January 1998
![]()
|
How Microsoft Transaction
Server Changes the COM
Programming Model
|
| Microsoft Transaction Server (MTS) isn't magic, but it does let you write simple, COM-based servers that are still powerful and scalable. MTS provides a range of services to those apps, including thread management, efficient object activation policies, and support for transactions. |
| This article assumes you're familiar with COM |
|
David Chappell (david@chappellassoc.com) is principal of Chappell and Associates, an education and consulting firm in Minneapolis, MN. He is the author of Understanding ActiveX and OLE (Microsoft Press, 1996). His next book, due out in 1998, will describe Windows NT distributed services, including MTS.
|
|
The Component
Object Model has changed everything. COM's benefits—well-defined interfaces, local and remote transparency, and much more—allow developers to use it in all kinds of software. But while it solves many of the problems developers have faced, it's arguable whether COM makes creating software a whole lot easier. In particular, building powerful COM servers can be daunting.
Of course, some COM servers are very simple. It's pretty easy, for example, to write a server that never has more than one client at a time, doesn't share information with other servers, and doesn't make changes to persistent data, such as records in a database. This server can be single-threaded and doesn't have to worry about how long it holds database locks. Since it doesn't change anything except its own internal state, this simple server can ignore the possibility of leaving corrupted data behind after an unexpected failure. It would be great if all COM-based servers could be as simple as this. But servers this simple often don't fit the bill. Solving real problems frequently requires building servers that handle many simultaneous clients, effectively share data with other servers, and atomically make changes to one or more databases. Writing servers that meet these requirements can get really hard. But suppose developers had a way to write simple servers—servers that support only one client at a time, don't need to worry about committing multiple database changes, and so on—yet somehow could magically use them to handle many clients, atomically change multiple databases, and more. This is exactly what the Microsoft® Transaction Server (MTS) allows. MTS isn't magic, but it does let you write simple, COM-based servers that are still powerful and scalable. MTS provides a range of services to those applications, including thread management, efficient object activation policies, and support for transactions. By providing all these things automatically, MTS shoulders much of the burden in developing powerful, scalable COM servers. For a general introduction to MTS, see "Microsoft Transaction Server Helps You Write Scalable, Distributed Internet Apps" in the August 1997 issue of MSJ. MTS is built entirely on COM. In many ways, it's just an extension to the COM you already know and love. But MTS also brings some changes to the traditional COM programming model. Using MTS effectively requires understanding what those changes are and how you can take advantage of them. The goal of this article is to explain how MTS changes the familiar COM programming model and how you can take advantage of those changes to create powerful applications more easily. I know that some of you are thinking, "I don't need no stinkin' MTS—I'll just write my COM servers like I always have." There are a couple of reasons why you should shake this bad attitude. First, MTS will make your life simpler—really—so using its services makes a lot of sense. It's a standard part of Windows NT®, so there are no extra checks to write. Plus, MTS is actually just an extension of COM (and like COM, it's becoming part of the operating system), so the integration between the two will only get stronger over time. In other words, the changes that MTS brings to the traditional COM programming model are probably unavoidable. The time to start understanding them is now.
The Five Rules of MTS Programming
Calling SetComplete
|
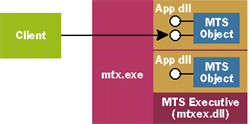
|
| Figure 1 A Typical MTS Application |
|
A client accesses the MTS objects like any other COM object—MTS is invisible to clients, and there's no MTS-specific code on the client—but the client's calls are actually intercepted by MTS before being passed on to their destination object. Because of this, I'll typically show the MTS Executive as sitting between the client and the MTS objects that client is using. And while it's possible for an MTS server and its client to run on the same machine, it's more common for them to be on different machines, with the client accessing MTS objects via DCOM.
