installations.
The value setting for Wait Retry will apply to all drivers on your system, not just the one you are configuring it for in the Data Source Administrator. This Wait Retry value is stored in the registry under HKEY_LOCAL_MACHINE/SOFTWARE/ODBC/ODBCINST.INI/ODBC Connection Pooling. Changes to this setting will not take effect until the pool is released, and you might need to reboot your machine to put your changes into effect.
Warning Using the registry editor incorrectly can cause serious, systemwide problems that may require you to reinstall your Windows operating system to correct them. Microsoft cannot guarantee that any problems resulting from changes you make to the registry by using a registry editorcan be solved. Use this tool at your own risk.
As discussed earlier, pooling can be limited to a scope of the environment handle or the driver. Your application controls this by calling SQLSetEnvAttr with either SQL_CP_ONE_PER_DRIVER or SQL_CP_ONE_PER_HENV.
In Code Example 1, the console application is being set up to pool along with the rest of the application on the machine by setting the pooling value to SQL_CP_ONE_PER_DRIVER. This code demonstrates how to enable ODBC connection pooling.
Note Other options for connection pooling are: SQL_CP_OFF, which disables connection pooling; SQL_CP_ONE_PER_HENV, indicating one pool per environment handle; and SQL_CP_DEFAULT, which is currently mapped to SQL_CP_OFF.
Code Example 1: Enabling ODBC Connection Pooling
HENV henv = SQL_NULL_HENV;
HDBC hdbc = SQL_NULL_HDBC;
SQLHSTMT hstmt = SQL_NULL_HSTMT;
RETCODE rc = SQL_SUCCESS;
rc = SQLSetEnvAttr( SQL_NULL_HENV,
SQL_ATTR_CONNECTION_POOLING,
SQL_CP_ONE_PER_DRIVER,
0 );
rc = SQLAllocHandle( SQL_HANDLE_ENV, SQL_NULL_HENV, &henv );
rc = SQLSetEnvAttr( henv,
SQL_ATTR_ODBC_VERSION,
(SQLPOINTER) SQL_OV_ODBC3,
SQL_IS_INTEGER );
rc = SQLAllocHandle ( SQL_HANDLE_DBC,
henv,
&hdbc );
for ( long i = 1; i<= nCount && ODBCSUCCESS( rc ); i++ )
{
rc = SQLConnect( hdbc,
(SQLCHAR*) lpszDSN, SQL_NTS,
(SQLCHAR*) lpszUid, SQL_NTS,
(SQLCHAR*) lpszPwd, SQL_NTS );
rc = SQLAllocHandle( SQL_HANDLE_STMT, hdbc, &hstmt );
if ( hstmt ) SQLFreeHandle( SQL_HANDLE_STMT, hstmt );
if ( hdbc ) SQLDisconnect( hdbc );
}
if ( hdbc ) SQLFreeHandle( SQL_HANDLE_DBC, hdbc );
if ( henv ) SQLFreeHandle( SQL_HANDLE_ENV, henv );
For Internet Information Server (IIS) version 3.0, pooling was set to off by default and you will need to manually turn on connection pooling. For IIS version 4.0 and later, pooling has been set to on by default. (IIS 3.0 used ODBC 3.0, and IIS 4.0 used ODBC 3.5.) If you are coding by using the ActiveX Data Objects (ADO) object model to the OLE DB Provider for ODBC (MSDASQL), connection pooling will be turned on for you. If you are not using ADO and are coding directly to the ODBC API, you will need to turn on pooling yourself. The section "Configuring ODBC Connection Pooling," earlier in this document, provides details on how to accomplish this.
As mentioned in the "Introduction" section, when OLE DB resource pooling first appeared in MDAC 2.0, it was by default disabled for the OLE DB Provider for ODBC. Therefore any ADO or OLE DB data consumer using this provider implicitly used ODBC connection pooling. With the release of MDAC 2.1 (and later versions), this changed and now the OLE DB Provider for ODBC uses OLE DB resource pooling by default. You can easily restore ODBC connection pooling by changing the registry setting of OLEDB_Services for the CLSID of the OLE DB Provider for ODBC. See Table 2, later in this document, for a list of values that can exist in the OLEDB_Services registry entry.
Connection pooling allows more than a single pool. The number of pools is equal to the number of processors. This helps to avoid conflicts when multiple threads are in use on the server. With only one pool and 50 threads running, there would be locking conflicts on the pool as the pools were locked for updating. However, with multiple pools available, the request for a connection simply moves to the next pool if the first pool is locked. (Note that a given pool can have connections to different data sources for one or more different drivers.)
