October 1996
![]()
Remove Fatty Deposits from Your Applications Using Our 32-Bit Liposuction Tools
Matt Pietrek Matt Pietrek is the author of Windows 95 System Programming Secrets (IDG Books, 1995). He works at NuMega Technologies Inc., and can be reached at 71774.362@compuserve.com. So you think you've got a lean and mean application. You know every line of code in your program, and are confident that there's no excess baggage taking up room and slowing you down. Alas, like too many prepared foods these days, your code may have hidden fat lurking in the ingredients list. While the code you write may not be directly responsible, your programming tools and techniques may be adding extra weight to your executables and making them load slower than they have to. Let's go over some ways that you can slim down your programs. While I'll focus on C and C++ programs, some of what I'll describe applies to other compiled languages, such as Delphi, as well. One of my earliest articles was "Liposuction Your Corpulent Executables and Remove Excess Fat," (MSJ, July 1993). That article outlined numerous ways that EXEs and DLLs could become bloated. The article also included a program, EXESIZE.EXE, that examined executable files and reported on their relative fitness. Back then, programming 16-bit Windows¨ was all the rage. Now that Windows NT¨ and Windows 95 are here, I've received numerous requests for a version of EXESIZE that works with Win32¨ Portable Executable (PE) files. Since the formats of 16-bit New Executable files (NE) and 32-bit PE files are quite different, I couldn't just do a minimal rewrite of EXESIZE. Rather, I felt it was time to step back and examine the issues that the original article raised. Some of the cellulite that 16-bit NE files often acquired aren't relevant in Win32. On the other hand, 16 and 32-bit executables are equally prone to certain types of fat. Also, Win32 adds new ways to pump up the size and load time of your EXE or DLL. For the purposes of this article, when I say "executable," I mean any Win32 PE file, whether it's an EXE file, a DLL, or whatever. First, let's review the original suggestions that I gave for 16-bit programs. When I did this before writing this article, I was happily reminded about how simple Win32 programming is, relative to the dark ages of 16-bit Windows. On the other hand, some age-old issues remain. So put your go-go boots back on, and let's travel back in time to the 1993 article for a spot check against today's Win32 programming world. Set Your Alignment Correctly In 16-bit NE files, every segment and every resource has to start at an offset in the file that's a power of two (for instance 16, 32, or 64 bytes). Large-model 16-bit programs often have boatloads of segments. It's also common to have scores or even hundreds of resources. A lot of excess fat is introduced because the default linker alignment is 512 bytes. By setting a linker switch ("/ALIGN:XXX" for the 16-bit Microsoft linker), you can choose a more reasonable value (typically 16 bytes) and shrink the file by a significant amount. In Win32 PE files, the equivalent of a segment is known as a section. Sections still need to be aligned (typically on 512-byte boundaries). The key difference is that even large PE files don't usually have more than 10 sections. In addition, all of the resources for a PE file are combined into a single section, so resource alignment isn't an issue. Don't Generate Worthless Code In 16-bit NE files, when you export a function, it's necessary for the compiler (or assembler) to generate special code at the beginning and end of the function. This code sets up the data segment (DS) selector with the appropriate selector for the code in the exported function. The problem here is that many programs use compiler switches that cause this extra code to be generated for every far function, not just the exported functions. Thankfully, no special prologue or epilogue code is needed for exported functions in Win32. It's 10 O'Clock. Do You Know Where Your Debug Info Is? This one is a classic. Programs that ship with the debug information in the executable file are always a sign of a sloppy programmer or programming team. I'll have more to say on this later. Real Mode is Dead, So Why Are You Still Supporting It? In the very early days of Microsoft¨ Windows, it was possible for a program or DLL's segments to move around in memory. This isn't a problem in protected mode because the Intel CPU can hide this from you via its logical-to-physical address translation capabilities. In real mode, the CPU can't do this. To prevent problems when running in real mode, programs would often include small stubs of code that would hide the fact that a segment had moved in memory. The problem with these stubs is that they are only required in real mode. Starting with Windows 3.0, many programs specified that they needed to run in protected mode, yet they still included unused real-mode stubs. In PE files, this whole issue thankfully goes away. Pack It In (Multiple Segments)! Earlier I mentioned that NE files often have numerous segments. For several reasons (which I won't go into here), it is very beneficial to let the linker combine as many segments as possible into a single segment. In PE files, there aren't segments, but their replacement (sections) can be combined by some linkers. Combining sections has benefits, although the benefits are different than you'd get from combining 16-bit segments. More on this later. Put Your Relocations on the Chain Gang The 16-bit NE specification allows for multiple relocations to be represented by a single relocation record in the executable, rather than having separate relocations for each fixup. This technique is known as chaining. Some linkers took advantage of this, but Borland's TLINK didn't when the original article was written. Since then, TLINK has been updated to do relocation chaining. Relocations for 32-bit PE files are completely different than for NE files. While you can't chain PE-style relocations, you can go a step further in the quest to cut down executable file size. More on this later as well. Use the RTL Wisely If you're working with compiled languages like C++, you typically link with an external library of routines. These routines are commonly known as the runtime library (or RTL). If you choose to statically link these routines (as opposed to using the DLL version), you pay a price in executable size. Typically, for each RTL routine you use in your code, you'll bring in between a few bytes and several KB of additional code and data from the RTL. A simple function like strcpy is quite small, while something complicated like printf can be quite large. In the original liposuction article, I urged people to use the built-in Windows versions of common RTL functions rather than link with the static versions of the RTL functions. This same advice holds true in Win32. In fact, the Win32 API includes an expanded set of C/C++ type functions that aren't in Windows 3.1-there are even more possibilities to cut code from your executables and let code already in the system DLLs do the work. As an example, if you use sprintf in your code, try using wsprintf instead. It can prevent several KB worth of RTL code from being added to your program. Likewise, functions like strcpy can be replaced with lstrcpy. Using malloc and free in your code can add several KB of additional code and data. Consider replacing those functions with the HeapXXX equivalents (HeapAlloc, HeapFree, and so on). (For more on this subject, see my "Under the Hood" column in this issue.) Use the BSS Segment to Your Advantage In 16-bit compilers, uninitialized data (that is, variables declared without an initial value) are put into a segment known as the BSS segment. (A tip of the hat to those of you who actually know what BSS stands for.) Since the data in the BSS segment doesn't have to contain any particular initial value, 16-bit linkers usually just concatenate the BSS segment's data into the primary data segment, while not using any actual disk space. 