To create an MTS object, a client can call CoCreateInstance (from C++) or CreateObject (from Visual Basic®) or some other COM creation function, just as with any COM object. MTS catches this request, however, and does a few special things with it. The most important of these is that, for every MTS object it creates, MTS also creates an associated context object. This context object is (of course) just another COM object, one that supports the IObjectContext interface. The methods in this interface are the primary means that an MTS object has to communicate with the MTS Executive. To call those methods, an MTS object must acquire a pointer to the IObjectContext interface of its context object. Doing this is easy: the MTS object just calls the MTS-supplied API GetObjectContext, as shown in Figure 2. This function returns a pointer to the IObjectContext interface of the appropriate context object. |

|
| Figure 2 Getting IObjectContext Pointer |
|
IObjectContext contains several methods, the most important of which are SetComplete and SetAbort. When an MTS object calls either of these, it's telling the MTS Executive a couple of different things. First, if the object is part of a transaction, this object's work is ready to be committed (if SetComplete was called) or rolled back (if SetAbort was called). I'll say more about transactions later, but whether or not transactions are in use, by calling either of these methods the MTS object is telling the MTS Executive that the object no longer has any state to maintain.
Think about this for a minute. Having no state to maintain means that the object really doesn't need to exist any more—you can just conjure up a new instance when it's needed again. Getting rid of objects that aren't needed right now means that the process those objects are in can take up less memory. For servers that must scale to handle hundreds or thousands of clients, this is a good thing. But at the same time, you don't want each object's client to know about its demise—the client should remain blissfully unaware that its object has gone away. Doing this allows you to build scalable servers while still preserving the appearance of the classic COM programming model for the client. |
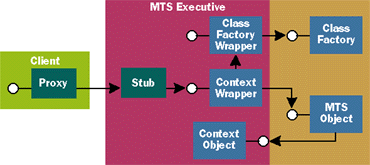
|
| Figure 3 How MTS Wraps Objects |
| To make this possible, the MTS Executive wraps every MTS object as shown in Figure 3. When an MTS object calls SetComplete or SetAbort, MTS releases every interface pointer it holds on this object. Since only MTS actually holds direct pointers to this object's interfaces, this causes the object to self-destruct, just as with any COM object. As shown in Figure 4, the client still holds what it thinks is an interface pointer to the object. In fact, this pointer references the MTS-supplied wrapper. In the jargon of MTS, the object has been deactivated. MTS can now reuse any resources the object maintained, including the memory that was taken up by its data. |
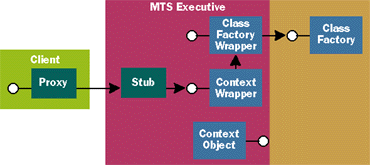
|
| Figure 4 A Deactivated MTS Object |
|
When the client invokes another method on the object (remember, the client doesn't know that it's gone), MTS just uses the appropriate class factory to create another instance of the object, then passes the client's call on to this instance. Known as Just-In-Time (JIT) activation, this causes the situation to return to that shown in Figure 3. Since the object wasn't maintaining any state, this newly created instance is indistinguishable from the one that was destroyed earlier—the client can't tell the difference. Calling SetComplete as often as possible allows MTS to get rid of objects that are no longer needed. Doing this means that your application will scale much better, but it doesn't really affect your clients—MTS shields them from what's going on.
Some observers have criticized MTS for requiring the creation of stateless objects. Obviously, this criticism isn't correct. Instead, MTS allows developers to manage object state in an intelligent way. The simplest way to understand this is to look at an example. Imagine, for instance, an MTS object that implements the interface IOrderEntry. This interface's three methods—Add, Remove, and Submit—allow the object's client to create, build, and submit orders for products. Here's the psuedocode for this interface's (very simple) Add method: |
|
| If no current order exists, the first call to this method creates one. Next, the database is checked to make sure that the requested item exists. If it does, the item is added to the current order and the current inventory count for this item is decremented in the database. Since this method does not end with a call to either SetComplete or SetAbort, the object isn't deactivated, so its state—the in-memory order being built—is available for subsequent calls.
