August 1998
![]()
| Understanding Interface Definition Language: A Developer's Survival Guide |
| IDL is the preferred way to describe your interfaces. However, many developers only have a rudimentary knowledge of IDL. Knowing IDL will help you think about your interfaces in a more explicit manner, which is especially useful now that you spend so much time exposing interfaces. |
| This article assumes you're familiar with C++, COM, and marshaling. |
|
Bill Hludzinski is a software developer at Vivisoft Corporation (http://www.vivisoft.com) and can be reached at billh@vivisoft.com.
|
|
The age of IDL
(Interface Definition Language) is upon us. IDL is the preferred way to describe your interfaces. However, many developers only have a rudimentary knowledge of IDL. They rely on the Visual C++ wizards to generate their IDL files, but don't have any idea what the code does. On the other hand, who wants to browse the MIDL Programmer's Guide in their spare time, trying to learn a new language with over 140 keywords? To meet your IDL needs, I am going to provide a basic survival guide that will show you what IDL is, when you need it, and the basics of using it. You'll find that knowing IDL will help you think about
your interfaces in a more explicit manner, which is especially useful now that you spend so much of your time exposing interfaces.
Review
|
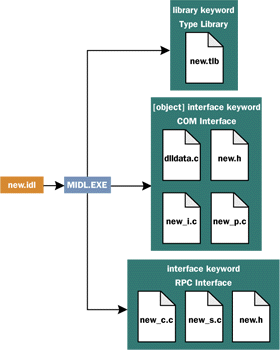 |
| Figure 1 MIDL-generated Files |
|
Just Like C++!
|
|
| the corresponding IDL file would look like this: |
|
| So IDL is rooted in the data type declaration portion
of C and C++. It supports all of the standard C++ data
types as well as the data definition keywords that you've grown to know and love. More importantly, IDL's data types and definitions are both language-neutral and
platform-neutral.
Some of the base data types supported by IDL are int, Boolean, byte, char, double, float, long, short, and void *. IDL also supports the signed and unsigned qualifiers, the const type modifier, and the wchar_t predefined type. As far as data definition keywords go, IDL supports enum, typedef, union, and struct. IDL even supports the comment tokens and the use of preprocessor directives like #define and include (which doesn't use the # prefix). When writing IDL for an API, developers will just take their header files, comment them out, include them with the IDL file, and start uncommenting the functions. IDL and C/C++ really are that close.
Code Generation
|
|
| would appear in the generated code like this: |
|
| Much of the time your IDL file will need to see data type definitions from other header files and even other IDL or ODL files to process base data types. In these cases, you will have to use the import directive, which actually includes the file in the MIDL processing. The include directive just makes files available to the source code from which the proxy/stub code is compiled. It's important to remember that any function declarations in imported files are ignored, and that in the resulting source code, the generated header file will not directly contain the imported types. Instead an #include directive is generated for the header corresponding to the imported interface. The following import statement |
|
| would be generated in the source code as: |
|
| Since I'm discussing the importing of files, it's probably a good time to mention the standard IDL include files. wtypes.idl, unknwn.idl, objidl.idl, and oaidl.idl ship with Visual C++ and Visual J++. You can find them in their respective include directories. These files document the standard C library of the COM era in one place. They include the data types, #defines, and interfaces that have been defined (and in many cases implemented) by Microsoft for supporting COM.
Of course, Visual C++ ships with even more IDL files for things like ActiveX controls and ActiveX documents, but these four files are the fundamental ones to include in your own interfaces. Figure 3 lists most of the IDL files that ship with Visual C++ 5.0 in order of dependency. The most dependent ones are at the bottom. One of the best ways that you can familiarize yourself with IDL is by browsing through these files.
Your First Attributes
|
|
| In this case, the attributes are all applied to the arguments of this function. However, attributes are not limited to arguments alone. They can be applied to other things such as functions or libraries. [in] and [out] are two of the fundamental attributes that IDL makes available.