16-bit linkers do this by making the size on disk field in the segment record smaller than the size in memory field. In Win32, the same notion of an uninitialized data still applies, albeit to sections rather than segments. I'll have more to say on this later. By the way, if you're still wondering, BSS stands for block storage space. Shrink Your Resident Names Table (Export by Ordinal) In programming 16-bit Windows, when you imported or exported functions from DLLs, the linker usually resolved references to the functions by ordinal. "By ordinal" is just a fancy way of saying "integer number." That is, exported functions are identified by a WORD value. The alternative to exporting by ordinal is to export by name. Using a name means that the actual name of the function appears in both the calling executable and callee. Obviously, working with ordinals is more efficient than working with function names. Function names are of variable length, so they use more space and are more work to compare than a simple WORD ordinal value. To import by name (rare in 16-bit Windows), the target DLL had to export the function by name. The exported name could be in one of two tables: the resident names table or the nonresident names table. The disadvantage of the resident names table is that it took up space in memory, while the nonresident names table didn't. Unfortunately, most 16-bit linkers defaulted to putting exported names into the resident names table in some situations. In Win32-based programs, the concept of resident and nonresident names tables goes away. There's just one table with the names of exported functions. But the problem of exported names taking up excessive space hasn't disappeared. Instead, the names of imported and exported functions take up space in memory unless you make the effort to export your functions by ordinal. While it's OK to import and export by ordinal with your own executables, it's not a good idea to import system DLL functions by ordinal, because the ordinal values aren't necessarily the same across platforms. So much for my 16-bit, 32-bit comparison. In the flashback, I highlighted certain areas where a 32-bit version of my EXESIZE program could be of use. But why simply tread water when there are opportunities to improve? One area to improve is runtime performance. With this in mind, I've divided my updated 32-bit liposuction tips into two broad categories: space wasters and performance killers. Later on I'll present a 32-bit utility (actually two programs from one set of sources) that lets you see how lean and mean your program really is. But before we get to dessert, let's eat our vegetables first. That is, let's examine some space and performance issues so you can better interpret the results of the liposuctioning programs. The first set of tips are things that are guaranteed to save space in your program, and are almost always worth doing. There are always exceptions to a given rule, but I think you'd be hard pressed to find an exception to these tips. One of my favorite features in Visual C++¨ is incremental linking. By minimizing the amount of work that the linker does, link times with Visual C++ can go from minutes to seconds. Incremental linking is so cool that it's enabled by default if you're linking with debug information. Incremental linking does its magic by rewriting only the parts of an executable that have changed since the last link. To make this possible, Microsoft Link inserts copious amounts of INT 3 instructions as padding between the various portions of the executable file. That way, if you add just a few lines of code and rebuild, the extra code can be placed into the area previously occupied by INT 3s. The rest of the file remains undisturbed. As you'd expect, incremental linking comes at a price. The cost is executable file size. An incrementally linked file can devote (on average) a full third of the space in the code section to INT 3 padding. On large executables, this easily puts you into the hundreds of KBs or even megabytes of INT 3s. What's the solution? Make sure that you turn off incremental linking when you do your distribution builds. The problem is, I've seen too many programmers who don't distinguish between builds. They ship the same executables that they do their testing with (that is, their debug builds). My 32-bit liposuction programs ferrets out these executables and tattles on them. If you see a substantial number of INT 3s in an executable, the odds are high that the file was incrementally linked. If all the overhead of the INT 3s weren't enough, there's even more wasted space in incrementally linked executables. In these executables, there's also an extra JMP instruction emitted for each function residing in the executable. When you call a function in an incrementally linked executable, the CALL instruction goes to the corresponding JMP instruction, which in turn sends control on to the desired function. These JMPs allow the linker to move functions around in memory without updating all the CALL instructions that reference the function. To sum up, incremental linking is great while developing. Just make sure to not ship your incrementally linked file. Normally, incremental linking is disabled for you automatically when you switch from a debug build to a retail build of your project. If you write your own custom MAKE files, the linker switch that controls incremental linking is /INCREMENTAL:XX, where XX is either YES or NO. The amount of space wasted by leaving debug information in your program depends on which compiler you use, as well as what type of debug information you're creating. Let's start with non-Microsoft compilers first, because they're the easiest to describe. In non-Microsoft compilers, the debug information is usually part of the executable file itself. For a good-sized project, the debugging information can be 50 percent or more of the file size. The story with debug information and Microsoft compilers is more complicated. Usually, programmers who are creating debug builds are also using incremental linking. If incremental linking is used, Microsoft's linker puts the debug information in a separate file with a PDB extension (PDB stands for program database). The linker puts the debug information in a separate PDB file so that incrementally linking the file requires very few changes to the executable file itself. The PDB file is just bits and pieces of CodeView-style information, albeit scattered throughout the file. You remember CodeView, don't you? Executable files that use PDB information have a small region that contains the name of the associated PDB file. When using incremental linking and PDB files, the space wasted in the executable file from debug info is small. The space used is just a little bit more than the size it takes to store the complete path to the PDB file. Technically, this section in the executable will be listed as CodeView information, but it's really just a pointer to CodeView information elsewhere (PDB file). Another common type of Microsoft debug information is real, honest-to-goodness CodeView symbols in the executable file. You can force the linker to produce CodeView information by using the /PDB:NONE linker switch, but doing this disables incremental linking. Computing and writing a complete CodeView symbol on each link would negate much of the benefit of incremental linking. If you're using CodeView debug information, the space consumed in the EXE falls into the same 50 percent category that I mentioned earlier for non-Microsoft compilers. You can also generate COFF-style symbol tables with Microsoft's linker. COFF symbols are a holdover from the early days of Windows NT, when the Windows NT team was writing its own programming tools. The linker switch to enable a COFF symbol table is either /DEBUGTYPE:COFF or /DEBUGTYPE:BOTH. There are relatively few tools that use COFF symbols, most of them being from the Win32 SDK. Like CodeView symbols, COFF debug information can occupy a significant portion of the executable file, so it should be removed (via a linker switch) before you ship the program. Another type of debug information that you'll see in Microsoft compiler-produced executables