When a request for a new connection comes into the pool, the pooling logic must look through the available connections for an existing connection that matches the properties of the connection attributes used to request the connection. This is accomplished by finding a pool that is not locked, locking the pool, and looking at each available connection in the pool to determine whether there is a match between the pooled connection information and the requesting connection. If a match is found, the pooled connection will be handed to the application requesting the connection and the pool will be unlocked. If a connection with the proper connection information cannot be found, a new connection will be created.
ODBC connection pooling activity can be monitored through the Performance Monitor in Windows NT 4.0. Keep in mind that this tool should be used to check pooling on an occasional basis and not be left on indefinitely: It can and will have an adverse effect on system and pool performance, even if Performance Monitor isn't actually running. (For ODBC version 3.51, pool monitoring can be enabled from within the ODBC Data Source Administrator. After starting the Data Source Administrator either from the Control Panel or by using Odbcad32.exe, you will find a Connection Pooling tab (for ODBC 3.5 and later). Unlike the Wait Retry Time value on the Connection Pooling page, the Performance Monitor settings are for all drivers, not just the selected driver.) To enable pool monitoring, open the ODBC icon in the Control Panel. In the ODBC Data Source Administrator dialog box, click the Connection Pooling tab. Under Performance Monitor, select the Enable option.
Connection pooling monitoring under ODBC 3.5 requires that you make changes to the registry on your machine.(If you are running ODBC 3.51, you will not need to take these steps.) As with any changes you make to the registry, it is extremely important to back up the registry first. To do this, use the backup facilities provided in the registry editor. First, verify that you are running ODBC 3.5. If you are, the files mentioned in the steps below are included with the Pooling Toolkit in the Connpool.reg directory.
Verify what version of ODBC you are running. There are two important ODBC-related versions that you need to check. One is the version of the ODBC core components that is installed on your machine. The other is the version of the ODBC driver that you are using. Both can be determined by opening the ODBC Data Source Administrator in the Control Panel. To check the core ODBC version, click the About tab. To check the version of the driver you are using, click the Drivers tab and then check the appropriate driver version.
After confirming that you are indeed using ODBC 3.5, follow these steps:
To monitor connection pooling:
Start Performance Monitor (PerfMon.exe), either from the command prompt or by clicking Start and then clicking Run.
Click the Add counter button (+).
In the Add to Chart dialog box, you will now have an entry for ODBC Connection Pooling under the process list box. (If you don't, either pooling isn't enabled in the Data Source Administrator or you need to restart your machine because existing applications or services have ODBC loaded in memory, preventing any changes in the Data Source Administrator from taking immediate effect.) There will now be six counters that can be monitored by performance monitor. The naming of the counters is based on the distinction of hard versus soft connections. Hard actions are taken by the connection pooling process. Soft actions are taken by the application that uses connection pooling. See Table 1, ODBC Connection Pooling Performance Monitor Counters, for a description of each counter.
The counter that you see the most activity on should be the ODBC Soft Connection Counter. This indicates the number of connections that are satisfied by the connection pool. In this case, a live connection comes from the pool rather than requiring your application to make a new connection to the database.
Table 1: ODBC Connection Pooling Performance Monitor Counters
| Counter | Definition |
| ODBC Hard Connection Counter per Second | The number of actual connections per second that are made to the server. The first time your environment carries a heavy load, this counter will go up very quickly. After a few seconds, it will drop to zero. This is the normal situation when connection pooling is working. When the connections to the server have been established, they will be used and placed in the pool for reuse. |
| ODBC Hard Disconnect Counter per Second | The number of hard disconnects per second issued to the server. These are actual connections to the server that are being released by connection pooling. This value will increase from zero when you stop all clients on the system and the connections start to time out. |
| ODBC Soft Connection Counter per Second | The number of connections satisfied by the pool per second—in other words, connections from that pool that were handed to users. This counter indicates whether pooling is working. Depending on the load on your server, it is not uncommon for this to show 40–60 soft connections per second. |
| ODBC Soft Disconnection Counter per Second | The number of disconnects per second issued by the applications. When the application releases or disconnects, the connection is placed back in the pool. |
| ODBC Current Active Connection Counter | The number of connections in the pool that are currently in use. |
| ODBC Current Free Connection Counter | The current number of free connections available in the pool. These are live connections that are available for use. |
Creating stored procedures to process prepared statements with connection pooling enabled can have unexpected results. Before elaborating on unexpected behavior with connection pooling and temporary stored procedures, it is important to first understand when temporary stored procedures are created and, more importantly, deleted.
Creating temporary stored procedures for prepared SQL statements is an option that is configurable from the ODBC Data Source Administrator. By default, this setting is "On" for the SQL Server 2.65 and 3.5 drivers. This means that when an SQL statement is prepared, a temporary stored procedure is created and compiled. When the prepared command is called from an OLE DB consumer or an ODBC application, the temporary stored procedure is executed, saving the overhead of parsing and compiling the SQL statement. If used properly, this feature can improve the performance of your application. If your SQL statement is going to be executed more than two times or contains parameters and will be called multiple times, the statement should be prepared. Remember that there is a price to be paid up front to prepare an SQL statement and that preparation is lost as soon as you disconnect from the database.