Any data that is to be marshaled remotely must be placed into a data packet and transmitted across the network, so the actual transfer of function parameters can be an expensive operation. To save work, IDL supplies the [in] and [out] attributes for explicitly describing which way parameters need to be copied. A parameter specified as an [in] parameter will only be copied from the client to the server. Likewise, a parameter specified as an [out] parameter will only be copied from the server back to the client. A parameter specified as [in,out] will be copied in both directions. If inbound data is to be modified and returned to the caller, it is done by passing in a pointer to where the resulting data is to be placed. For this reason, [out] parameters must always be pointers. This brings me to the next item at hand, marshaling pointers and how they differ from your typical pass-by-value arguments. For example, an integer is marshaled by simply copying the value from the address space of the calling process to the address space of the destination process. But a pointer to a string would be marshaled by copying the data that the pointer points to, not the pointer. For out-of-process calls to be transparent, whatever exists in the client's address space at the time of the call must be recreated in the server's address space. Take a look at the following IDL example: |
|
| If a client called this function, passing the address of a variable whose value was 17, the value 17 would be sent across the network from the client's proxy to the server's stub. On the server, the stub code would copy the value 17 into the server's address space and call the server function with a pointer that pointed to that value (see Figure 4). |
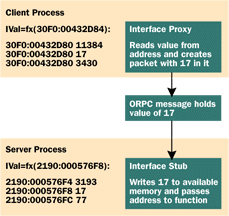 |
| Figure 4 Marshaling a Pointer |
|
|
|
| Pointers that can be null are called unique pointers and are indicated by the [unique] attribute. |
|
| There is another characteristic of pointers that marshaling must emulate as well: duplication. If you look at the following IDL example, you will notice that the function takes two pointers: |
|
| Now consider the following client code: |
|
| This code is noteworthy because it passes the same pointer twice in the same function invocation. This means that the value pointed to by both pointers will be passed across the network twice, once for each value. When the stub unmarshals the parameters on the server side, it will allocate two distinct memory blocks, one for each value, and set each pointer to point to its value's newly allocated memory. So on the server side, even though both pointers will point to memory with a value of 10, they will be pointing to different memory locations, unlike on the client side.
This side effect can result in erroneous execution if the behavior of the server code actually takes into account the equivalence of the two pointers. IDL can handle this through the use of full pointers. A full pointer comes closest to fully simulating C pointers because its interface marshaler performs duplicate pointer detection and will make sure that duplicate pointers are unmarshaled as duplicate pointers, pointing to one memory location instead of two. A full pointer may be used by declaring a pointer with the full attribute: |
|
| It's important to note that full pointers incur a reasonable performance penalty searching for duplicate pointers, so only use them in place of reference pointers or unique pointers when the semantics of the function take duplicate pointers into account.
Believe it or not, the issue with pointers and memory management gets even more complex. When you pass [in] values into a function via a pointer, things are still simple. The caller will always allocate the memory, point the pointer to the memory, and put the value in that memory before calling the function. However, with an [out] parameter, things aren't so straightforward because the caller isn't providing a value, so you might be tempted to pass in a null pointer and have the callee allocate the memory. This opens up a can of worms. How can the caller free the memory? This can be done by the COM task allocator which I'll talk about later. Suffice it to say that things are much easier when you depend on the caller to always allocate the memory for [out] parameters. For this reason, caller-allocated memory is the standard for [out] parameters in COM. This means that an [out] parameter should never be null, and hence should always be a reference pointer. Things get even more interesting when user-defined types begin to contain pointers. Look at the following IDL: |
|
| This example contains pointers within a user-defined
structure. These types of pointers are embedded pointers, whereas your typical pointer (which isn't embedded in a structure) is a top-level pointer. Let's say that the purpose of this function is to return a doubly linked list of elements to the caller.