is Frame Pointer Omission (FPO) information. FPO is used in conjunction with CodeView or PDB symbols; it assists the debugger in finding parameters and local variables for functions where the compiler hasn't generated a standard stack frame using the EBP register. FPO information can be quite large, so it should be removed (via a linker switch) before shipping. Lastly, in Microsoft compiler-created executables you may see the so-called miscellaneous debug information. This region seems to always be 0x110 bytes in length and contains the name of the executable file that the linker created. If you rename the executable file, debuggers can use miscellaneous debug information to determine the original name of the file, and from that calculate the name of the associated PDB file. You get rid of miscellaneous debug info by doing a nondebug link of the executable file before you ship. Beyond the space wasted from the debug information itself, there are two other reasons why you should be concerned if there's debug information in your shipping code. First, the existence of debug information probably means that the executable was built with the compiler's optimizer turned off. The optimizer can cut quite a bit out of the total code size, and I'll talk about this topic next. The other reason why debug information in the executable is a bad thing is that it leaves you open to reverse engineering. Remember, debug information is a representation of your program's code, data, and type information (such as class definitions). The presence of debug information makes it an order of magnitude easier for a moderately competent programmer to crack open the inner workings of your program like a walnut. Although compiler optimizers seem to get a bad rap for producing buggy code, in my opinion they're nowhere near as bad as some people make them out to be. In my experience, most of the problems come from highly aggressive optimizations aimed at code speed rather than code size. Truth be told, I can't recall an optimizer bug when I told the compiler to optimize for size. The benefit of an optimizer isn't that it generates particularly great code. A good assembler programmer can usually match or better what an optimizer can do. Rather, the optimizer saves you from the really inefficient code that the compiler would otherwise generate. While I'll be using Visual C++ in the example below, you can expect to see similar results from other compilers. Consider the following trivial C program: The default, nonoptimized Visual C++ 4.1 compile ("CL FOO.C") produces the instructions shown in Figure 1. In total, 0x48 bytes of code are generated for the two functions. Now, let's turn on the "for size" optimizations ("CL /O1 foo.c"): Wow! Turning on the size optimization brought the generated code down to 0x18 bytes. That's about 33 percent of the unoptimized code size. If you compare the two listings, you can see several ways that the optimizer eliminated unneeded code. First, neither of the two functions (foo or main) needed a stack frame (the PUSH EBP, MOV EBP, ESP, and LEAVE instructions). Second, none of the register variable registers (EBX, ESI, and EDI) were used, so the optimized version doesn't bother to PUSH and POP them. Third, in both functions of the unoptimized version, there are JMP instructions that simply JMP to the very next instruction. This does absolutely nothing, while taking up 5 bytes. It also interrupts the CPU's pipeline, another thing to avoid. Fourth, in the if statement from function main, the optimized version does a much more clever job of using the CMP and SBB instructions to set the function's return value in EAX. On the other hand, it's hard to imagine writing worse if statement code than the unoptimized version. At this point, FCC regulations require me to tell you that you shouldn't expect such dramatic effects from an optimizer all the time. The small code sample above is admittedly contrived. Also, note that the optimization I turned on was for size, not for speed. The important point here is that the optimizer saves you from really stupid code that would otherwise be generated. If you compare the differences between size and speed optimizations, you'll find that optimizing for speed is almost the same as optimizing for size. The primary difference is that, when optimizing for speed, the compiler will turn on inline intrinsics, which are functions like strcpy that the compiler can generate code for smack in the middle of your code (rather than making a call to an external function). When they make your code faster, intrinsic functions can make your code larger as well. In a worst-case scenario, they could push the size of your code over a 4KB page boundary, incurring additional page faults. The overhead of a page fault is almost always much higher than any savings you'll get from intrinsic functions, so weigh your optimization decisions carefully. As a reference point, Microsoft's operating-system teams optimize for size rather than speed. Beyond the obviously better code that size optimizations provide, there's yet another very good reason for enabling the size optimization in Visual C++. When combining sections from various OBJs and LIB files, the linker aligns the code or data from each OBJ file at an offset that's a power of two. For COFF OBJ files (which is what Visual C++ produces), these alignment sizes correspond to the IMAGE_SCN_ALIGN_XBYTES #defines from WINNT.H. Possible alignment values are 1, 2, 4, 8, 16, 32, and 64 bytes. The default alignment for Visual C++ 4.1 (if not explicitly specified) is 16 bytes. That is, each section brought in from an OBJ file will start on a 16-byte boundary. Any space in the executable between the end of the previous OBJ and the new OBJ is filled with INT 3s. In a worst-case scenario, you could have 15 bytes of INT 3 padding between every piece of every OBJ file linked in. While it would be nice if Visual C++ let you pick an alignment value, there currently aren't any options that let you do so. For the present, you're stuck with 16-byte alignment between OBJs. As if all this padding between every OBJ weren't enough of a space killer, a seemingly innocuous Visual C++ compiler option can put you over the edge if you don't use it correctly. Consider what the Visual C++ documentation has to say about the /Gy compiler switch: "This option enables function-level linking by creating packaged functions in the form of COMDAT records." In English, this means that the linker will only bring in functions from an OBJ that are referenced, rather than the entire contents of the OBJ. The problem with /Gy (when used improperly) is that it causes the linker to align every function on a power-of-two boundary. I've seen executables that have thousands of functions and used /Gy. Since they used the default 16-bit alignment, they paid the price in over 8KB of INT 3s scattered throughout the code. But wait, there's more! While you might not think to turn on the /Gy switch by itself, it's implicitly turned on when you use /O1 (optimize for size) or /O2 (optimize for speed). Well, this sure sounds like a mess. Here I am, telling you that you should optimize for size on one hand, but on the other, I'm saying that optimizing for size enables the /Gy switch, which inserts INT 3 padding between every function. Think of size, then think of speed: what do you do? While you can't explicitly force the compiler to use a particular alignment, there is at least one switch that's probably more to your liking. The /Os switch ("choose size over speed") forces the compiler to emit its OBJ files with a 1-byte alignment rather than the default 16-byte alignment. And guess what? When you use /O1 (optimize for size), the /Os switch is enabled automatically. So while the /O1 switch turns on /Gy (which is ordinarily bad), the /Os switch sets the alignment to one, thereby removing the size hit that /Gy would normally cause. In contrast, when you use /O2 (optimize for speed), /Os isn't enabled, and you pay with INT 3 paddings. The moral: use /O1 rather than /O2, at least until Microsoft provides a better way to set the object file