Here's the Remove method: |
|
| It also is very simple—the object just checks that this item is actually in the current order, then deletes it and increments the inventory count in the database. Once again, the method doesn't end with a call to SetComplete or SetAbort, so the object and its state are maintained.
When the client calls Submit, things get more interesting: |
|
| This method begins with a call to the MTS API function GetObjectContext, which returns a pointer to the appropriate context object. The object then submits the completed order—exactly how doesn't matter here. What does matter is that if all went well, this method's final task is to call SetComplete. If anything failed, the method calls SetAbort. I'll talk later about how these calls affect any transaction this object is part of. What's relevant here is that they cause MTS to call Release on every interface pointer it holds on the object. The object and any state that it is maintaining go away. The next time its client calls Add, MTS will transparently create a new instance of the object.
Implementing IOrderEntry in this way is entirely plausible, and an application built like this would scale reasonably well. A client could use what appeared to be the same object to create and submit many orders—it wouldn't need to create a new one each time—but the server would maintain an object only when an order was in progress. An even more scalable design, though, would be for the object to call SetComplete at the end of every method, not just when the order was submitted. For this to work, the Add and Remove methods would need to read the current order (if there was one) from disk, perform their functions, then save the order back to disk at the end of each call. Once the order was safely on persistent storage, each method could end with a call to SetComplete. Building the object in this way would allow MTS to deactivate it after every call, making it even more scalable. The trade-off, of course, is the extra disk accesses required in Add and Remove. There are cases, though, where the increase in scalability matters more than the performance hit. It may even be desirable to save the order persistently after each change. Microsoft Merchant Server, for example, does exactly this, allowing a Web-based client to begin creating an order, lose and reestablish its network connection, then pick up where it left off. The important point is that MTS allows both options. When designing MTS-based servers (something you will do—trust me), you must determine how to manage your state. The rule that MTS encourages is simple: call SetComplete as often as possible.
Acquiring and Holding Interface Pointers
Servers and Resources
Server Roles and Declarative Security
Server Transactions
|
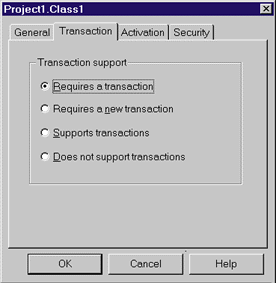
|
| Figure 5 Configuring Transaction Requirements |
|
The way an MTS developer deals with transactions is simple. It's also quite novel, since it merges the idea of transactions with existing notions of components. Unlike traditional transaction systems where a client makes explicit calls to begin and end transactions, MTS hides transaction boundaries from clients. This is another example of how MTS strives to preserve the traditional client semantics of COM, even when transactions are being used. Even more atypically, MTS hides transaction boundaries from the MTS objects themselves.
The benefit of designing things this way is that the same component can run in its own transaction or be combined with others into a larger transaction. If each component made its own BeginTransaction and EndTransaction calls, this wouldn't be possible. By allowing MTS to automatically create transactions when required, it's possible to combine components in various ways. This allows you to create transactional applications from objects that were written by different organizations at different times, yet can still work together. For example, imagine that I have a component that performs order entry functions, like the one described earlier, and another component that knows how to transfer money between two different bank accounts. Each component is useful on its own, and each requires a transaction (otherwise, the changes the component makes might wind up only partially done). But suppose I want to use both components in a single transaction, combining the order entry with actually getting paid for that order. With MTS, doing this is straightforward. Here's how it works. Assume that both components have been configured (using the MTS Explorer, as shown in Figure 5) to require a transaction. A client creates an instance of the order entry component using CoCreateInstance. Since MTS intercepts this request, it can determine that this component needs a transaction, so it automatically starts one. Any changes the order entry component makes will be part of this transaction. Now suppose that the order entry