MDAC 2.5 SDK - Technical Articles
Summary: This article details the features and advantages of the Microsoft Universal Data Access strategy, compares alternative data access technologies, and suggests reasons to choose one technology over another.
The information you use to make everyday business decisions is a lot more than just data stored in a relational database. It typically includes personal data in spreadsheets, project management applications, e-mail, mainframe data such as VSAM and AS/400, computed data calculated on the fly, and ISAM data. To that, add the information available in directory services, the documents available on your hard drive or on the network, and the wealth of data in myriad forms on the Internet. Each of these types of data needs to be taken into account when making decisions, yet each is in a different format, stored in a variety of containers, and accessed in a fundamentally different way.
If you've ever developed applications that access data from data stores, it's likely that you have been exposed to a bowl of alphabet soup: OLE DB, ADO, ODBC, RDO, DAO, and so on. And beyond those, many other APIs are used to access things like telephony, e-mail, and file systems. They're all related to getting some kind of information, or data.
This is where Microsoft's data access strategy, Universal Data Access (UDA), comes in. It is designed to provide access to all types of data through a single data access model. To understand the importance of this strategy, consider the following typical scenario.
Suppose that you are the project manager responsible for delivering a prototype of the new space shuttle. To prepare for a status meeting, you need to collect information from a variety of sources. And because Microsoft® Project does a great job of managing scheduling information, you already have a number of project files that describe who is allocated to what tasks, whether they are ahead or behind schedule, and so forth.
Reviewing the project, you see that the team responsible for the propulsion unit has continuously added resources to the project but is continuing to fall behind. After identifying the tasks that are causing the team to slip, you do a search on the technical documents describing those tasks. From the information obtained in the technical documents, you do a search of your e-mail folders to find all the related mail that discusses the project and the potential cause for it falling behind. You find a message that refers to a delay in receiving some critical parts for the thruster. The millions of parts that make up the shuttle are inventoried in a SQL Server™ database, so you search for the subset of parts used for the thruster and then compare that to your invoices, which are kept in a Microsoft Access database. After finding the invoice for the missing parts, you do a Web search for information about the supplying manufacturer and discover that they were involved in a takeover two months before the invoice due date. Further searching on the Web reveals two other companies that manufacture the same components.
Now that you've collected all the information from various resources, discovered the reason for the delay, and struck a quick deal with one of the other manufacturers, you want to make some changes.
First you want to update all of the parts from the old manufacturer to the new supplier. To make this change, you need to update information in your inventory database, the project specification, and outstanding invoices. You have to make these changes to all sources of data that are related to the project in a safe way. You don't want the changes to be applied in two places and fail in the other two. You need the same type of transactional semantics you get in a single data store, even if the data is located in different containers.
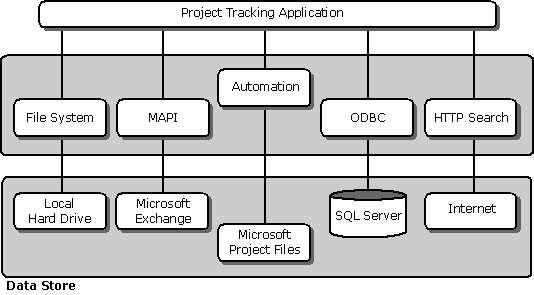
So how might this work? you would probably have a project-tracking application to display and analyze project information. (See the following illustration.) The project-tracking application would use Automation to get to the high-level project information stored in the Microsoft Project files. Then you'd use file system interfaces to search for documents on your hard drive, MAPI to get information from the Microsoft Exchange data store, ODBC to get information from the SQL Server, and some HTTP search protocol to find information on the Internet.
In this case, the project-tracking application utilizes at least five separate APIs to access the different types of data. Some of the interfaces are COM interfaces, and some of them are not; some of them expose Automation interfaces, and some are procedural. In addition, transactional control does not exist, so you cannot safely make any changes to all of the information within one transaction.
What all of this means—that is, the unfortunate outcome of the preceding scenario—is that the developers who write the project-tracking application will have to become experts in a multitude of data access methods.
Is there a better way? Well, one solution is to put all of the different types of data into a single relational data store. That is, take the SQL data store and incorporate the project data, e-mail data, directory data, and information from the Internet and move it into a single vendor's relational database. This approach solves the problem of needing a single API that also gives you transactional control—but it has a number of compromises, as well as some development hurdles to clear.