alignment. Another issue is the alignment of sections within the executable file. By default, Borland and Microsoft linkers start each new section in an executable on a 512-byte boundary. If you have several small sections (that is, less than 0x200 bytes), it theoretically could be worth your while to set the alignment to a smaller value, such as 16 bytes. Microsoft link has an /ALIGN switch that does just this. If you're a Borland C++ user, the /Af:nnnn switch sets the file alignment. Unfortunately for Microsoft users, if you use /ALIGN, it sets both the in-memory section alignment and the on-disk alignment to the same value (such as 16 bytes). In Windows NT, an executable with 16-byte alignment can run, but you wouldn't want to do this for some low-level techie reasons. Alas, Windows 95 won't run an executable file with sections that aren't aligned on a boundary that's a multiple of 0x1000 bytes. Borland's TLINK32, since it explicitly lets you set the file alignment separately from the section alignment, would seem to hold promise here. However, in Borland C++ 5x, setting the file alignment to any value less than 512 bytes causes the generation of an invalid executable. The moral of the story: someday, using smaller alignment sizes might be a way to squeeze space from a PE executable. Until linkers give you the requisite flexibility and work correctly, this avenue is a dead end. Typically, when you have uninitialized data, the compiler emits information about it into an OBJ section named .bss. In the executable file, the .bss section doesn't take up any space. If there's a .bss section in the executable, the operating system has to commit physical memory the moment it's accessed. Even if you've only got a single 4-byte uninitialized DWORD, the operating system maps in 4KB of physical memory since physical memory is allocated as 4KB pages A much better way than having a separate .bss section is to merge it in at the end of an initialized data section. This way, if you don't have much uninitialized data, it will fall within a 4KB page of memory that's already being used by initialized data. Luckily, most current linkers (including Visual C++ 4.x and Borland C++ 5.x) combine the uninitialized data into the initialized data section automatically. If you see a .bss section in an executable file, it was probably linked with an older linker. If it's your own executable, you have yet another reason to upgrade. All of the tips I've given you so far are pretty much no-brainers with nothing inherently questionable about them. There's a few other ways to cut space from your executables that require a bit more thought. In other words, the things I'll suggest next are things that you may or may not want to do. You have to decide if they're appropriate for your particular program. Win32 PE executables are loaded by mapping various pieces (for instance, the code and data sections) into memory at specific linear addresses. For each executable module (EXE or DLL) that's loaded, the Win32 loader has to pick a base address for the module. All of the sections in the module are then loaded at offsets relative to the base load address. Incidentally, this base load address is exactly the same thing as the module handle (HMODULE) of the executable file. When a linker creates a PE file, it gives it a preferred load address. In other words, the linker optimizes the file so that if the Win32 loader can load the file at the preferred load address, very little work needs to be done. On the other hand, if the Win32 loader can't load the module at its preferred load address, the loader has more work on its hands. The loader has to effectively relink the module so that all the internal references to code and data items are correct for the new (different) load address. The information that the Win32 loader uses to relocate a module in memory is known as base relocations. This data resides in a section of your executable file that usually has the name .reloc. In a nutshell, base relocations are a series of offsets within the in-memory module where the loader has to add the difference between the preferred load address and the actual load address. As you can no doubt imagine, the more base relocations there are, the more work the Win32 loader has to do if it has to relocate the module in memory. I'll talk more about this particular issue later on. In an ideal world, a module loads at its preferred load address, and the Win32 loader doesn't have to look at the base relocations in the .reloc section. As it turns out, if you want to take the chance that a module will always load at its preferred load address, you can remove the relocation information. I can't stress strongly enough that you're taking a chance here. If you remove relocations and the loader can't load your module at its preferred load address, the loader refuses to load the module. Game over. On the other hand, large programs can have hundreds of KBs of relocation information, so it's a tempting target. How do you decide if you want to remove relocations? Here's some general guidelines. Remember to use your own best judgment and think the situation through. Since there's only one EXE file per process, you can usually omit relocations from EXE files. By convention, EXE files load at linear address 0x400000 (4MB) in the process address space and get the first choice for a load address (ahead of DLLs). Since there's very little chance that an EXE can't load at its preferred address, it's usually safe to omit or remove its relocations. In contrast to EXEs, each process usually has multiple DLLs vying for space within the process address space. Hopefully, they'll all load at different addresses, and their relocations won't be needed. Still, leaving the relocations in a DLL is a cheap insurance policy that lets the DLL be loaded elsewhere if necessary. This is especially important in cases where you don't have control over all of the DLLs a process uses. While it might be tempting to try and generalize the above and say "Relocations should be omitted from EXEs, but left in DLLs," there are counterexamples. For instance, let's say Program1 wants to read the resources from another EXE file (Program2). If Program2's relocations are missing, there's a good chance that Program1 won't be able to map Program2 into memory to access its resources. A real-world example could be your program, which has an icon for its main window. To show your program's icon, EXPLORER or PROGMAN needs to be able to load your file to access the icon resources. Where might it make sense to remove relocations from DLLs? Perhaps you have a kiosk-type application that needs to run with very limited disk and memory. You have complete control over the application and the operating system that the program will run on. It's reasonably safe to assume that nothing will cause your DLLs to load someplace other than where you specify. You can determine the exact program-loading characteristics and know that they won't change as long as the executable files and operating system don't change. If you do decide to remove relocations, there are three ways to do it. The easiest is to specify the /FIXED switch on the linker command line. Alternatively, you can run the REBASE program with the -f option on your executable. REBASE comes with the Win32 SDK. The third way to remove relocations is the new RemoveRelocations function in the Windows NT 4.0 IMAGEHLP.DLL. My sample code below shows how to use RemoveRelocations. In an executable file, the raw data making up the program's code, data, resources, import information, export information, and so on is kept in distinct sections. Usually, there's one code section (.text for Microsoft compilers, CODE for Borland C++), one writable data section, one resource (.rsrc) section, one import section (.idata), and one export section (.edata). This is by no means a complete list of common sections. In addition to the "standard" sections, you can create additional sections by using compiler pragmas or assembler SEGMENT directives. For instance, you might have some data that you want to be shared between all processes that