component creates an instance of the money transfer component (it can do this through a method called CreateInstance in IObjectContext). When MTS loads this component, it again notices that a transaction is required. But since the creator of this component is already part of a transaction, the new instance of the money transfer component automatically becomes part of this existing transaction. When the money transfer component completes its task, it will call either SetComplete or SetAbort, like any other MTS object. MTS takes note of this, but does not end the transaction. Instead, the transaction ends only when the order entry component, the root of the transaction, calls SetComplete or SetAbort. If both components called SetComplete, all changes made by the components will be committed. If either one called SetAbort, all changes will be rolled back. The important point here is that the very same component binary can run in its own transaction or can be grouped with one or more other components into a single transaction. Microsoft calls this feature Automatic Transactions. It allows you to combine the traditional idea of transactions with the much newer notion of components—something that's essential for building component-based servers. It also explains why, even if your component only accesses a single database, you don't want to use the ODBC transaction features when MTS is available. Using ODBC transactions means your component will explicitly start and end a transaction, making it impossible to combine with other components into a single transaction. If you rely on MTS for transactions, your component and other MTS components can be combined in arbitrary ways to create transactions. Using MTS allows you to create transactional components that can be used much more flexibly. Using transactions with components also affects how you design those components. To be most useful, each component should encapsulate some discrete chunk of work. Doing this lets you combine that component with others in arbitrary ways. Adding transactions means those useful chunks of work shouldn't span transaction boundaries. For example, think about an application that must submit items of work to a queue, then process those items. It would be entirely possible to create one component that does both tasks, but it might also make sense to handle each of these functions—submitting work and processing it—in separate transactions. If both tasks are implemented in a single component, doing them in separate transactions isn't possible. Think about transaction boundaries before you design your components—the result will be more useful components. |
|
Conclusion
The easiest way to think about MTS is to view it as just an extension to COM. This makes learning to use it easier, since COM has become an ingrained part of development. But MTS also brings a few changes to the traditional way COM programmers have done things. Those changes bring benefits, but change can also be painful. Following the rules described here will help maximize the benefits and minimize the pain. |
|
|
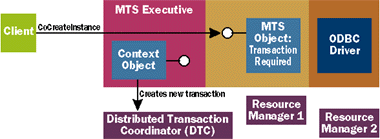
|
| Figure A Starting a Transaction |
| As shown in Figure A, the process begins when the client calls CoCreateInstance or some other COM creation function to create the MTS object. This call is actually caught by the MTS Executive, which (among other things) checks the transaction attribute for this component. I'm assuming that this attribute has been set so that the component requires a transaction. This fact, along with an identifier for the transaction, is stored in the context object associated with the newly created MTS object. To start the transaction, the MTS Executive contacts the Distributed Transaction Coordinator (DTC), which records the fact that this transaction has begun. The DTC is a Windows NT service running in a separate process, and as you'll see it actually handles the work required to coordinate the transaction (another reason why MTS is somewhat misnamed). |
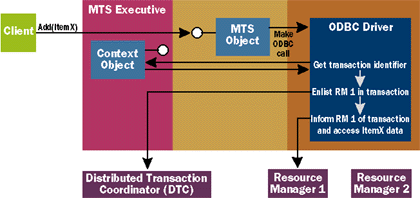
|
| Figure B Adding RM 1 to the Transaction |
|
Figure B shows what happens next: the client invokes the Add method, attempting to add ItemX to the order. When Add is invoked for the first time, an in-memory order is created. The Add method then makes an ODBC call to get a connection to the appropriate database. (Transaction-processing people think of a DBMS as just one kind of resource manager, so I've called this database Resource Manager 1.) When an
MTS object requests a connection to the database, the ODBC driver queries the object's context object to see whether this object belongs to a transaction. If it does, as in this case, the driver contacts the DTC and enlists this database in the transaction. Finally, the driver informs the database itself that all requests until further notice are part of a transaction, then carries out the object's request.
