MDAC 2.5 SDK - Technical Articles
March 1999
By Greg Smith
The Client Cursor Engine, or CCE, is an OLE DB (COM) rowset implementation that ships with ADO/RDS and OLE DB. It is the heart of the client-side cursor in ADO, a crucial piece of the remoting infrastructure in RDS, and the core object in the OLE DB Cursor Service. It is also the rowset implementation integrated into the Data Shaping Service for OLE DB.
The root mission of the CCE is to be the premier lightweight, remotable cache for client-size structured data chunks, providing fast and rich scrolling, sorting, filtering, shaping, and updating. It is an independently instantiable OLE DB rowset object, implementing all of the required rowset interfaces, many of the most interesting optional interfaces, and several unique interfaces that might make their way into future versions of the OLE DB specification.
An understanding of optimistic remote updating and its implementation in the Client Cursor Engine will help developers gain some useful insights into the actual updating results in any given real-life situation. Likewise, customers can use information about the update process in the CCE to help them better design their own projects for efficient updatability.
Updating plays a crucial role in projects in which the CCE is a component, and it often entails a highly complex and dependent behavior. In optimistic remote updating, the key to the complexity is that the CCE does not "own" the data it is ultimately updating. Instead, the data is owned by some specific provider, and the CCE must submit update requests in the form of SQL commands. (This is also sometimes referred to as query-based updating, or QBU.) Until these commands are successfully executed, all user-initiated changes are cached on a local copy of the remote data, in the CCE rowset object. At the moment that this local copy of the remote data is first generated—by fetching from the back-end database or reading from an HTTP stream—it is already stale, at least potentially. This is the nature of optimistic updating—for performance and scalability reasons, no server locks or resources are held that would enable the CCE to prevent or detect other users' concurrent changes. As a result, most of the difficulty in this type of multi-tier updating occurs because the component (the CCE) that answers to the user cannot guarantee that any update operations the user has performed locally will be successful by the time they are submitted to the back-end database. Failures can be caused by reasons as various as connectivity errors, metadata changes, data conflicts, permission violations, and so forth, and resolving these errors gracefully takes a high degree of flexibility and well-designed default behaviors.
The current body of CCE code, considered to be the "updating code" responsible for translating rowset changes into SQL commands, consists of three sections:
The update properties provide extra information about the structure of a result set and enable the CCE to perform updates on the constituent tables of that result set. Essentially, each update property describes the relationship between a result set field and the true back-end base table field that the result set field represents. Property gathering is performed as the original result set is first fetched into the CCE. Along with the data, the gathered properties are stored internally and used when the command to attempt a back-end update is given. (If the CCE rowset is opened read-only, no attempt is made to gather or store the update properties because they will never be used.)
Update properties can be gathered in one of the following ways:
Gathering the properties is tried first by using IColumnsRowset. If that approach fails to provide a coherent picture of the required properties or is unsupported in optional portions of the implementation, the fallback method is to parse the SQL statement.
IColumnsRowset is an OLE DB interface that provides methods designed to get more information about the columns of a result set than is available from the simpler IColumnsInfo interface. (See IColumnsRowset in the OLE DB Programmers Reference for more information.) The CCE fetches its data from an underlying provider rowset with the IRowset interfaces, and as part of the fetching process, this rowset is queried for whether it supports the IColumnsRowset interface.
The following extended column attributes together provide all the properties necessary for updating:
The first four properties listed above are part of the original OLE DB specification, and the last (DBCOLUMN_KEYCOLUMN) was added in the 2.0 version. These properties are all currently part of the "optional metadata columns" returned by IColumnsRowset.
For the CCE, the first two properties (DBCOLUMN_BASECOLUMNNAME and DBCOLUMN_BASETABLENAME) are the only ones required when attempting an update. The second two properties (DBCOLUMN_BASESCHEMANAME and DBCOLUMN_BASECATALOGNAME) are essentially scoping qualifiers to the table name and might not be necessary for unique table identification in a given context with a given server. Finally, the key column information (DBCOLUMN_KEYCOLUMN) assures that a change intended to affect a single row does not inadvertently affect multiple rows on the server. (See the section "Row Identity," later in this document.)
If the IColumnsRowset method of gathering metadata fails, it will be necessary to parse the SQL statement. Any one of the following conditions will cause the CCE to abandon IColumnsRowset and proceed to parsing the SQL:
If DBCOLUMN_BASESCHEMANAME and DBCOLUMN_BASECATALOGNAME are not offered on the columns rowset or are reported to have NULL values for every result set column, schema and catalog qualifiers are presumed to be unimportant in the current context. If DBCOLUMN_KEYCOLUMN is not offered on the columns rowset or is reported to have a NULL value for every result set column, the CCE will record this fact and try the alternate IDBSchemaRowset method of gathering key information, as described in the following section.