use your DLL. To implement this, you'd create a new section and tell the linker to give that section the SHARED attribute when it links the file. In some ways, sections are the Win32 equivalent of segments. In my 16-bit liposuction article, I described More importantly, each executable file section that's accessed in memory uses at least 4KB of physical RAM. Thus, even if you use only 2 bytes of data in a section, you'll still pay 4KB of physical memory for it. If you have three sections, each of which really only uses 10 bytes of memory, it'll cost you 12KB of physical RAM. If at all possible, you should combine sections that have the same or compatible attributes. I'm being intentionally vague here because I haven't found a hard and fast rule that I can give you. If you don't explicitly create your own sections, and if you're using tools that are current as of the writing of this article, you can pretty much ignore these issues. The current tools are pretty good about combining the sections that can logically be combined. For example, Visual C++ 4.1 combines the .CRT, .bss, and .data sections from various OBJ files into a single section (.data) in the executable. If you really want to tune your executables, there are still some sections that the linker doesn't combine automatically, but you can force it to combine them. For instance, if you examine executable files from Windows NT 4.0 and later, you'll see that in most cases the .idata and .edata sections have been merged into the .rdata (read-only data) section. So how do you merge sections? Microsoft Link offers a little known switch called /MERGE. The exact syntax is: The linker will add the contents of the source section into the destination section so that they appear as a single section on disk. Some sections you should leave alone, even though they may look like good candidates for combining. One is the .rsrc section-the Win32 UpdateResource function assumes that the resources are always in their own distinct section. Another section to avoid combining is the .tls section, which is where thread local variables go. Thread local variables are variables that you'd declare using __declspec(thread). Finally, perhaps you've partitioned your code so there's a section that's only needed at startup. You wouldn't want to merge that with other sections, as that section's code would most likely remain paged into memory when nearby code and data from other logical sections are accessed. If you're using Visual C++, you may be able to remove all of the runtime library code from your executable. Every Win32 platform to date has shipped with at least one copy of a Microsoft runtime library (RTL) for C and C++. In an ideal world, you could just rely on some basic C/C++ RTL DLL as being part of the basic operating system. For example, CRTDLL.DLL has come with every Win32 platform since Windows NT 3.1. Alas, Microsoft no longer supplies an import library to link with CRTDLL.DLL. Since CRTDLL.DLL isn't really an option, it would be nice if a standard Visual C++ RTL DLL could be counted on to always be there. Unfortunately, Windows 95 ships MSVCRT20.DLL, while Windows NT 3.51 didn't. In Windows NT 4.0, there's MSVCRT40.DLL and MSVCRT.DLL, but no MSVCRT20.DLL. To sum this up, at the current time, I can't see a clean way to produce a program that uses the system-provided C/C++ RTL DLL and that can rely on that DLL being present on all current Win32 platforms. It looks like MSVCRT.DLL may be a step towards that direction, but at the moment, no import library is provided for it. Having said that, if you have a program that's targeted for a specific release of a Win32 platform, you can use the appropriate MSVCRTxx.DLL that comes with the system. And of course, if you don't mind the extra work of shipping a runtime library DLL (just in case!), then you certainly should consider using the runtime library DLLs rather than the statically linked RTL. This is especially worthwhile if your product consists of many executables. Up to this point in the article, I've been focusing on ways to cut down the size of your executable files. Let's now look at some common ways to speed up your program's load times. As with the size squeezing I've already described, my updated liposuction programs can identify certain things you can do to improve load performance. Earlier, when I described removing relocations, I mentioned that the Win32 loader might not be able to load an executable module at its preferred load address. In this case, the loader has to move the module elsewhere in memory. The relocations in the executable file are what allows the loader to modify the in-memory module to operate at an address different than its preferred load address. As you can imagine, using the relocations to move a module in memory takes time. The more relocations there are, the more time it takes. So why might the loader be unable to load a module at its preferred load address? The number-one reason is that there's already something else occupying some or all of the memory range where the loading module wants to load. What does "something else" mean? It could be that the module is attempting to load in a region being used by a thread's stack. Or perhaps the desired load address conflicts with a program's heap region. Most likely, modules try to load at addresses that fall within the range of memory being used by other modules. Regardless of the cause of the conflict, the loader has to find a different, unused region of linear memory and do all the relocations to move the module there. The classic example of a load conflict occurs with DLLs. The default preferred load address that most linkers use is 0x10000000 (or 256MB). If your project consist of an EXE and five DLLs, and you don't do anything about the preferred load addresses, you'll end up with one DLL that loads at its preferred address, and four DLLs that the loader needs to find somewhere else to load. Quite obviously, something should be done to avoid this scenario. So what can you do to avoid load address conflicts? For starters, linkers let you specify a preferred load address. For Microsoft Link, the command line option is /BASE:xxxx, where xxxx is an address in hexadecimal form. For Borland's TLINK32, the equivalent switch is -B:xxxx. Knowing that you can specify a preferred load address at link time, you could just try picking addresses that are far enough apart so that no two DLLs overlap. But that's messy and error-prone. For example, if you pick base addresses that are close together, you're susceptible to a collision if you later modify the code of a module so that its memory range expands into another module loaded nearby. A much easier way to set preferred load addresses is with the REBASE program from the Win32 SDK. The primary purpose of REBASE is to change the preferred load address of an existing executable. The real power of REBASE is its ability to work with groups of files. REBASE can take a list of the EXE and DLLs that a process will load and calculate a load address for each executable that won't cause a collision with any of the other executables in the list. After doing the calculations, REBASE can then go through and modify the preferred load address of each executable. REBASE is typically used as part of the build system for a project. After everything has been linked, a file that has all of the names of the executables is passed to REBASE, and REBASE updates each executable accordingly. For example, let's say your project consists of A.EXE, B.DLL, C.DLL, and D.DLL. Simply create a file like this one, BASE_IT.TXT: Then pass the file to REBASE, along with the starting preferred address. For instance, specifies that the images listed in BASE_IT.TXT should be grouped together starting at linear address 0x600000, and that the filenames are relative to the C:\MYDIR directory. REBASE has a slew of other options that I won't try to describe here-see the SDK documentation for more information. While REBASE isn't the most user-friendly tool around, it's definitely worth your while to learn how to use it if you're doing any sort of nontrivial commercial