This same process occurs for each database (or resource manager) this MTS object accesses. Figure C shows the same steps occurring when the client adds ItemY to the order. ItemY's inventory information is maintained in the database Resource Manager 2, so it must be enlisted in the transaction as well. |
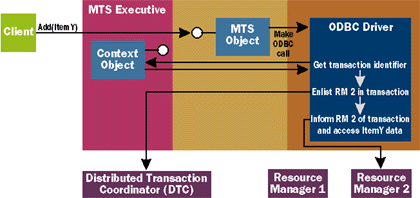
|
| Figure C Adding RM 2 to the Transaction |
| Finally, as shown in Figure D, the client indicates that the order is complete by calling Submit. A call to Submit results in the MTS object calling SetComplete (if anything had gone wrong, of course, it would call SetAbort instead). When the context object receives the SetComplete call, it tells the DTC to commit the transaction. The DTC then carries out the two-phase commit interactions needed to atomically commit the transaction. When XA is used, the DTC communicates with the ODBC drivers, and they in turn talk with the databases to commit the transaction. If OLE Transactions is used instead, the DTC communicates directly with the databases involved. |
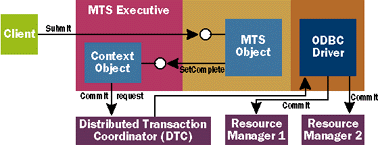
|
| Figure D Committing the Transaction |
| All of the work required to accomplish this is invisible to the MTS object. Once it's configured to require a transaction, MTS (and the DTC) takes over. Even enlisting the databases in the transaction is invisible, since it's done by the ODBC driver. The object on whose behalf all this is being performed can just blithely call SetComplete—MTS does the heavy lifting. |
Don Box
|
MTS represents a new programming model for building distributed, object-oriented applications. To understand how MTS extends the traditional object-oriented paradigm, it is useful to retrace the evolution of object-orientation over the past decade.
Object-oriented software development achieved widespread commercial acceptance in the late 1980s. The hallmark of object-orientation at that time was the use of classes, which allowed developers to model state and behavior as a single unit of abstraction. This bundling of state and behavior helped enforce modularity through the use of encapsulation. In classic object-orientation, objects belonged to classes and clients manipulated objects via class-based references. This is the programming model implied by most C++ and SmallTalk environments and libraries of the era. While it had been possible to achieve many of the benefits of classes using procedural-based languages through the use of disciplined programming styles, widespread acceptance of object-oriented software development did not happen until there was explicit support for object-orientation from tool and language vendors. Environments that were pivotal to the success of object-orientation include Apple's MacApp framework based on Object Pascal, the early ParcPlace and Digitalk SmallTalk environments, and Borland's Turbo C++. One of the benefits of development environments that support object-orientation was the ability to use polymorphism to treat groups of similar objects as if they were all type-compatible with one another. To support polymorphism, object-orientation introduced the notion of inheritance and dynamic binding, which allowed similar classes to be explicitly grouped into collections of related abstractions. Consider the following very simple C++ class hierarchy: |
|
| Because the classes Collie and Pug are both type-compatible with class Dog, clients can write generic code as follows: |
|
| Since the Bark method is virtual and bound dynamically, the method-dispatching machinery of C++ ensures that the correct code is executed. This means that the BarkLikeADog function does not rely on the precise type of the referenced object, only that it is type-compatible with Dog. This example could easily be recast in any number of programming languages that support object-oriented programming.
The class hierarchy I just described typifies the techniques that were practiced during the first wave of object-oriented development. One characteristic that dominated this first wave was the use of implementation inheritance. Implementation inheritance is a powerful programming technique when used in a disciplined fashion. However, when misused, the resultant type hierarchy can exhibit undue coupling between the base class and the derived class. One common aspect of this coupling is that it is often unclear whether the base class implementation of a method must be called from a derived class's version. For example, consider the Pug class's implementation of Bark: |
|
|
What happens if the underlying Dog class's implementation of Bark is not called, as is the case in this code fragment? Perhaps the base class method records the number of times that a particular dog barks for later use. If this is the case, the Pug class has violated that part of the underlying Dog implementation class. To use implementation inheritance properly, a nontrivial amount of internal knowledge is required to maintain the integrity of the underlying base class. This amount of detailed knowledge exceeds the level needed to simply be a client of the base class. For this reason, implementation inheritance is often viewed as white-box reuse.