Note If the DBCOLUMN_KEYCOLUMN values are all Boolean FALSE—as opposed to NULL—that means no keys were present in the result set. There is no follow-up with IDBSchemaRowset as in the NULL case.)
If, by using IColumnsRowset, the attempt to obtain the required attributes fails, it will be necessary to parse the SQL statement. (This parsing model is appropriated from the Microsoft® Visual FoxPro® remote view design and is the only method available in Visual FoxPro to acquire update properties.) This method involves reading through the SQL statement that generated the result set, in an effort to interpret the semantics well enough to build the relationships between result set fields and fields in the base tables that constitute the elements of the result set.
The CCE attempts to determine the SQL text by using the IRowsetInfo::GetSpecification method to get to the command object used to create the rowset, and by using the ICommandText::GetCommandText method on this command object to get the SQL text. If that operation succeeds, parse the SQL statement using the following steps:
When successful, this parsing procedure provides the first two attributes required by the CCE for updating: base table name and base table column name. When present in the qualification of the table name (for example, "PUBS.DBO.AUTHORS"), the third and fourth attributes (schema and catalog) are collected as well. The fifth attribute, key column information, is then obtained through the OLE DB IDBSchemaRowset interface. This entails requesting the "primary key" schema rowset for each base table, which provides a list of primary keys. If this rowset is unavailable or empty, a list of unique indexes, which are then treated as the key columns, can be obtained by requesting the "indexes" schema rowset for each base table.
When supported, the IColumnsRowset method is by far the superior alternative. It is currently supported by the Microsoft OLE DB providers for Oracle, SQL Server, and Microsoft Jet 4.0, and by the Cursor Service for OLE DB. Additionally, it is supported by the OLE DB Provider for ODBC when working with SQL Server databases (through the SQL Server ODBC Driver). For some providers, gathering this information is somewhat expensive and should not be done in cases where it won't be used. To this end, the OLE DB specification was extended to include the DBPROP_UNIQUEROWS rowset property, to be set on a provider rowset or command object before the rowset is opened. A value of 'TRUE' indicates that this extended metadata is important to the rowset consumer and that it should be provided if possible. The MDAC components that use the CCE for cursoring services (Service Components, ADO, and RDS) automatically set this property on the provider before invoking the CCE for updatable rowsets. With the providers for Oracle and SQL Server in particular, the required IColumnsRowset data will be unavailable unless DBPROP_UNIQUEROWS has been set beforehand.
The parsing method may be more generically available for SQL-based providers, because getting base table and column information requires only that a provider can execute SELECT statements, which is the way many result sets are generated in the first place. But the parsing method is useless for result sets where the SQL text is unavailable. Indeed, aside from whether or not a provider even implements the interfaces that allow the CCE to retrieve the defining SQL, there is no guarantee that the result set was generated by SQL in the first place. It might instead be the result of a stored procedure call or an OLE DB IOpenRowset call, or it might be a rowset from a non-SQL-based provider such as the file system.
But the main drawbacks to the parsing approach are brittleness and performance. The parsing approach is brittle because of the lack of a full-blown SQL parser (which would create an unacceptable level of overhead) that could unambiguously determine the shape of the result set from the SQL text. That is, there are many statements above a certain level of complexity, or containing provider-specific language, in which the parser built into the CCE gets lost and must give up.
Performance, using the parsing approach, varies widely under different circumstances and in some cases may be unacceptable. The problem is not in the CCE itself but in the wide range of potentially expensive calls it makes back into the provider. The first performance hit is caused by the set of "SELECT *" calls that the CCE makes on base tables to get the base table structures. Not only does this produce the provider-specific overhead of result set generation but, because some providers and drivers (notably Access ODBC) are not equipped to optimize for "WHERE 1=0", all the data is generated as well (only to be discarded). The second major hit comes with the catalog functions that implement the key column attributes. On some providers and drivers (notably Oracle ODBC), the key functions can be incredibly expensive (ranging from 15 to 30 seconds).
Therefore, while parsing works well and is time-tested in a large number of common cases, it is by no means foolproof.