First, it requires moving huge amounts of data. Second, you typically don't own much of the data you need, such as the wealth of information on the Internet. The next problem with moving the data into a single data store is that tools today don't look for or store data into a single relational data store. E-mail applications, project management tools, spreadsheets, and other tools look into their own data stores for their data. You'd have to rewrite your tools to access the data in the single data store or duplicate the data to the single data store from where it naturally lives—then you run into problems with synchronizing the data. Another problem is that one size does not fit all. The way that relational databases deal with data is not the best way to deal with all types of data, because data (structured, semi-structured, and unstructured) is stored in different containers based on how the data is used, viewed, managed, and accessed. Finally, the performance and query requirements are going to differ by data type, depending on what you are trying to do.
So if you can't have all of your data in a single data store, what's the alternative? The answer is Universal Data Access. With Universal Data Access, you get to data in different data stores through a common set of interfaces, regardless of where the data resides. Your application uses a common set of system-based interfaces that generalize the concept of data.
To achieve this breakthrough in its data access strategy, Microsoft examined what all types of data have in common, such as how you navigate, represent, bind, use, and share that data with other components. The result is a set of common interfaces that anyone can use to represent data kept in relational databases, spreadsheets, project and document containers, VSAM, e-mail, and file systems. The data stores simply expose common interfaces—a common data access model—to the data.
Microsoft has solicited extensive feedback from data access customers on the criteria they use in judging and selecting data access technologies and products and has learned that there are four main criteria used in the decision-making process:
In a nutshell, companies building client/server and Web-based database solutions seek maximum business advantage from the data and information distributed throughout their organizations. Microsoft's Universal Data Access Strategy meets all the criteria listed above and more:
As mentioned earlier, a major strength of the Microsoft Universal Data Access strategy is that it is delivered through a common set of modern, object-oriented interfaces. These interfaces are based on the Microsoft Component Object Model (COM), the most widely implemented object technology in the world. COM has become the choice of developers worldwide because it provides the following advantages:
Because of the consistency and interoperability afforded through COM, the Microsoft Universal Data Access architecture is open and works with most tools and programming language. It also provides a consistent data access model at all tiers of the modern application architecture.
The Microsoft Universal Data Access architecture exposes COM-based interfaces optimized for both low-level and high-level application development by using OLE DB and ADO, respectively.
Performance is of paramount concern to developers and users of data access technologies. Therefore, Universal Data Access has been designed with performance as its number one goal. This section will examine how the Universal Data Access technologies—ODBC, OLE DB, and ADO—all bundled within the Microsoft Data Access Components (MDAC) SDK, support this requirement and the positive implications for users.
Ultimately, the performance of Microsoft Data Access Components will be judged in comparison with that of native access methods. The goal is to establish OLE DB as the native interface to major Microsoft and non-Microsoft data stores. To accomplish this, performance tuning for all key scenarios (transactions, decision support, and so on) and with major data sources will be of paramount concern. The number one design goal for ADO and OLE DB is performance, and the architectural foundations to achieve this are in place.
Universal Data Access is a strategy that includes and builds on the successful foundation of ODBC. ODBC successes include the following:
ODBC continues to be a cornerstone of the MDAC architecture.
As one of the principal MDAC technologies, OLE DB represents an ongoing Microsoft effort to define a set of COM interfaces to provide applications with uniform access to data stored in diverse information sources. This approach allows a data source to share its data through the interfaces that support the amount of DBMS functionality appropriate to the data source. By design, the high-performance architecture of OLE DB is based on its use of a flexible, component-based services model. Rather than having a prescribed number of intermediary layers between the application and the data, OLE DB requires only as many components as are needed to accomplish a particular task.
For example, suppose a user wants to run a query. Consider the following scenarios:
In all four of the preceding examples, the application can query the data. The user's needs are met with a minimum number of components. In each case, additional components are used only if needed, and only the required components are invoked. This demand-loading of reusable and shareable components greatly contributes to high performance when OLE DB is used.
As with OLE DB, ADO is designed for high performance. To achieve this, it reduces the amount of solution code developers must write by "flattening" the coding model. DAO and RDO, the object models that preceded ADO, are highly hierarchical models—that is, to return results from a data source, the programmer has to start at the top of the object model and traverse down to the layer that contains the recordset. However, the ADO object model is not hierarchical: The ADO programmer can create a recordset in code and be ready to retrieve results by setting two properties; the programmer can then execute a single method to run the query and populate the recordset with results.