With connection pooling enabled, the issue becomes how to determine when these temporary stored procedures should be deleted. With the SQL Server 2.65 driver, they will be released when the connection is released. With the SQL Server 3.5 or later driver, you can choose whether to delete them when the connection is released, or both when the connection is released and as appropriate while connected.
Unexpected behavior can occur with temporary stored procedures and connection pooling if you are using the default setting. In that case, you run the risk of running out of room in the SQL Server Temporary Database (TempDB), where temporary stored procedures are created and stored. When connection pooling is enabled, a connection is made to the database, but when the client is done with it and releases it, the connection goes back into the pool. When the connection goes back into the pool, the connection is not released at the server level and the stored procedures are not deleted from TempDB. Effectively, you create temporary stored procedures in TempDB that are no longer associated with a client and will never be called again.
With SQL Server 7.0, the effects of the stored procedures being created in TempDB can be a little different. In SQL Server 7.0, the TempDB can be configured to automatically grow when out of space. If this configuration was set to drop stored procedures when disconnecting, your TempDB might not run out of space but can become very large.
When you are running the SQL Server 2.65 driver, it might be advisable to disable the creation of stored procedures while preparing a command when running with connection pooling. With the SQL Server 3.5 and newer drivers, when adding or configuring a DSN in the Data Source Administrator, you will have the option of creating temporary stored procedures. This option should be disabled or set When you disconnect and as appropriate while you are connected when running connection pooling. Setting this option means that the ODBC SQL Server driver will drop the connection when the command that created the interface goes out of scope. If your client code is ADO, the stored procedure would be released when the ADODB.Recordset and command objects are closed. SQL Server 7.0 now supports prepared commands, so it will not create temporary stored procedures when you have requested that your command be prepared.
If you change the database context to another while you are connected to the database and do not set it back to the original context, you may cause problems in the pool. Consider the case where you use a stored procedure to change the database context to TempDB and then disconnect at the application level. The connection, now pointing to TempDB rather than to your original database, is then returned to the pool. The next time a request for a connection to your original database is made, the pooled connection pointing to TempDB might be handed to it. To avoid this, always maintain the original database context before disconnecting.
OLE DB resource pooling, also known as OLE DB session pooling, is handled by the OLE DB core components. To take advantage of resource pooling, an OLE DB consumer must invoke the data provider by using either the IDataInitialize or the IDBPromptInitialize interface. (ADO will attempt to do this automatically.) OLE DB resource pooling can be turned on for one provider and off for another.
Note Performing CoCreateInstance on IDBInitialize is traditionally used in OLE DB to open a data source object. To use resource pooling, you perform CoCreateInstance on either IDataInitialize or IDBPromptInitialize. Both interfaces are part of the OLE DB service components and not your OLE DB data provider. You can use IDataInitialize and IDBPromptInitialize to retrieve an instance of IDBInitialize from your data provider so that the service components can be used. The two interfaces make it possible to use service component features such as pooling, transaction enlistment, and the Client Cursor Engine.
When the application creates an OLE DB data source object (via ADO or an OLE DB consumer), OLE DB services query the data provider for supported information and provide a proxy data source object to the application. To the consuming application, this proxy data source object looks like any other data source object, but in this case setting properties merely caches the information in the local proxy. When the application calls IDBInitialize::Initialize in OLE DB or opens a connection in ADO, the proxy data source object checks whether any connections already exist that match the specified connection information and are not in use. If so, rather than creating a new object, setting properties, and establishing a new connection to the database, the proxy data source object uses the existing initialized data source object. When the application releases the data source object, it is returned to the pool. Any data source object that is released by the application and not reused after 60 seconds is automatically released from the pool.
Figure 4 shows how OLE DB resource pooling works.
Figure 4: The Benefits of OLE DB Resource Pooling
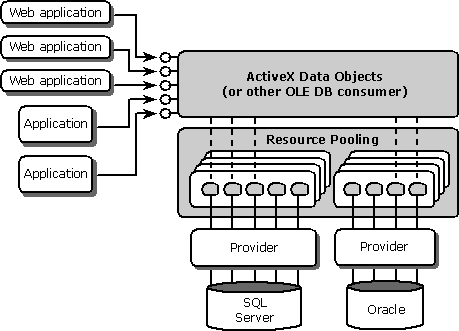
Note The name resource pooling is actually something of a misnomer. It implies that any kind of resource can be pooled, when in fact OLE DB resource pooling is just for the pooling of an OLE DB data source proxy object (DPO). Resource pooling does use the resource dispenser found with Microsoft Transaction Server, which is a more generic form of pool manager. More than a few OLE DB users have been confused by the term "resource pooling" into thinking that it pools more than it actually does.