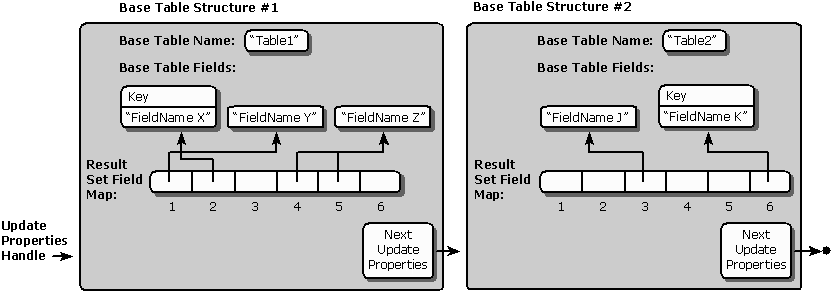
The internal update property structures are important because their design dictates many aspects of the behavior of the rest of the updating code. The way in which update properties are stored determines which operations will be efficient or expensive and which base table or result set relationships are ambiguous or easily dealt with. The basic information that needs to be stored is the set of mappings between a result set column and the base table columns to which the result set column corresponds. The following diagram illustrates these mappings.
Internal update property structures
The diagram shows the mappings from a 6-column result set selected from two base tables. The update properties handle points to the first base table structure (Base Table Structure #1). In this first structure, four fields—1, 2, 4, and 5—of the 6-column result set are mapped to three fields—"FieldName X", "FieldName Y", and "FieldName Z"—of "Table1". Two of the result set columns—4 and 5—derived from "Table1" actually represent the same base table column, "Table1.Z". Base Table Structure #1 links to the next base table structure (Base Table Structure #2). In this second structure, two fields—3 and 6—of the 6-column result set are mapped to two fields—"FieldName J" and "FieldName K"—of "Table2". Since Base Table Structure #2 does not link to any other base table structures and all the result set fields are mapped to base tables, the mapping ends.
The update properties are organized by base table and encoded into a linked list of base table structures. In this way, a pointer to the head base table in the list can be passed around freely as a "handle" to the entire set of update properties. Each field in the result set has a corresponding field structure in at most one of the base table structures. Some fields (such as calculated columns like those created by "SELECT Price * Quantity AS Total FROM Orders") have no single base table field to which updates can reasonably be applied, so those fields have no update properties and are not represented in the base table field structures.
The base table field structures contain the minimum information about base table columns that is needed to correctly update them. This includes the name to update with (when columns are aliased, this name might not be the same as the result set name) and whether it is a key column. The "Field Map" has an entry for each result set column—the entry either points to a base table field structure (indicating a one-to-one correspondence) or is empty (indicating no correspondence within this base table).
In the CCE, remote updates are performed by traversing the changed rows in the rowset, analyzing the local changes, and then executing corresponding SQL statements (DELETE, INSERT, and UPDATE) directly against the provider's base tables. (This update model is based on code that has shipped in Microsoft Visual FoxPro for many years.)
The internal property structures (described earlier in the section "Internal Update Property Structures") make updating by base table fairly efficient. The first task in updating is to determine what columns in what base tables will be affected and then to send out column modification statements table by table. A standard UPDATE statement for a given base table must describe the following:
Nearly the same procedure is followed for INSERT and DELETE statements, except that these statements require only half the work of an UPDATE statement. INSERT statements just need to describe the inserted columns (as in item 1 of the preceding list), and DELETE statements just need to describe the row to be deleted (as in item 2).
In generating the text of the SQL statement, the gathered properties (from the metadata-gathering phase) map to the output statement in a straightforward way. The table to be affected by the operation is generated from any and all names and qualifiers corresponding to SCHEMANAME, CATALOGNAME, and TABLENAME that have been collected while gathering the update properties. These are strung together according to the reported qualifying character on the underlying OLE DB session object (DBLITERAL_CATALOG_SEPARATOR).
Note DBLITERAL_SCHEMA_SEPARATOR was not part of the original OLE DB specification and is not yet supported. A period (.) is automatically used for schema separation.
The column names inside the SQL text are simply the names collected as COLUMNNAME during the gathering of update properties.
Note To allow for the most robust use with more complicated extended character sets (for example, Japanese), every identifier that is placed into the statement text (table, schema, catalog, and column) is first wrapped in the quote character specified as DBLITERAL_QUOTE on the underlying session object.
The column values placed into the text are parameterized—that is, a question mark is inserted as a value placeholder (for example, "WHERE au_id = ?") and the actual value is sent out-of-band as strongly typed parameter data. The primary motivation for this is that the command parameter mechanism in OLE DB provides rich description of the parameter value and type and allows precision to be preserved much more consistently and cheaply than when values are converted back and forth into raw text.