The ADO approach dramatically decreases the amount and complexity of code that needs to be written by the programmer. Less code running on the client or middle-tier business object translates to higher performance. ADO also offers better performance in getting data from recordsets. Scalability is improved by minimizing overhead in simple scenarios.
Microsoft has designed OLE DB and ADO for the Internet, implementing a "stateless" model in which client and server can be disconnected between data access operations. The MDAC SDK contains a Remote Data Service component that provides efficient marshaling of data between the middle tier or server and the client, including support for batch updates and an efficient client-side cursor engine that can process data locally without constant server requests. Thus MDAC provides greater local functionality and higher performance for Internet applications than other approaches.
The Windows Distributed interNet Applications architecture is the Microsoft architectural framework for building modern, scalable, multitier distributed computing solutions that can be delivered over any network. Windows DNA provides a unified architecture that integrates the worlds of client/server and Web-based application development. Microsoft Universal Data Access, a central part of the Microsoft Windows DNA strategy, provides data access services for Windows DNA applications.
Windows DNA addresses requirements at all tiers of modern distributed applications: user interface and navigation, business process, and integrated storage. The core elements of the Windows DNA architecture are as follows:
Because Microsoft Universal Data Access is based on COM, it provides a unified, consistent, and common data access model for all applications built to the Windows DNA model.
Reliability is a primary requirement for organizations managing and supporting data access applications. Universal Data Access aims to address this need in three areas:
The net result of the Universal Data Access architecture's three-pronged approach should be significant reductions in configuration and support expenses and a reduced total cost of ownership—in short, a reliable data access architecture.
One of the most important ways that organizations can increase reliability and decrease support costs is by reducing the number of components to support on client PCs. The Universal Data Access strategy and the Microsoft Data Access Components technologies support this approach by offering the following advantages:
Universal Data Access enables transactional control of diverse data sources and components by using Microsoft Component Services (or MTS, if you are using Microsoft Windows NT®). To achieve this, OLE DB data sources must implement the functionality of a resource manager, which handles transactions local to the data source and enables each data source to participate in distributed transactions. Microsoft Component Services provides a distributed transaction coordinator that guarantees atomic operations spanning multiple data sources, using a reliable, two-phase commit protocol, and enables applications to scale, with minimal additional effort, as the user load grows.
MDAC components are rigorously tested for reliability. Because ADO and OLE DB have been shipping in high volume since the release of Microsoft Internet Information Server 3.0, they have enjoyed significant field usage. With the advent of MDAC, and the commitment to ship ADO and OLE DB in a synchronized fashion, these components are now developed and tested side by side.
After testing the components for interoperability, to guarantee reliable behavior in multithreaded, continuous-operation conditions in highly concurrent environments, Microsoft stress-tests the MDAC technologies with the products with which they ship (such as Internet Information Server and Internet Explorer). This stress-testing is designed to help ensure high-performance, highly reliable components that work well in a variety of real-world scenarios.
The choice of data access technologies is extremely strategic for organizations. Typically, internal factors, such as an organization's existing DBMS, largely drive this choice. However, customer surveys have indicated that data access decisions are made for the long haul and therefore need to be considered carefully.
Following are some of the questions that customers want answered when evaluating a data access vendor:
Based on market share, developer acceptance, and broad industry support for many technologies, Microsoft answers "Yes!" to all these questions. Microsoft has consistently met this set of criteria and has proved to be a market leader for data access technology.
A look at how the Universal Data Access strategy has evolved at Microsoft will help illuminate the long-term commitment the company is making in this area.
Microsoft began investing in data access shortly after the initial release of Microsoft SQL Server 1.0 in 1989. Initial interest in Microsoft SQL Server was high, but the tools available to program it were limited. The SQL standard was in its infancy but was clearly bound to the coming client/server revolution. Microsoft knew that acceptance of client/server architecture would be highly beneficial and could see that the biggest problem the industry faced was the proliferation of data access interfaces—and the complexity of creating, maintaining, and programming against them.
Open Database Connectivity (ODBC) was the result of these factors, and the following important features made ODBC extremely attractive:
As ODBC gained broad support as a standard for data access, it became clear that a standards body should be defining its future. Microsoft turned over the specification for ODBC to the SQL Access Group, made up of a broad range of DBMS, middleware, and tools vendors.