First, let's assume that the caller acts appropriately and allocates memory for a single ELEMENT, then passes its address into the GetElementList function. Because there was only one element in the list, the caller left pNext and pPrev as null. This violates the rule about passing null pointers for [out] parameters because all allocation should be done by the caller. But if you think about it, how could the caller know up front how many elements to place in the list if that's what GetElementList is to return? Besides, you use null pointers to indicate the top and bottom of the list. This isn't what you want. With embedded pointers, you want them to be able to be null going in, and you want the function to be able to allocate the memory for the elements, setting up the list by assigning the pPrev and pNext pointers appropriately. To handle this situation, embedded pointers are treated differently. It makes more sense for the callee to allocate the memory since the caller can never know how much to allocate. Thus, you use the [unique] attribute to allow embedded pointers to be null going in, and assigned to memory on the function return. However, for top-level pointers the old logic still applies, and they must still be made reference pointers. If you look at the previous code, you will notice that the pPrev and pNext pointers both have the [unique] attribute, yet the pList parameter in the GetElementList function call would still default to a reference pointer as an [out] parameter in the function declaration. This makes all of the pointers legal, but leaves a more serious problem. Embedded pointers use callee-allocated memory. But if the callee allocates the memory, how can the caller free it after the function call? The caller doesn't know how much has been allocated, and even if she did know, there is still the issue that memory has been allocated on both the server and client side. The caller has no idea how to free memory on the server side. There needs to be some way that a callee can allocate memory that the caller can free—and there is. This is where the COM task allocator comes to the rescue. The COM task allocator is a per-process memory allocator that is used precisely for allocating memory to be shared between processes on either side of an interface. The task allocator is an implementation of the IMalloc interface, but is typically used via the following three COM API convenience functions: |
|
| When you're working with embedded pointers and linked user-defined types, you will be using callee-allocated memory, and these functions will help. Further discussion of the COM task allocator is beyond the scope of this article, but if you'd like to see it explained and put into use, refer
to Don Box's OLE Q&A column in the October 1995 issue
of MSJ.
Strings and Arrays
|
|
| It is interesting to note that with the [string] attribute, the marshaler behaves as it should and will copy the data pointed to until it hits a null. Without the [string] attribute, the data pointed to would have been treated as a single OLECHAR and only two bytes would have been copied by the marshaler. This point is significant when discussing arrays. Without an attribute or some sort of qualifier telling MIDL otherwise, pointers are assumed to point to single instances of a data type.
The simplest form of an array can be passed by fixing its size at design time using C array syntax: |
|
| This example passes a fixed array of four longs with which the marshaler can easily figure out how much data to copy to the server process. However, the most common case is where the size of the array will not be known until runtime. In this situation, IDL provides a series of attributes for specifying the array's size at compile time or runtime. These types of arrays are called conformant arrays, and the size of the array may be defined via the [size_is] attribute. Typically, you will use one of the other arguments in a function to specify the array size using [size_is]. |
|
| You may have noticed that I used C-style variable-length syntax for aItems; a pointer works just the same. The [max_is] attribute may be used in the same situations where you use [size_is]. [size_is] indicates the maximum number of elements in an array, while [max_is] indicates the maximum value for a valid array index. So if you use [max_is] on an array of size n, where the first array element starts at zero, then [max_is] would be set to the maximum valid index, which would be n–1. Both of the attributes use constants for the array size. This is not recommended because it is slower than using a fixed array.
There is another case that I must cover: arrays used as [out] parameters. Imagine that the caller wants to pass in a caller-allocated array that is empty and have the callee fill it up with valid values. This can be done by simply passing in the array with [out] and [size_is] attributes, but that would be inefficient. What if the callee function uses only one-third of the elements in the list? The marshaler would still marshal the entire array back to the caller function's proxy. To get around this problem, IDL has the varying array, which will only transmit back to the caller the array elements that are being used. This is accomplished via the [length_is] attribute, which is only used for [out] parameters. The number used by [length_is] to define the contents of an array is called the variance of the array. The following example illustrates how the [size_is] and [length_is] attributes may be used together to explicitly specify how many array elements need to be marshaled. |
|
| On the way in, the [size_is] attribute lets the marshaler know that the array is cMax longs so the stub will allocate the required memory on the server. But the [length_is] attribute tells the marshaler that only *pcUsed longs need to be marshaled, so they are the only elements of the array that are actually transmitted to the server. Quite efficient!