software. While avoiding address space collisions is definitely a worthwhile goal, there's still more that you can do to offload work from the Win32 loader, thereby improving executable load times. Besides just mapping pieces of a PE file into memory, the Win32 loader is also responsible for resolving references to imported functions. For example, let's say you call GetFocus from your program. When you load the executable, the Win32 loader has to locate GetFocus in memory and then patch your in-memory module with the address of GetFocus. The act of looking for the address of GetFocus is very similar to what GetProcAddress does. That is, given a module handle and the name of a function, it goes through the exports table of the specified module and looks up the address of the exported function. The fact that the Win32 loader and GetProcAddress do similar things is no accident; deep inside the operating system, the loader and GetProcAddress use the same internal routines. Knowing that the Win32 loader and GetProcAddress share much code, you can see that for every function you import, the operating system is doing roughly the same amount of work as if you had called GetProcAddress for every imported function. If you run a program like DUMPBIN or TDUMP on your executable and see that it imports 400 functions, think of Windows doing 400 calls to GetProcAddress every time your executable loads. Kind of sobering, isn't it? So how do you improve a situation like this? The addresses of imported functions probably aren't changing each time you run your executable. In fact, when calling system functions like GetFocus, the addresses of the imported functions won't change unless the user installs an upgrade or patch to the operating system. Since the addresses of imported functions won't change much (except maybe during the development phase), wouldn't it be great if there was a way to get the imported function's address once, and just save it in your executable? As it turns out, there is. The process is called binding. When the Win32 loader encounters an executable that's properly bound, it can avoid all those time-consuming function lookups. As a point of reference, all of the executables that come with Windows NT are bound. Binding can be done in one of two ways. First, you can run the BIND program from the Win32 SDK. For instance, causes BIND to look through the list of imported functions in FOOBAR, calculate the addresses of those functions, and write those addresses back into FOOBAR.EXE. The -u switch tells BIND to go ahead and write the addresses to the executable. Without -u, BIND goes through the motions of looking up the imported function addresses, but leaves the executable alone. The other way to bind an executable is through the BindImage and BindImageEx functions from IMAGEHLP.DLL. The SDK BIND utility is primarily just a wrapper around the BindImageEx function. My sample liposuction programs show how to use BindImage yourself. One place where you might consider making use of BindImage or BindImageEx is in your installation procedure. There are a couple of common questions about binding. First, if you bind your image and then later one of the imported DLLs changes, what happens? Nothing bad. When IMAGEHLP binds an executable, it also writes a timestamp into your executable that corresponds to the timestamp of the imported DLL. As the Win32 loader processes the imported functions in an executable, it checks the timestamp in your file with the timestamp of the DLL that you'll be importing functions from. If the timestamps match, the loader's work is done. If the timestamps differ, you're no worse off than before. The loader will operate just as if the executable wasn't bound in the first place. In other words, there's no performance hit if you bind to one set of DLLs, and then one or more of the imported DLLs change. The other issue with binding is what happens when you don't know precisely which Win32 platform and version your executable will run on (Windows 95? Windows NT 3.51? 4.0? Which service pack?) Let's say your code calls GetFocus in USER32.DLL, and you bind your executable. The only users who will see the speed increase of your binding efforts are those who have the exact same version of USER32.DLL as you have. Is binding therefore worth the effort? Even if you don't realize any benefit from binding your image to the system API functions, you'll still get the benefit of bindings between your EXE file and its DLLs. Likewise, if you have several DLLs that call each other, it's worth binding those DLLs just to make the importing of your own functions faster. Of course, the success of binding assumes that you've properly REBASEd your executables first. Binding your executable to a DLL that the loader will be moving elsewhere doesn't buy you anything. Ideally, your installation program will bind your executables and DLL as part of its setup procedure. Enough of the theoretical! The best part of creating this article for me was writing the sample programs. With one exception, my liposuction programs provide information on each of the tips that I mentioned above. In reality, there's just one core program, but it can be built as either a command-line program (LIPO32.EXE) or a GUI program (Liposuction32.EXE). The GUI version shown in Figure 2 is useful for interactive analysis of executable files. You can either type a program name into the edit control at the top, or drag and drop executable files anywhere onto its window. Once it's given a filename to work with, Liposuction32.EXE fills in the various fields of the dialog box with information about the program. The three buttons at the bottom offer functionality not available in the command-line LIPO32 program. When enabled, these buttons let you remove debug information from a file, strip out relocation information, and bind it. Afterwards, the program is reanalyzed to show you the new, improved version. Figure 2 Liposuction32 The command-line version shown in Figure 3, LIPO32.EXE, is not as snazzy as Liposuction32.EXE but excels in other areas. Since it's a command-line tool, you can incorporate it into your build process. Likewise, you can redirect all of its output to a file. This is particularly handy if you want to analyze numerous files. For instance, I used the command-line version to analyze every file in the \WINNT\SYSTEM32 directory. If you're inclined to do stuff like this, the shell FOR command is your friend. As an example, the command line creates a Lipo32 report for each EXE and DLL in the current directory, and puts the output into a file called LIPO_OUTPUT. Figure 3 LIPO32 Let's walk through the GUI version to see what these two programs tell you. I've chosen the GUI version since you'll always see something indicating what the program is supposed to be showing. The command-line version doesn't emit any output for a particular issue if it doesn't see anything wrong. Referring back to Figure 2, the top edit control contains the name of the program just analyzed. You can type in the name of a program and press the Enter key to change the file under Liposuction32's microscope. On the left side, under the filename, are two fields that indicate how big the relocation table is and whether the image has been bound or not. The list box titled Incremental Linking tells you how many INT 3s were found in each of the executable's code sections. As mentioned, INT 3s are inserted by the linker when it incrementally links a file. How do I tell how many INT 3s are in a file? I used a brute force approach that seems to work well in all my tests. In each code section, I repeatedly scan for three consecutive bytes with the value 0xCC. A single 0xCC byte is the opcode for an INT 3 instruction. I choose three consecutive 0xCC bytes as the trigger condition because the chance of some other instruction having three consecutive 0xCCs is extremely small. Once I find three INT 3s in a row, I continue scanning for additional INT 3s until there's no more code or I come across a different byte value. It's important to realize that the presence of several hundred INT 3s in your program doesn't