Note Most of the functionality of Microsoft Transaction Server has been incorporated into Windows Component Services for Microsoft Windows 2000. References to Microsoft Transaction Server in this article may not reflect the equivalent behavior with Windows Component Services. If you are using Windows 2000, see your operating system documentation for more information.
By default, service components are enabled for all Microsoft OLE DB providers if the provider is invoked by IDataInitialize or IDBPromptInitialize and if the provider is marked to work with pooling by using the OLEDB_Services registry key.
You can control pooling from your application in the following three ways:
The time-out value is set to 60 seconds; this value cannot be configured in OLE DB resource pooling prior to the release of MDAC 2.5.
Retry Wait works much differently in resource pooling than in ODBC connection pooling. After the server has been determined to be unavailable, resource pooling blocks the pool. The next retry for a valid connection on the server occurs after one minute. If this attempt fails, the next retry occurs after two minutes, and again after five minutes. Thereafter, the retry occurs every five minutes until a valid connection is returned.
To determine whether individual core components can be invoked to satisfy extended functionality requested by the consumer, OLE DB compares the properties specified by the consumer to those supported by the provider. Table 2 lists values that can exist in the OLEDB_Services registry entry, which should be created during installation of the provider.
Table 2. Setting OLE DB_Services Registry Entry Under Provider's CLSID
| Default services enabled | DWORD value |
| All services (the default) | 0xffffffff |
| All services except pooling | 0xfffffffe |
| All services except pooling and auto-enlistment | 0xfffffffc |
| All services except client cursor | 0xfffffffb |
| All services except client cursor and pooling | 0xfffffffa |
| No services | 0x00000000 |
| No aggregation, all services disabled | No OLEDB_Services registry entry |
With the release of MDAC 2.5, first included with Windows 2000 Beta 3, you can configure both connection time-out and the Retry Wait values by using the registry. Windows 2000 Beta 3 includes a beta release of OLE DB and instructions in the OLE DB Readme for doing so. Those instructions are summarized below.
When set under a provider's CLSID entry in the registry, the SPTimeout value controls the length of time, in seconds, that unused sessions are held in the pool. SPTimeout should be entered as a DWORD value under HKEY_CLASSES_ROOT/CLSID/ClassID where ClassID is the CLSID of the OLE DB provider. The default SPTimeout value is 60 seconds.
The Retry Wait value controls the length of time, in seconds, to wait between connection attempts. It is entered as a DWORD value under HKEY_LOCAL_MACHINE/SOFTWARE/Microsoft/DataAccess/Session Pooling. The default SPTimeout value is 60 seconds.
If you write directly to the OLE DB API, you can set the DBPROP_INIT_OLEDBSERVICES property to enable or disable various core components, including OLE DB resource pooling. There is no way to configure connection time-out or Retry Wait programmatically in your application except by manipulating the registry entries directly. It is best not to have any services or applications using OLE DB when you make these changes, or the effects might not show up right away.
Table 3 lists values and the services enabled or disabled by the value settings. Code Example 2 is an excerpt of code that uses resource pooling in an OLE DB consumer.
Table 3. Setting OLE DB Services by Using the DBPROP_INIT_OLEDBSERVICES Property
| Services enabled | Property value |
| All services | DBPROPVAL_OS_ENABLEALL |
| All services except pooling | (DBPROPVAL_OS_ENABLEALL & ~DBPROPVAL_OS_RESOURCEPOOLING) |
| All services except pooling and auto-enlistment | (DBPROPVAL_OS_ENABLEALL & ~DBPROPVAL_OS_RESOURCEPOOLING & ~DBPROPVAL_OS_TXNENLISTMENT) |
| All services except client cursor | (DBPROPVAL_OS_ENABLEALL & ~DBPROPVAL_OS_CLIENTCURSOR) |
| All services except client cursor and pooling | (DBPROPVAL_OS_ENABLEALL & ~DBPROPVAL_OS_RESOURCEPOOLING & ~DBPROPVAL_OS_CLIENTCURSOR) |
| No services | ~DBPROPVAL_OS_ENABLEALL |
Code Example 2: OLE DB Consumer Code Using Pooling
long OLEDBConnect( char *lpszInitString,
bool bUsePooling, // Flag to set pooling
ULONG nCount )
{
IDataInitialize *pIDataInitialize = NULL;
IDBProperties *pDBProperties = NULL;
IDBInitialize *pIDBInit = NULL;
HRESULT hr = S_OK;
WCHAR wszInitString[1024];
AtoU( lpszInitString, &wszInitString[0], 1024 );
hr = CoCreateInstance(CLSID_MSDAINITIALIZE,
NULL,
CLSCTX_INPROC_SERVER,
IID_IDataInitialize,
(void**)&pIDataInitialize);
for (ULONG i=0;i<nCount && SUCCEEDED( hr ); i++)
{
hr=pIDataInitialize->GetDataSource(NULL,
CLSCTX_INPROC_SERVER,
wszInitString,
IID_IDBInitialize,
(IUnknown**)&pIDBInit);
if (pIDBInit)
hr=pIDBInit->Initialize();
if ( bUsePooling == false )
if (pIDBInit)
pIDBInit->Uninitialize(); // Disables Pooling(!)