The CCE code first gathers a list of columns (in the form of a bitmap) that have changed in the result set for the row being updated. Then, for each base table in turn, the changed-column list is masked with the base table field map to get the set of columns to update for this base table. The resulting subset of columns is then iterated, inserting the base table field names and the new column values into the SQL statement and parameter list one by one.
In a disconnected environment, unambiguously identifying which back-end row to update is problematic. The time-honored method in an SQL context is to treat particular fields of a given row's data (the key fields) as uniquely characterizing that row. The idea is that the key for a given record rarely, if ever, changes, so it can be used as an identifier for the row in which to make updates to the non-key fields. Therefore, in the CCE, the key fields are used in the WHERE clause to identify the row update. Without key information for all of the base tables in a result set, attempting to update causes an error. The sole exception to this is a single-table query, where an update is attempted by sending every available (non-long-valued) column in the WHERE clause. This ability should be used cautiously because if the existing row values are not enough to uniquely identify the row, multiple rows will be affected by the update—an error will be generated, but any damage done must be undone manually.
The importance of being able to gather key field information for uniquely identifying rows should not be underestimated: Deliberate key-field support is a hallmark of good database design and is crucial in a disconnected environment. Of course, as a data tool, the CCE always has the goal of avoiding the enforcement of "arbitrary" restrictions on the updatability of a result set—it would be unfortunate to completely disable updating simply because of a poorly formed query or an incomplete back-end database design. This was the motivation behind the loophole described above—permitting updates to single tables without keys. But it is important to keep in mind that the more these restrictions are relaxed, the less predictable the update behavior becomes. Consistently using key fields in base tables and including them in the result set projections is the only way to be confident that a one-row change in the CCE will effect a one-row (per base table) change on the back end.
Beyond its use as a row identifier, the WHERE clause is also used to detect optimistic concurrency conflicts—to compensate for the disconnected nature of the user's local data copy.
In a multi-tier, optimistic-locking environment, in the absence of some server-change notification system, the user is forced to assume ("optimistically") that the field values with which he or she is working locally have not been changed on the server by another user working concurrently. Of course, whenever any time has elapsed between the read operation (fetch) and the write operation (update), that assumption can be wrong. Therefore, the user needs some way of guaranteeing that each update is performed on back-end data that has not meanwhile been changed beyond some specific level of acceptability, and the WHERE clause can be used for this purpose.
The approach taken in the CCE is to insert additional identifying fields and their original values in the WHERE clause—fields that the user is assuming haven't been changed yet by other users. If any of the fields have changed, the back-end engine will presumably be unable to find a row matching the obsolete identifying criteria and the update will not be performed.
Because the degree to which conflicts need detecting is a dependent quantity with no single correct value, the question of which extra fields to include—in addition to the key fields—should be left to the user. Currently, the CCE allows for the following options via the provider-specific DBPROP_ADC_UPDATECRITERIA property:
Long-valued columns (sometimes called BLOBS, memos, or TEXT columns) are not included in the WHERE clause because most providers do not support comparison operations on these columns.
Note For more information about the DBPROP_ADC_UPDATECRITERIA property, see Supported Properties of the Cursor Service in the Cursor Service for OLE DB documentation in the MDAC SDK.
Each update statement sent represents a negotiated communication between the CCE and the server. Given the desire to provide good performance over a large set of network layouts and server capabilities, the potential expense of each communication cannot be ignored. The main response to this concern is in the batching of updates. Some providers allow multiple update statements to be sequentially chained together with semicolons and executed as one statement, and the CCE attempts to do this.
Given the high fixed cost of server executions and connection negotiation, especially over large networks such as the Internet, sending statements in batches can confer a very real performance advantage. The degree of advantage is highly network-specific and provider-specific—in fact, some providers do not accept multiple statements, or they require special syntax (for example, Oracle's BEGIN/END). This is another feature where control needs to be in the user's hands; therefore, the CCE can accept any integer value as a batch size. (The default is 15.) However, memory can quickly become a problem as the batch size grows—a single average update statement for one base table with several fields can easily take a kilobyte of memory to store before execution.
The process of performing these batch updates begins with an array of rows that need updating—the rows that the user has changed locally but has not yet instructed the CCE to submit. First, the linked list of base tables is traversed, to build a series of SQL statements for each table. Each base table ends up with a single SQL statement containing the concatenated updates for the first <batch size> rows on this table. Each table's batch statement is then executed against the back end. After all the statements for a single batch have been successfully sent, the local updates are performed on that same batch—that is, it is recorded in the client temp tables that this set of rows no longer has pending updates. This process is repeated for the next <batch size> rows, and so forth, until the original array is fully traversed.