The [size_is] attribute has [max_is] as its counterpart. They are the same except [max_is] specifies the array size by defining the maximum valid index. [length_is] and [last_is] have a similar relationship. They are the same except [last_is] specifies the number of elements used in the array by defining the last index used by an element in the array. Once again, an array specified as [length_is(n)] is equivalent to one specified as [last_is(n–1)]. To make things even more flexible, IDL also has a [first_is] attribute that can be used to define the index at which the array begins to be used. So in the following example, out of a 100-element array, only 11 elements are actually transmitted—elements 12 through 22. |
|
| For another look at strings and arrays in IDL, check out Don Box's November 1996 ActiveX/COM column. He covers the techniques in greater detail, as well as multidimensional arrays and performance comparisons between the different array-passing techniques.
Type Libraries
|
|
| I've defined a type library called MyLib, which contains an enumeration definition and a DLL interface. The DLL's file name is USER32.DLL, but I am calling the module MyUser32. This module has one entry point: the MessageBeep function. Note that the typedef is within the library statement's braces, but not the module. You can compile it into a type library by running MIDL with the following command line: |
|
| After it's compiled, you can look at the type library with TypeLib Viewer. You can also import the type lib- rary into a Visual Basic-based project by choosing Projects | References, pressing the Browse button, and selecting USER.TLB. After the reference is added and you look in the Object Browser, you will find the module name (in this case MyUser32) appearing in the classes pane on the left. In the members pane on the right, you will see the functions and types exposed for this module. In the bottom pane, you will see the function declaration complete with the help string that I supplied for the function (see Figure 7). |
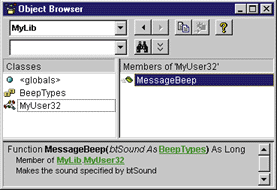 |
| Figure 7 MyUser32 Info |
|
|
|
| As you type in the code, you will notice that Auto List Members has picked up your type information and can offer you choices for the enumeration values (see Figure 8). When you type in the function call, you will see that Auto Quick Info lists all of the data types and data members for you (see Figure 9). |
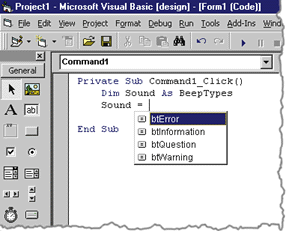 |
| Figure 8 Auto List Members |
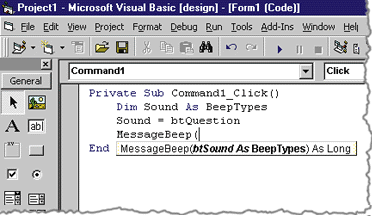 |
| Figure 9 Auto Quick Info |
|
|
|
| the Visual Basic code could make the call with the parameters out of order: |
|
| Integration also occurs with the [optional] attribute. If this attribute is applied to a parameter in the IDL file, Visual Basic treats the parameter as if it were declared with the Optional keyword.
Interfaces
|
|
| COM interfaces have a few more requirements. Once the [object] attribute is specified, you are required to derive your interface from another interface using standard C++ syntax. All interfaces must derive somewhere from IUnknown. Another requirement is that all COM interface methods must return HRESULT so that all methods may return error values in response to network failure. Because IUnknown is not known to MIDL, you must import unknwn.idl, and you must import wtypes.idl for HRESULT. The following is the complete IDL source to generate a simple COM interface proxy and stub: |
|
| If you place an interface inside of a library, proxy/stub code will not be generated for it, though its type information will be included in the type library. Figure 10 shows the COM interface in the type library that I created earlier.