if (pIDBInit) pIDBInit->Release();
pIDBInit = NULL;
}
if (pIDataInitialize)
pIDataInitialize->Release();
return 0;
}
Note One of the key points to note in the preceding code is that if you call IDBInitialize::Uninitialize, you will turn off pooling! To release a connection, use IDBInitialize::Release instead.
The OLE DB property DBPROP_INIT_OLEDBSERVICES maps directly to a connection string attribute, "OLE DB Services", as shown in Table 4. Code Example 3 demonstrates this.
Table 4. Setting OLE DB Services by Using ADO Connection String Attributes
| Services enabled | Value in connection string |
| All services (the default) | "OLE DB Services = -1;" |
| All services except pooling | "OLE DB Services = -2;" |
| All services except pooling and auto-enlistment | "OLE DB Services = -4;" |
| All services except client cursor | "OLE DB Services = -5;" |
| All services except client cursor and pooling | "OLE DB Services = -6;" |
| No services | "OLE DB Services = 0;" |
Code Example 3: ADO Consumer Code Using Pooling
' This will take advantage of resource pooling.
Dim i As Integer
Dim c As ADODB.Connection
Dim r As ADODB.Recordset
Dim c as new ADODB.Connection
c.Open "DSN=LocalServer;UID=sa;PWD=;OLE DB Services=-1"
For i = 1 To 100
Set r = New ADODB.Recordset
r.Open "SELECT * FROM Authors", c
Set r = Nothing
Next I
c.close
Set c = Nothing
Resource pooling can be enabled in several ways:
Note Pooling will not be enabled if you call CoCreateInstance directly on the CLSID of the data provider.
In OLE DB resource pooling, the following formula determines the number of pools (where N is the number of pools, P is the number of processors, and C is the number of distinct sets of connection attributes on the system):
N = (P + 1) * C
Using this formula, OLE DB resource pooling eliminates lock contentions on the pools.
OLE DB resource pooling keeps a map of which pools contain which users. From there, it is possible to jump to the right pool and start looking for an available connection. With OLE DB resource pooling, a given pool contains connections only for a single provider with a specific set of connection attributes. In other words, each pool contains only connections to one set of credentials and one data store.
When developing an application using either ADO or native OLE DB, the following tips will help you to enable resource pooling or to avoid inadvertently disabling it. These rules apply whether you use ADO, OLE DB consumer templates, or native OLE DB code.
Note If you open a Connection object, remember to close it. Do not rely on garbage collection to implicitly close your connections.
As mentioned above, ADO attempts to use or enable services implicitly by referencing the OLEDB_Services registry value when a connection is established. However, some older providers may not be able to support services. Simply creating this registry entry is not enough to enable services for your application. The data provider must support certain features or services will not work. Attempting to use services with a data provider that does not offer this functionality can create unexpected behavior in your application. Following is a brief list of the functionality a data provider must support for your consumer application to utilize services:
For more information, consult either the OLE DB Readme that shipped with the Data Access 2.0 SDK or the OLE DB Services section in the documentation with version 2.1 and later of the SDK.
Occasionally, MDAC pooling might not work as expected. When this happens, you need to look at what your application is doing that could have a negative impact on pooling, especially if the application has less than comprehensive error handling. At this time, OLE DB does not offer a way to trace activity on OLE DB providers. This makes robust error handling (see the discussion later in this article) even more important.
Pooling trouble diagnosis often begins by using tools such as SQL Trace and SQL Server Performance Monitoring to track connection creep, or an increasein the number of open connections on a database server. However, this does not equate to a failure in pooling. Identifying connection creep is only the beginning of an analysis, not its conclusion.
Common causes of connection creep include:
Note If you have effective error trapping in your code, you can receive error messages that point to the real culprit (such as a failure in SQL Server's NetLib or Oracle's SQL*NET components).
Details of several of these problems are discussed in the sections that follow.
Pooling problems are frequently caused by an application that does not clean up its connections. Connections are placed in the pool at the time that the connection is closed and not before. To avoid this, always explicitly close an object you open. If you don't explicitly close it, chances are it won't ever be released to the pool.