Despite its advantages, ODBC had a number of shortcomings, which by 1993 were being addressed in the next phase of data access market development. ODBC was programmed as a Windows-based API, which made it difficult for the majority of customers to use it. A number of Microsoft tools and applications could use ODBC through the Microsoft Jet database engine, but ODBC functionality was not extensible except for a few API-level programmers. Therefore, high-level programming models were created—first Data Access Objects (DAO) and then Remote Data Objects (RDO)—that simplified the ODBC programming model and made it accessible to a wider range of programmers.
DAO provided Microsoft Access and Microsoft Office programmers with an interface to the Microsoft Jet database engine, and RDO provided higher-level interfaces to ODBC for programmers using the Microsoft Visual Basic® programming system. These interfaces were natural extensions to the Visual Basic language used in each of these products and have gained broad usage among database programmers.
By 1995, two major new trends began to shape the next phase of development. These two trends, which are still evolving, were the rise of the Internet as a database applications platform and the rise in importance of nonrelational data, which does not directly fit the database model encapsulated by ODBC.
The Internet presents new data access challenges on many levels, including as the following:
As mentioned above, while the Internet catalyzes a major paradigm shift in database management and data access, a related shift is occurring: the emergence of nonrelational data sources. While the Internet highlights the need for management of textual and graphical data, organizations today also face a proliferation of data in a variety of DBMS and non-DBMS stores, including desktop applications, mail systems, workgroup and workflow systems, and others. Most established organizations face an even larger challenge: leveraging the data in mainframe and minicomputer flat files as they extend access to this information to intranet-based and Internet-based customers.
Data access today encompasses all of the issues traditionally addressed by DBMS systems, plus a range of new data types, new clients, and new access methods. Therefore, with its Universal Data Access strategy, Microsoft has taken another step forward to meet this new generation of challenges, leveraging the successful strategies of the past and embracing the architectures of the future.
ODBC continues to be a supported technology under the Universal Data Access umbrella. Due to the high number of drivers available, ODBC in the short and medium term is the best way to access a broad range of relational DBMS-based data. With ODBC remaining as a mature technology and OLE DB components becoming available, Microsoft does not want to force customers to choose between the two architectures and make the ensuing trade-offs. The goal is to enable customers to take advantage of existing ODBC technologies while adopting the Universal Data Access architecture for new applications.
The most frequent customer issues surrounding ODBC are related to performance and configuration management, defined as matching database drivers on multiple machines with multiple back-end data sources. Microsoft is aware of these issues and will continue to address them through subsequent ODBC releases, including a new and significantly improved ODBC driver for Oracle.
It was by design, in response to consistent customer feedback, that the evolutionary strategy for migrating from ODBC to OLE DB was created. The very first OLE DB provider released by Microsoft was the OLE DB Provider for ODBC, allowing applications to be written to the ADO or OLE DB interface, with the OLE DB Provider for ODBC then connecting to the ODBC data source. So now if an organization wants to change data sources, add data sources, or change from the ODBC driver to a pure OLE DB provider for the existing data source, the existing database application can be adapted with minimal changes.
This strategy for migrating from ODBC to OLE DB carries some additional important benefits: OLE DB and ADO service component features may be invoked against ODBC data. For example, the ADO Find method provides for sorting and filtering within a result set. Therefore, the result set can be reused and further refined, without an additional round-trip to the server, a capability unavailable to an ODBC client. This means that both new and existing applications can gain additional data access features by using OLE DB to call broadly supported ODBC drivers.
Organizations should continue to plan on broad availability and support for ODBC drivers. And as they build new applications, they should look to the Universal Data Access architecture, using ADO and OLE DB interfaces. For relational data, organizations may choose between ODBC drivers and, as they become available, OLE DB providers and components. And because of the ability of OLE DB providers to expose nonrelational data, Microsoft believes customer demand will drive the market for OLE DB components and that they, too, will become broadly available. In the long term, able to freely choose among and mix ODBC and OLE DB components, organizations will benefit from the highest possible application performance and reliability while gaining new capabilities at a pace that suits their unique requirements.
The Universal Data Access strategy is intertwined with most of the major lines of business where Microsoft is serving organization customers, including operating systems, tools, applications, and Internet products. Universal Data Access is designed to work consistently across each of these major product lines, enabling organizations to leverage their data access expertise across teams and projects to build high-performance database solutions accessible to employees, customers, and business partners.