Note Statements are sent in the order that the base tables appear in the internal linked list. This is interesting in cases where table relationships or server integrity constraints dictate that the ordering of updates might be significant. For example, when inserting a row into a two-table join, table A might have a foreign key constraint on table B, in which case the insert for table B needs to occur first. The internal linked list is built in reverse order from the order that the fields appear in the projection. That is, the base table belonging to the first result set column will be the last base table in the internal linked list (and thus the last table to get an update statement sent for a particular row). Therefore, in this example, including fields from table A before those from table B in the result set will ensure that the inserts are executed in the correct order.
Executing the update statements is only half the job. Each statement execution can fail in various ways, and to respond appropriately, the CCE must be able to handle a wide range of possible outcomes.
The first piece of information to analyze is the return code from the OLE DB ICommand::Execute call, which is an HRESULT that can be tested for success or failure. Failure codes are returned for a wide variety of reasons, from bad parameter values to back-end integrity constraint violations, and are often accompanied by explanatory text via the Automation error mechanisms. The CCE attempts to return this error intact to the user. A failed return code indicates that the update was not performed.
A successful return code is not a guarantee that the statement execution resulted in the intended update behavior. Most importantly, problems in row identification because of key field changes or optimistic concurrency violations are not considered errors in execution.
The root problem is that while the CCE knows that each statement is meant to modify exactly one row—no more and no fewer—there is no accepted way to communicate this fact to a general-purpose SQL engine. Therefore, the second piece of information needed after a successful execution is the pcRowsAffected out-parameter for ICommand::Execute, in which the provider is supposed to indicate how many records were affected by the just-executed statement. A value of 1 is expected and is the best indication that the update was performed as intended. A value of 0 indicates that the row in the update statement no longer exists in the form in which it was described and therefore no update was performed. Depending on how much conflict-detection data was sent in the WHERE clause, this means either that the row was deleted or that certain of its values were already changed on the server. In either case, this should be considered an optimistic concurrency conflict and the user should be given control of reconciling the problem.
A value greater than 1, indicating that multiple rows were affected, means that the row-identity portion of the WHERE clause failed at its job of uniquely describing the row to be updated. Of course, it is not illegal in principle to submit a WHERE clause that identifies more than one row. However, the CCE generates each statement in response to user changes in a single result set row, so in this context, multiple-row changes on the back end are to be considered unintended behavior, caused by insufficient key field information. This error is reported to the user, but the CCE is unable to automatically undo the multiple-row update because the server considers it a legal, successful operation and commits it.
The only other legal return value in pcRowsAffected is –1, indicating that the provider cannot determine how many rows were affected. Dealing with this value is troublesome for the CCE because, as should now be clear, the number of rows affected is very important in determining the actual success or failure of the update. Furthermore, OLE DB does not have any provision for reporting the update status of a row as "unknown," so the CCE is even unable to report the uncertainty. Currently, success is assumed.
The issues that arise in interpreting the results of a batched update statement are the same as those for single update statements, except with the additional layer of complexity involved in returning multiple results from a single execution. The OLE DB mechanism devised for this situation is to request the IMultipleResults interface at ICommand::Execute time; successive calls to GetResults on this interface will then return HRESULTs and pcRowsAffected values for each update statement in the batch. The interpretation of these values proceeds in the same way as for single statements.
Additional problems that might occur when dealing with batch statements can be summarized as follows:
As the specification for array-based interfaces such as IRowsetUpdate::Update dictates, the sending and analyzing of row updates continues through all non-catastrophic errors, concurrently recording results in the status arrays. In the simple case, rows that had errors are left in a pending state and rows that succeeded are committed locally.
However, if a failure HRESULT from ICommand::Execute or IMultipleResults::GetResults is obtained, or an unexpected pcRowsAffected value (anything other than 1) is obtained while processing multi-table updates, there is a very good chance that the local data will be out of sync with the server data. For example, if the statement that produced the error was for the second of two base tables that were being updated, the following inconsistency results:
Currently, there is no choice but to leave the local status for all the rows in this batch unchanged, because no one row in it has been successfully updated across all of the base tables. In most cases, the best course of action at this point is to refresh the row values (Recordset.Resync at the ADO level or IRowsetRefresh::RefreshVisibleValues at the OLE DB level) and reapply the changes from there.