Even if the language you use has effective and reliable garbage collection, an instance of an open ADO Connection or Recordset object going out of scope does not equate to the Close method of that object being implicitly invoked. You must close it explicitly.
Failing to close an open Connection or Recordset object is probably the single most frequent cause of connection creep and the single largest cause of incorrect diagnoses of pooling failure.
It is sometimes confusing in pooling to correctly disconnect a Recordset object. To release a connection into the pool, especially in three-tier environments, you must use a client-side, static cursor with BatchOptimistic locking. You must also release the Recordset ActiveConnection object. Otherwise, the Recordset object will not be disconnected and, more importantly, the connection will not be released into the pool. You cannot disconnect a Recordset object with a server-side cursor.
Code Example 4 demonstrates how to implement a disconnected Recordset object—in this case for a Microsoft Transaction Server business object. The environment in which the code is used is not as significant as the actual steps to disconnect the Recordset object.
Code Example 4: Disconnected Recordset in ADO
Public Function ServiceTest(connectStr As String, SqlText As String) As String
Dim c As New ADODB.Connection
Dim r As New ADODB.Recordset
On Error GoTo handler
c.ConnectionString = connectStr
c.CursorLocation = adUseClient
c.Open
Set r.ActiveConnection = c
r.Open SqlText, , adOpenKeyset, adLockBatchOptimistic, -1
Set r.ActiveConnection = Nothing ' This disconnects the recordset.
c.Close
Set c = Nothing
' Recordset is now in disconnected state; do something with it.
r.Close
Set r = Nothing
Exit Function
handler:
ServiceTest = ErrHandler(c, Nothing, r)
End Function
If you do not intend to update any data in the cursor, it is more efficient to use a server-side (rather than a client-side) cursor. This is because the creation of the client-side object is resource-intensive and can impact performance.
If the connection is returned to the pool, the temporary table will persist until the connection is actually released—not just returned to the pool. If your application uses many temporary tables, this might create a resource problem on the server. If you use a stored procedure on the server to create the temporary table, the temporary table will be destroyed when the stored procedure goes out of scope. Temporary tables not created by stored procedures will be destroyed only after the connection is actually released from the pool.
The DBPROP_CONNECTIONSTATUS property reveals whether a stale connection exists for a given OLE DB provider in the pool. The pool returns a connection to the client even if the status of the connection is stale. For example, this can happen if the underlying server accessed by the connection is no longer available on the network.
Table 5 summarizes the DBPROPVAL_CS_* properties defined in OLE DB. These values can be used to determine the status of a connection.
Table 5. Valid Values for Connection Status Dynamic Property
| Connection status | Value | Comment |
| UNINITIALIZED | 0L | Connection object has not had Open method called yet. |
| INITIALIZED | 1L | A valid connection. |
| COMMUNICATIONFAILURE | 2L | The connection is stale. Close and reopen the Connection object. |
Resource pooling can be inadvertently disabled for your application. The persistence and behavior of resource pooling depend on several conditions that occur with a given set of user authentication criteria, such as the following:
Code Example 5 and Code Example 6 are examples of how you can inadvertently disable resource pooling.
Code Example 5: Disabling Pooling by Using IDBInitialize::Uninitialize
hr = CoCreateInstance(CLSID_MSDAINITIALIZE, NULL,
CLSCTX_INPROC_SERVER, IID_IDataInitialize,
(void**)&pIDataInitialize);
for (ULONG i=0;i<nCount && SUCCEEDED( hr ); i++)
{
pIDataInitialize->GetDataSource(NULL, CLSCTX_INPROC_SERVER,
wszInitString, IID_IDBInitialize,
(IUnknown**)&pIDBInit);
hr=pIDBInit->Initialize(); // Opens connection
pIDBInit->Uninitialize(); // Disables Pooling(!)
pIDBInit->Release();
}
Code Example 6: Disabling Pooling by Eliminating Instances of IDataInitialize
' This will not take advantage of resource pooling.
Dim i As Integer
Dim c As ADODB.Connection
Dim r As ADODB.Recordset
For i = 1 To 100
Set c = New ADODB.Connection
Set r = New ADODB.Recordset
c.Open "DSN=LocalServer;UID=sa;PWD=;OLE DB Services=-1"
r.Open "SELECT * FROM Authors", _
"DSN=LocalServer;UID=sa;PWD=;"
r.close
c.close
Set c = Nothing
Set r = Nothing
Next I
This article has repeatedly emphasized the need for developers who use OLE DB resource pooling to keep at least one connection open for each set of user credentials used to access the data store. This is not to be confused with the mistake of opening up multiple and unnecessary Connection objects, or even multiple Recordset objects. It's also not to be confused with using just one Connection object for several hundred ASP pages.