Also, making integrated access to all forms of relational and nonrelational data ubiquitous is strategic for Microsoft products because it enables those products to add value through tools that use the Universal Data Access architecture. Customers are the ultimate beneficiaries as their tools and applications become more highly adept at processing the information they work with every day.
To justify investment in the Universal Data Access architecture, organizations using data access components want to see the support of vendors of related products and technologies. For customers, broad industry support carries many benefits—safety in numbers, availability of skilled people to work with the products, and products that work together without expensive integration and customization.
The industry reception for Microsoft's Universal Data Access strategy has been very positive. This section details the activities in which Microsoft is engaged to solidify and publicize the broad range of companies supporting Universal Data Access.
The key industry segments supporting Universal Data Access are as follows:
The list of vendors in each of the above categories is growing rapidly. Visit the Universal Data Access Web site for a complete, updated list. Leading vendors in each industry segment are represented in the list of Universal Data Access supporters.
To be successful, OLE DB must gain a broad array of native providers and components so that users can connect to practically any data source, reuse OLE DB service components, and realize performance and reliability benefits.
The tools that OLE DB provider and component vendors use to simplify their work are found in the MDAC SDK. In addition to the data access consumer components discussed in this paper (ADO, OLE DB, and ODBC), users of the SDK receive additional tools, documentation, and specifications to help them create high-performance OLE DB components. Provider writers will find the following:
These tools simplify the process of writing OLE DB components, provide a framework for creating components that interoperate in well-defined ways, and provide criteria by which OLE DB consumers can easily compare component features. Anyone interested in creating OLE DB components should obtain the MDAC SDK.
Note Another useful tool for provider developers is the set of Microsoft Visual C++® development system template classes for OLE DB providers. These are a part of Visual C++ and are not actually included in the MDAC SDK.
While the Microsoft Windows NT/Windows® 2000 operating system is emerging as an important platform for database management, many organizations rely on a mixture of operating systems and database platforms. To be successful, any strategy for providing data access must be able to efficiently access data on all major platforms. To that end, Universal Data Access provides the foundation for supporting efficient and reliable access to data on today's major computing platforms. Microsoft is actively engaged in supporting third-party development projects involving OLE DB providers for non-Windows-based data. Products using the Universal Data Access architecture to access leading DBMSs on non-Windows platforms are currently available from many companies, including International Software Group (ISG), MERANT, and Simba Technologies.
Because the OLE DB specification defines interfaces that components support, rather than providing a set of DLLs or actual system components, it is highly portable to other operating environments. Because OLE DB is based on the COM architecture, it might be inferred that OLE DB components must run on a Windows-based PC—but this is not the case. OLE DB has two separate approaches that provide portability to non-Windows-based DBMS platforms:
The broad availability of MDAC components that integrate data on multiple platforms will benefit organizations that support multiple DBMS platforms. Users can continue to take advantage of new OLE DB capabilities, even when accessing non-Windows-based data. Powerful new service components, running on non-Windows platforms—on front ends or middle-tier servers—can be integrated with an OLE DB provider. For example, general-purpose query processors, cursor engines, or custom business objects can all add value to non-Windows-based data exposed by OLE DB. Mainframe and UNIX-based databases that previously did not support remoting of data—an essential feature for the Internet and loosely connected scenarios—may now implement it, gaining greater use from existing systems and applications.
A number of leading DBMS vendors have begun shipping new databases and updated versions that follow data-centric database strategies—that is, consolidation of the dispersed data into a single database. Customers may be curious about how those strategies differ from Universal Data Access.
In the other approaches, data from across the organization is consolidated in the DBMS, and the DBMS is extended with additional processing capabilities to handle new data types. This strategy can be attractive for several reasons:
Microsoft, while recognizing these benefits, believes they may be difficult for some organizations to attain. A data-centric database approach may require expensive and time-consuming movement to, and maintenance of, corporate data in the DBMS. It may require tools and applications to support it. And it may require compromises in the selection of supporting products. Customers' applications will need to either implicitly support this architecture, which is unlikely, or be customized to integrate with it, which could be expensive.