To generate networking code for an interface, just leave it out of the library statement. If you have a function defined in an interface that is outside the type library but you do not want to generate proxy/stub code for it, you can use the [local] attribute on that function to suppress the generation of networking code. This also frees the function from needing HRESULT as its return type. So now that you are defining interfaces, you can reference them as well. You can use the interface keyword with the typedef keyword to define an interface data type: |
|
| You can even pass interface pointers as function parameters: |
|
| However, sometimes you will not know the interface type at design time, so IDL provides support for dynamically typed interfaces with the [iid_is] parameter attribute: |
|
| In the code that called this method, the riid parameter would take the IID of the dynamically typed parameter: |
|
|
Coclasses
The coclass statement is used to define a component object and the interfaces that it supports. The coclass statement is similar to the interface statement, and also requires the [uuid] attribute (which will hold the object's CLSID). The object can have any number of interfaces and dispinterfaces listed in its body, specifying the full set of interfaces that the object implements, both incoming and outgoing. Here's a sample coclass: |
|
| The [source] attribute can be used to signify that a member of a coclass—whether an interface, property, or method—is a source of events, which means that it implements IConnectionPointContainer. With properties and methods, the [source] attribute means that the member returns an object or VARIANT that is a source of events. In this example, the IDerivedInterface interface is made an event source: |
|
|
Dispatch Interfaces
The dispinterface statement is used to create the type information for an IDispatch logical interface that will be executed via IDispatch::Invoke. Because it derives from IDispatch, you should import the Automation type library (stdole32.tlb) to get in all of the types. The dispinterface keyword is similar to the interface keyword in that it requires the [uuid] attribute and lists all of its methods within the braces following its name. However, these keywords differ because dispinterface has two sections inside the body of the definition: properties and methods. The properties section lists variable declarations of Automation-compatible types, and the methods section contains method declarations of Automation-compatible types. Every method and property in the dispinterface is also required to have the [id] attribute, which is used to assign a DISPID to each property and attribute. |
|
| A much more important difference is that a dispinterface doesn't have a vtable. All dispinterface methods and properties are accessed using an index with Invoke.
IDL also provides an easier way to define dual interfaces—by applying the [dual] attribute to the regular interface statement for an interface derived from IDispatch. Defining the interface this way defines the vtable, and then the dispinterface is taken from that same definition. Here's the same interface as in the previous example, but defined the new way: |
|
| Note the naming convention; dispatch interfaces have a D prefix, dual interfaces have a DI prefix, and regular interfaces have an I prefix.
Because IDispatch is a standard interface, Microsoft provides a standard marshaler for marshaling parameters. This marshaler is special because it not only marshals dispinterfaces, but it can also marshal vtable interfaces that meet certain criteria. For this reason it is referred to as the Universal Marshaler or the type library marshaler. No other marshaler is needed if the type library is installed on both the client and server machines. This marshaler can marshal vtable interfaces if they meet the following criteria: the interface uses Automation (IDispatch)-compatible data types (anything that can go into a VARIANT); the interface has a type library where the IDispatch marshaler can get the interface information; and the interface has the appropriate registry entries that identify its type library and that this interface is using the Universal Marshaler as its proxy and stub. The effects of this are great. You don't need MIDL to generate the proxy and stub, so you don't need to declare the interfaces outside of the library block in the IDL file. However, the trick is getting the registry entries into the registry. Fortunately, MIDL will do it for you, but you have to follow closely. Let's consider three scenarios: a dispinterface, a custom interface with the [dual] attribute, and a custom interface. Any interface that is declared in the file as a dispinterface is implicitly Automation-compatible and will automatically get the Universal Marshaler entries put in the registry. Specifying [dual] on a custom interface implies that the interface is compatible with Automation, and so both the custom interface and the dispinterface will use the Universal Marshaler and will get the entries placed in the registry. A custom interface can use the marshaler and will get the entries placed in the registry if that interface is Automation-compatible and uses the [oleautomation] attribute. The [oleautomation] attribute is the key here; that attribute is what turns on the Universal Marshaler for a custom interface. So basically, the only interfaces for which you need MIDL to generate a proxy/stub DLL are custom interfaces that are not Automation-compatible.
Conclusion
From the August 1998 issue of Microsoft Systems Journal.
|