ASP developers should open one connection per set of unique user credentials. However, an ASP developer can eliminate the benefits of pooling in this scenario in the following ways:
For example, you can easily circumvent any performance gains found in pooling by using code such as the following:
Dim c(200) as ADODB.Connection
Dim r(200) as ADODB.Recordset
Presently, these two lines of code appear to be frequently and incorrectly used on individual ASP pages. The overhead of instantiating, opening, and manipulating this many objects will eliminate any benefit of pooling, not to mention that it will swell the pool to unnecessary size just to hold each of those connections. If you use this technique on multiple ASP pages, which in turn are hit by multiple users, the amount of memory needed just to hold all of those ADO objects in memory can soon reach into the gigabytes.
If you don't want to circumvent the benefits of pooling, however, you can do this: Within a given ASP page, open the Connection object and one or more Recordset objects that you need. Then close and delete them.
This also applies for non-ASP developers who are developing an application with multiple threads. Do not try to share a single Connection object between all threads. Instead, use one thread, one Connection object, and one persistent connection in your main application to keep the pool alive.
For Microsoft Transaction Server developers, this is not an issue. Microsoft Transaction Server itself enables the pool, whether you implement a single Connection object or not. Because Microsoft Transaction Server is inherently stateless, trying to keep that persistent Connection object around, let alone actually use it, is redundant.
While pooling is a valuable tool that can give applications increased performance and scalability, it can also be sabotaged to the point of uselessness through coding techniques such as those just listed.
When OLE DB encounters an error condition or if the underlying provider passes back informational messages, it will attempt to convey this information to your application. However, that does not mean the application is actually receiving it or logging it appropriately. Microsoft Visual Basic Scripting Edition (VBScript) applications, in particular, have loose error handling.
OLE DB error handling extends Automation error handling by adding the ability of an error object to contain multiple error records.
Chapter 16, "Errors," in the Microsoft OLE DB Programmer's Reference, has an excellent discussion of how to use these features. (The most up-to-date version is available in the MDAC SDK, and the OLE DB 2.0 version is available in print from Microsoft Press.) In the same reference, Appendix F, "Sample OLE DB Consumer Application," demonstrates practical code for the use of OLE DB error handling. In addition, the SQL Server 7.0 documentation has an excellent code example that shows how to use the optional interfaces ISQLErrorInfo and ISQLServerErrorInfo.
Code Example 7 shows OLE DB error handling.
Code Example 7: Error Handling with OLE DB
// Goes to CLEANUP on Failure_
#define CHECK_HR(hr) \
if(FAILED(hr)) \
goto CLEANUP
// Goes to CLEANUP on Failure, and displays any ErrorInfo
#define XCHECK_HR(hr) \
{ \
if(FAILED(ErrHandler(hr, LONGSTRING(__FILE__), __LINE__))) \
goto CLEANUP; \
}
XCHECK_HR(hr = CoCreateInstance(CLSID_MSDAINITIALIZE,
NULL,
CLSCTX_INPROC_SERVER,
IID_IDataInitialize,
(void**)&pIDataInitialize));
CLEANUP:
if (pIDBInitialize != NULL ) pIDBInitialize->Release();
ADO and RDS generate an error in the native language you use to implement your application. In Microsoft Visual Basic, this is an Err object. In Microsoft Visual C++®, this is usually an exception or a failed HRESULT. In Java, an instance of an exception class is raised.
Note In VBScript, no event is fired. This makes error handling in VBScript especially challenging.
If you run in an environment that uses Active Server Pages (ASP), it is a good practice to define a standard error handler and use this error handler unilaterally throughout your code. That way, if you need to change your error handler, you need only make that change in one place—not in every page that uses error handling.
Code Example 8 shows ADO error handling.
Code Example 8: Error Handler in ADO
Dim Con0 As ADODB.Connection
On Error GoTo ErrHandler
...
Exit Sub
ErrHandler:
' For this code, we do not have any Command or Recordset objects,
' but this error handler would close them down if they did exist.
Call ErrHandler(Con0, Nothing, Nothing)
To summarize what this article has discussed, here is a list of the top 10 reasons why pooling might not be turned on. This text was first made available in the OLE DB readme.
NOTE These items are cumulative. That is, any item will disable pooling for that data source object, regardless of what the other values are.
This paper has presented numerous code examples, which (for the most part) were taken directly from the MDAC Pooling Toolkit. The Toolkit consists of samples that you can use as templates for taking advantage of pooling in your application as well as for verifying and diagnosing performance issues that arise due to pooling. Table 6 describes each of the samples and what it demonstrates.
Note By default, error handling for these applications will display both warnings and error messages. To disable display warnings, see the ErrHandler function in each sample.