Because the Universal Data Access strategy does not exclude any data stores, it can cooperate with the data-centric model if necessary. In fact, OLE DB providers for a number of new data-centric database products are currently under development. Customers can use the Universal Data Access strategy to access data in their existing databases, data-centric database servers, desktop applications, mainframes, and so forth. Organizations that combine Universal Data Access and data-centric database products will ultimately benefit from a broad choice of best-of-breed tools, applications, and DBMS products available from leading data access vendors.
The following sections are intended to help you, the developer or information management professional, choose the data access strategy that is best for your organization and your customers.
ODBC has been a very important and successful data access standard. The ODBC technology and third-party market have matured to a point where ODBC is an ideal technology for accessing SQL databases. On the other hand, OLE DB has an improved architecture that provides a significant advantage over ODBC because providersno longer have to implement a SQL relational engine to expose data. And an integral part of OLE DB is an OLE DB driver manager that enables OLE DB consumers to talk to ODBC providers.
With ODBC, services such as cursoring and query processing need to be implemented by every ODBC driver writer. This represents overhead both for the ODBC driver author and for the end user. With OLE DB, reusable service components handle the processing chores for a variety of data providers.
OLE DB simplifies the process of writing data providers, which means they should come on line faster and be of a higher quality. It also reduces the number of components installed on data consumer machines.
Use the following tips to guide your choice of which technology to use:
Technical differences between ODBC and OLE DB are summarized in the following table.
| ODBC | OLE DB |
| Data access API | Database component APIs |
| C-level API | COM API |
| SQL-based data | All tabular data |
| SQL-based standard | COM-based standard |
| Native providers | Component architecture |
As application developers move to solutions designed as reusable components, OLE DB enables business-centered components to behave and communicate like mini-databases, both as data consumers and as providers. This capability is the basis for new, simpler ways to build applications based on components.
This capability extends across corporate data as well as Internet data, and across all types of data providers beyond SQL databases.
When a developer uses a tool or language that supports OLE DB, different data sources can behave as a single, homogeneous source. From ADO, developers can create business applications that link many data sources.
Business components can excrete data change events, consume OLE DB data, and provide OLE DB data. In this way, business components can perform very complex processing and synchronize with other components while exposing simple, table-like interfaces.
Most graphical development tools automate loading result sets from queries directly into visual controls. Today, calling components requires more programming to access the result set and load the visual controls.
OLE DB is a useful technology in its own right, but it becomes even more compelling as the broad suite of Microsoft enterprise tools and technologies integrate and extend one another's capabilities.
OLE DB data consumer tools and languages have full access to all ODBC drivers and ODBC-based data.
ADO is now the standard data access language for Microsoft tools. The current versions of Internet Information Server, Internet Explorer, Visual Basic, Visual InterDev®, Visual C++, and Microsoft Visual J++®, have all been written to use ADO as their primary data access language.
Among the many benefits of ADO is a common language for accessing data. Whatever tool you are using, you can use the same code to query and manipulate data. This allows for much greater and easier code reuse across applications than was possible in the past.
Therefore, if you are designing an application now, you should use ADO, unless there are features you need that are not available in ADO but are available in one of the alternative technologies.
If you are using DAO or RDO, you should still think about how to move over to ADO when it supersedes these. That way, when the time comes, you will have an easier job migrating to ADO.
Following are scenarios in which you might still want to use DAO:
Following are scenarios in which you might still want to use RDO:
To help you decide which technology to use and also to determine if ADO meets your needs today, the following table presents a list of major features found in ADO, DAO, and RDO. ("X" indicates that the feature is present.)
| Feature | ADO 2.5 | DAO 3.6 | RDO 2.0 |
| Asynchronous connect | X | X | |
| Queries run asynchronously | X | X | |
| Batch updates and error handling | X | X | X |
| Disconnected recordsets | X | X | |
| Events | X | X | |
| Integration with data binding in Visual Basic 6.0 | X | ||
| Integration with Visual Basic/Visual C++ Transact-SQL Debugger | X | ||
| Data shaping | X | ||
| Persistent recordsets | X | ||
| Distributed transactions | X | X | |
| Thread-safe | X | X | X |
| Free-threaded | X | ||
| In/out/return value parameters | X | X | X |
| Independently created objects | X | X1 | X |
| Queries as methods | X | X | |
| Multiple recordsets returned | X | X | X |
| Efficient Microsoft Jet database access | X2 | X |
1 DDL objects
2 Using the OLE DB Provider for Microsoft Jet