necessarily mean that incremental linking was used. Earlier, I mentioned how the linker aligns OBJ files and functions on 16-byte boundaries by default, padding them with INT 3s. These alignment INT 3s will often show up in the totals. I didn't make any attempt to try to separate out alignment INT 3s from those created by incremental linking. After all, an INT 3 is an INT 3, and it takes up space needlessly. If you wish to separate the two types of INT 3s, you can modify my code to look for runs of INT 3s that are never longer than 15 bytes (the maximum padding that a 16-byte OBJ file alignment will insert). Interpreting what the number of INT 3s reported means can be tricky. If you have less than 1KB or so, you're probably seeing the Microsoft linker's 16-byte padding. If there are vast numbers of INT 3s (for instance, something like 25 percent of the total code size), you're probably seeing incremental linking. If you see somewhere between 1 and 10KB, it could be incremental linking or it could be that the linker is aligning every function on a 16-byte boundary. I mentioned this earlier when I described using the Visual C++ /Gy switch without the use of the /O1 switch. The numbers I'm using here are rough values. They'll need to be adjusted if your program is abnormally small or extremely large. The list box labeled Debug Info contains the size and type of any debugging information found in the executable. Debug information from Borland programs is labeled BORLAND. From Microsoft compilers, you'll see some combination of CODEVIEW, COFF, FPO, and MISC debug information. The debug information from other compilers will probably show up as CODEVIEW information. Miscellaneous debug information takes up only 0x110 bytes, and can be safely ignored if it's by itself. However, if you see Borland, CodeView, or COFF information in the file, there's reason to be concerned. The file may contain symbol information that you wouldn't want other people to see. FPO debug information is only of use with other debug information, although it can take up a good chunk of space. The key point is that if you're seeing any of these types of debug information, the program was probably built as a debug build and therefore didn't have the optimizer enabled. Treat the presence of debug information as an indicator of deeper problems. Of course, you can always find exceptions. For example, most of the Windows NT system DLLs contain FPO information to aid in debugging, but they were compiled with optimizations enabled. The list box entitled Unoptimized Code shows just one aspect of the space wasted by not using the optimizer. The idea is that if you find evidence of one type of unoptimized code, you can expect that the optimizer wasn't enabled. The unoptimized code that the liposuction programs looks for is JMP instructions that jump to the very next statement. These JMPs waste five bytes, and do nothing. The liposuction programs total up how many of the sequences they see and report the results. Remember, these JMPs are just one type of unoptimized code. There are many other code sequences that also waste code, and my code doesn't attempt to find them. If you do see a large number of "stupid JMPs," you're most likely looking at a debug build (where optimizations are generally disabled). If so, you're also probably seeing debug information in the report as well. If you're using Visual C++, you'll also probably have a large number of INT 3s reported. The antidote: rebuild in release mode! The Uninitialized Data list box contains a list of all the executable's sections that contain uninitialized data. Ideally, this list box should be empty because linkers can combine these sections with other initialized data sections to reduce the section count. If you see entries in this list box, you're probably dealing with an older linker-time to upgrade. The Combinable Sections list box lists sections in the executable file that might possibly be combinable. In theory, these sections can be combined together (for example, with the /MERGE: switch) to reduce the section count and to possibly save space on disk. At the end of each series of combinable sections, the code takes a stab at how many pages of memory are required for these sections, both before combining them and after. Remember, though, you don't want to follow the program's suggestions blindly. As I mentioned earlier, there may be good reasons to not combine some sections. The logic that populates the Combinable Sections list box is pretty simple, so I won't point out every single possibility. In a nutshell, the code looks for sections that have the same attribute. Before comparing section attributes, though, the algorithm removes any .reloc and .rsrc sections from consideration. A serious weakness is that the logic doesn't suggest sections that can be combined, even though they have different attributes. For instance, the .idata and .edata sections can theoretically be combined into the .rdata section, even though they may have different attributes. In my tests, the list box often suggests that the .idata section could be merged with the .data section. A better choice would be to put .idata into the .rdata section. The Load Conflicts list box reports the filename and memory ranges of any executable modules that have load-address conflicts. If Liposuction32 is only examining one executable at a time, how does it know there will be load conflicts? My code simply attempts to do what the loader would do. That is, it looks at the imports table and retrieves the name of every imported DLL. The code then goes out and attempts to locate the imported module. If the imported module is found, Liposuction32 retrieves its preferred load address. While these steps will work for all of the modules that are directly imported by an executable, what if an imported module in turn imports additional DLLs? Liposuction32 handles this using recursion. After every imported module has been located and stored away in a table, Liposuction32 sorts the table and looks for modules that would overlap in the linear address space if they were to be loaded at their preferred load address. If you see entries in this list box, you're a candidate for the REBASE program I described earlier. The bottom three buttons in Liposuction32 let you modify an existing executable. The Strip Debug Info button is only enabled if the executable file contains debug information. While I was writing this code on Windows NT 4.0 beta 2, I discovered that IMAGEHLP would leave a zero-length file if run on a Borland executable. This issue should be resolved in later builds of Windows NT. If the button is enabled and you choose to strip debug information, the button calls the IMAGEHLP SplitSymbols function. I've noticed that SplitSymbols still leaves miscellaneous debug information in the file. Since it's relatively small, you may choose to ignore it. If you really want to get rid of it, relink the executable without the linker debug flags set. The RemoveRelocations button is enabled when there are relocations present in an EXE file. For DLLs, I've intentionally disabled the button to prevent the inadvertent removal of relocations. If you truly want to remove the relocations from a DLL, you can run REBASE with the -f switch. Internally, the RemoveRelocations button uses the IMAGEHLP RemoveRelocations function. On Windows NT 4.0 beta 2, I discovered a problem with this function where the executable file wouldn't run afterwards. This should be fixed in subsequent builds. The Bind button is always enabled, even if the image indicates that it has been bound. Why did I do this? Let's say that the executable under examination had been bound. It's possible that one or more of the DLLs that the executable is bound to has changed. While I could have written a bunch of code to read through the bound imports table of the executable and verify the timestamps, I left this as an exercise for the enterprising reader. Before I finish, I'll go over just a few of the highlights of the code for Liposuction32 and Lipo32. I'll spare you from a blow-by-blow detailed account, as there's a large amount