Table 6: Contents of the MDAC Pooling Toolkit
| Sample | Description |
| CODE/CONSOLE/ADO/ASP | Pooling.asp demonstrates how to invoke and inadvertently disable pooling from ADO to one of four providers. It uses a business object, GetTick, to return the current time. |
| CODE/CONSOLE/ADO/VB | PoolingVB.vbw is a Visual Basic 6.0 implementation of the same functionality as Pooling.asp. |
| CODE/CONSOLE/ADO/VC | PoolingVC.dsw is a Visual C++ 6.0 implementation of the same functionality as Pooling.asp. |
| CODE/CONSOLE/ODBC | Odbcpool.dsw is a Visual C++ 6.0 implementation of ODBC connection pooling. Command-line arguments specify DSN to open. Driver-based and environment handle–based pooling are demonstrated. |
| CODE/CONSOLE/OLE DB/PROPERTIES | Oledbpool.dsw is a Visual C++ 6.0 implementation of OLE DB resource pooling. Command-line arguments specify the provider to use. This version opens a connection to the data source by using IDataInitialize::CreateDBInstance. |
| CODE/CONSOLE/OLE DB/NOPROPERTIES | Oledbpool.dsw is a Visual C++ implementation identical to the Properties example, except that it uses IDataInitialize::GetDataSource. |
| CODE/MTS/MTSClient | This simple Microsoft Transaction Server client, written in Visual Basic, invokes a Microsoft Transaction Server business object. It can invoke the business object with pooling either enabled or disabled. |
| CODE/MTS/MTSBusObj | This simple Microsoft Transaction Server business object, written in Visual Basic, creates a disconnected Recordset and returns a count of how many records were in the Recordset. |
These samples make these assumptions regarding your development environment:
OLE DB resource pooling is a key technique for achieving increased performance with Microsoft Data Access Components. In ODBC, OLE DB, and ADO/RDS programming, pooling is a key piece of your application's architecture, even if you don't actually write ODBC or OLE DB code. Table 7 summarizes the key differences in behavior and functionality between the two pooling models.
Table 7. Comparison of ODBC Connection Pooling and OLE DB Resource Pooling
| Feature | Connection pooling | Resource pooling |
| Enabling pooling | ODBC 3.5+: In the Data Source Administrator.
Optionally, ODBC 3.0+ can set this in the registry. |
Implicitly available in ADO.
Implicitly used by components running under Microsoft Transaction Server. Consumer uses IDataInitialize or IDBPromptInitialize. |
| Disabling pooling | By using registry setting.
By using ODBC Data Source Administrator. By using SQLSetEnvAttr for ODBC API-based applications. |
By using registry setting.
Implicitly disabled if there is not at least one persistent ADO Connection object (or OLE DB IDataInitialize interface) open for each unique set of user credentials in the application. If every connection has unique connection attributes or properties, n pools are created that contain one connection each. This does not disable pooling, but it does disable the benefits of pooling. Provider does not support COM aggregation or have OLEDB_SERVICES registry key. |
| Configurable pool time-out | Yes | No |
| Number of pools | If P = number of processors:
(P) Connections using different drivers and user credentials can be and are stored in the same pool. |
If P = number of processors and C = number of unique sets of user credentials (the connection string plus any properties you set before opening the connection):
((P + 1) * C) Each pool has a homogeneous set of connections with identical user credentials. |
| Support required within the driver or provider | Driver must be thread-safe. No other specific requirements. | Provider must be thread-safe (implicit with OLE DB).
Must support IDataInitialize and IDBPromptInitialize interfaces. Connection must be created through these interfaces. Provider supports COM aggregation. Provider supports OLEDB_Services registry key. |
This article has discussed how to enable, disable, and configure MDAC pooling and has presented practical tips for using pooling and for diagnosing issues that developers may encounter. The primary advantage of pooling is performance. The time it takes to open a connection is a significant resource sink in any data operation. Pooling enables developers who use MDAC to maximize performance, whether using ODBC connection pooling or OLE DB resource pooling.
Aaron Cohen & Mike Woodring, Win32 Multithreaded Programming, O'Reilly & Associates, Inc., 1998.
Microsoft, Microsoft OLE DB 2.0 Programmer's Reference and Data Access SDK, MSPRESS, 1998.
Q193332 (FILE:MDACCON.EXE Using Connection Strings w/ ODBC/OLEDB/ADO/RDS) for details on connection strings for ODBC Drivers and OLE DB Providers.
Microsoft Data Access Web Site.
The Knowledge Base can be obtained at Support Online from Microsoft Product Support Services. You will have to register to use this site. Articles relating to pooling, Microsoft Data Access Components, ActiveX Data Objects, ODBC, OLE DB can be found by querying on any one of the following "products" available at this site:
Keywords:
connection pooling (ODBC)
resource pooling (OLE DB)
session pooling (OLE DB)
MDAC pooling