of code. (See page 5 for information about downloading full source code.) Still, there are some useful tidbits worth knowing, especially if you want to extend the program yourself. The core of both programs is LIPO32.CPP (see Figure 4). The AnalyzeFile function is where the work of analyzing an executable starts. It's called either from the GUI code (LIPOGUI.CPP) or from the command-line code (CMDLINEUI.CPP). The LIPO32.CPP file does no output itself. Rather, it examines the specified file and calls a set of output functions with the results. The output functions are prototyped in LIPO32OUTPUT.H. Both LIPOGUI.CPP and CMDLINEUI.CPP implement versions of the LIPO32OUTPUT.H functions. This is the key to sharing the core code between both the GUI and command-line versions. The presence of a makefile definition (HARDCORE=1) tells NMAKE that the command-line source file should be linked in rather than the GUI version. Returning to the AnalyzeFile function in LIPO32.CPP, the first thing it does is create a PE_EXE2 object using the passed-in filename. I'll describe the PE_EXE2 object shortly. After creating the PE_EXE2 object, AnalyzeFile uses the object to verify that the specified file is actually a PE file, and that it's an Intel 80386 class binary. If either condition isn't true, AnalyzeFile reports an error and returns. The remainder of the AnalyzeFile function is straightforward. Using the PE_EXE2 object, it calls the functions LookForIncrementalLinking, LookForUnoptimizedCode, LookForDebugInfo, LookForRelocations, LookForCombinableSections, LookForBSSSections, LookForLoadAddressConflicts, and LookForBoundImage. I'll skip the gory details of the functions here. If you're interested, refer to the LIPO32.CPP source, which I've commented extensively. The LIPO32.CPP core code depends heavily on the PE_EXE2 class. PE_EXE2 is a class that I created to encapsulate much of the details of Portable Executable files. PE_EXE2 is actually a third-generation derived class. Refer to Figure 5 for the class hierarchy. Figure 5 PE_EXE2 Class Hierarchy The MEMORY_MAPPED_FILE class provides basic functionality for taking a filename and making it available as a range of memory. The constructor and destructor take care of opening and closing files, memory maps, and all that jazz. If you don't already have a memory-mapped file class, this one may be worth considering. The EXE_FILE class sits atop the MEMORY_MAPPED_FILE class. Its functionality is limited to telling whether the memory mapped file represents an executable file or not. If the file is an executable, the EXE_FILE class can tell you what type it is (that is, MS-DOS¨, 16-bit Windows, OS/2 2.x, VxD, or PE). The PE_EXE class is where things get interesting. This class is a very lightweight wrapper around the Portable Executable file data structures defined in WINNT.H. Its functionality is mostly limited to reading fields out of the PE header. In addition, the PE_EXE class can also return information and pointers calculated using the PE file's data directory, such as the size of the imports table or a pointer to debug information. If your programs operate on PE files, you might consider adding the PE_EXE class to your toolbox. It's important to remember that the PE_EXE class is designed to work in conjunction with the information in WINNT.H, not replace it. For example, the GetCharacteristics method returns a DWORD full of flags that has information about the executable file. These flags correspond exactly to what's defined in WINNT.H. I didn't care to reproduce all of the #defines and structure definitions from WINNT.H. If you want to use the PE_EXE class, you should consider the PE file structures and definitions from WINNT.H as part of the class. Finally, I come to the PE_EXE2 class, which is derived from the PE_EXE class. PE_EXE2 offers two categories of functionality not in the PE_EXE class. First, PE_EXE2 provides access to the sections within an executable. You can look up a section by its name, its 1-based index within the file, or by a relative virtual address (aka an RVA). Each of the section-related methods returns a PE_SECTION object, defined in PESECTION.H. The PE_SECTION object is just a thin wrapper around the IMAGE_SECTION_HEADER structure defined in WINNT.H. The other extra feature that the PE_EXE2 class has and the PE_EXE class doesn't is that it allows easy access to the debug information within a file. Interpreting debug information is a bit difficult, as Borland and Microsoft files have traditionally differed in how they interpret a critical field in the PE format. I created the PE_EXE2 class so I could use the base PE_EXE class in other projects where I didn't need debugging or section-related information. Aside from the PE_EXE2 class, the other class that the liposuction code relies on is the MODULE_DEPENDENCY_LIST class. This class is critical to finding executables that overlap in the process address space. Given the name of an executable file, this class builds a complete list of modules that the executable imports from, both directly and indirectly through other modules. After the list is built, the class can be queried to look up a particular module by name. The class can also report how many modules are in the list, as well as enumerate through each module in the list. To make the code for the MODULE_DEPENDENCY_LIST class simpler, I used the PE_EXE class that I described earlier. In its constructor, the MODULE_DEPENDENCY_LIST class takes the name of an executable file and uses recursion to find each imported DLL. To replicate the behavior of the Win32 loader, the constructor temporarily changes the current working directory to the directory where the initial executable resides. After the module list has been built, the constructor restores the original current working directory. I mention this only because this makes the class unsafe for multithreading applications, and the current working directory applies to the whole process, not to a particular thread. I've covered two areas where inefficiencies can creep into executable files: size and performance. In the size department, if you do nothing else, make sure that you don't ship a debug build of your program. In the speed department, try to avoid load address collisions by using tools like REBASE. I've covered other areas where you can optimize, but if you do just those two things, you're well on your way to leaner, meaner code. These days, words like gigabytes and phrases like "200 MHz" are tossed around freely. It seems that tuning programs to be as efficient as possible is a lost art. As I've shown here, it's really not hard to be a friendly citizen of the programming community. If we all work together to keep our code lean and fast, we might be able to break the vicious cycle of needing bigger and faster computers just to get our work done Back to the Present
Turn Off Incremental Linking When You Ship!
Lose the Debug Information
Use the Optimizer
int foo( int i )
{
return i * 2;
}
int main()
{
if ( foo(7) )
return 1;
else
return 0;
} foo proc
401000: MOV EAX,DWORD PTR [ESP+04]
401004: ADD EAX,EAX
401006: RET
foo endp
main proc
401007: PUSH 07
401009: CALL 00401000
40100E: ADD ESP,04
401011: CMP EAX,01
401014: SBB EAX,EAX
401016: INC EAX
401017: RET
main endp Watch that Alignment!
BSS: Just Say No!
Removing Relocations
Combining Sections
how every segment used up system resources (for instance, LDT selectors), and that it was a good idea to keep your segment count as low as possible. The same idea holds true in Win32. Every section from a PE file uses memory from internal operating system tables. Each additional section also adds at least 512 bytes to the size of the executable file (by default). /MERGE:<source_section>=<destination_section> Use the System Runtime Library Code
Avoid Address Space Collisions
A.EXE
B.DLL
C.DLL
D.DLL REBASE -b 600000 -R C:\MYDIR -G BASE_IT.TXT Binding
BIND -u FOOBAR.EXE Liposuction32
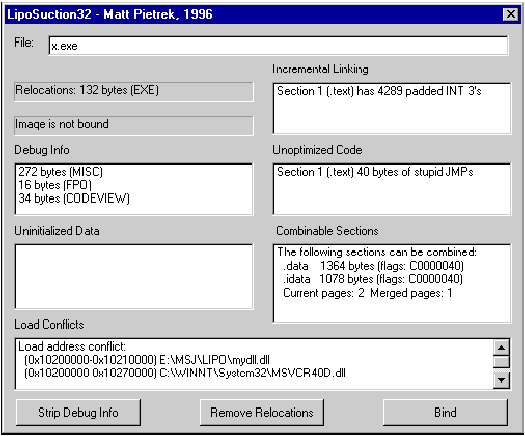
for %a in (*.exe *.dll) do lipo32.exe %a >> LIPO_OUTPUT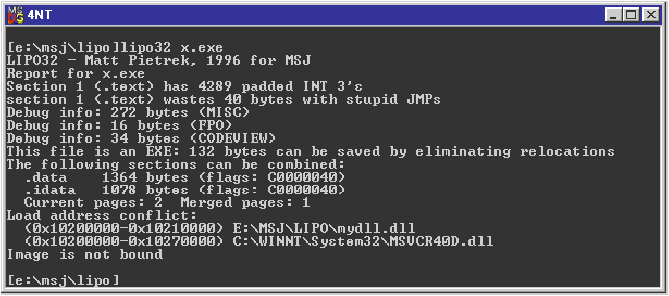
Interpreting the Results
The Liposuction32 and Lipo32 Code

Summary