One approach to object-orientation that reduces excessive type system coupling while retaining the benefits of polymorphism is to only inherit type signatures, not implementation code. This is the fundamental principle behind interface-based development, which can be viewed as the second wave of object-orientation. Interface-based programming is a refinement of classical object-orientation. It assumes that inheritance is primarily a mechanism for expressing type relationships, not implementation hierarchies. Interface-based development is built on the principle of separation of interface from implementation. In interface-based development, interfaces and implementations are two distinct concepts. Interfaces model the abstract requests that can be made of an object. Implementations model concrete instantiable types that can support one or more interfaces. While it had been possible to achieve many of the benefits of interface-based development using traditional first-wave environments and disciplined programming styles, widespread acceptance of interface-based development did not happen until there was explicit support from tool and language vendors. Environments that were pivotal to the success of interface-based development include Microsoft's COM, Iona's Orbix Object Request Broker environment, and Java's explicit support for interface-based development. One of the key benefits of using an environment that supported interface-based development was the ability to model the "what" and the "how" of an object as two distinct concepts. Consider the following very simple Java type hierarchy: |
|
| Because the classes Collie and Pug are both type-compatible with interface IDog, clients can write generic code as follows: |
|
| From the client's perspective, this type hierarchy is virtually identical to the previous C++-based example. However, because the IDog interface's Bark method cannot have an implementation, there is no coupling between the IDog interface definition and the Pug or Collie classes. While this implies that Pug and Collie each have to fully define their own notion of what it means to bark, the Pug and Collie implementers do not need to wonder what side-effects their derived classes will impose on the underlying IDog base type.
One striking similarity between the first and second waves is that each could be characterized by a simple concept (class and interface, respectively). In both cases, it was not the concept itself that acted as the catalyst for success, but instead one or more key environments were required to spark the interest of the software development industry at large. An interesting aspect of second-wave systems is that the implementation is viewed as a black box—that is, all implementation details are considered opaque to the clients of an object. Often, when developers begin to use interface-based technologies such as COM, the degree of freedom afforded by this opacity is ignored, causing novice developers to view the relationship between interface, implementation, and object fairly simplistically. This often results in designs in which the state of an object winds up being very tightly coupled to the COM aspects of the object (its virtual function pointers). While advanced programming techniques such as tearoffs and flyweights can be used to more effectively manage state in complex object hierarchies, these techniques are not formally part of the COM programming model, but instead have evolved as de facto techniques of the COM development community. When applying COM to distributed application development, additional state management issues arise, including distributed error recovery, concurrency management, load balancing, and data consistency. Unfortunately, COM is ignorant of how an object manages its state, so there is little that COM can do to address these issues. While it is possible for developers to concoct their own schemes for dealing with state management, there are clear benefits in having a common infrastructure for developing objects in a state-conscious manner. MTS is one such infrastructure. The COM programming model extended the traditional object-oriented programming model by forcing developers to be conscious of the relationship between interface and implementation. The MTS programming model extends the COM programming model by forcing developers to also be conscious of the relationship between state and behavior. The fundamental principle of MTS is that an object may be logically modeled as state and behavior, but its physical implementation needs to distinguish the two explicitly. By explicitly allowing MTS to manage the state of an object, the application developer can leverage the infrastructure's support for concurrency and lock management, error recovery, load balancing, and data consistency. This means the majority of an object's state must not be stored contiguously with its virtual function pointers (which represent the object's behavior). Instead, MTS provides facilities for storing object state either in durable or transient storage. This storage is under the control of the MTS runtime environment and can be safely accessed from an object's methods without concern for lock management or data consistency. Object state that must remain consistent in the face of machine failure or abnormal program termination is stored in durable storage, with MTS ensuring that all updates are atomic throughout the network. State that is transient can be stored in MTS-managed memory, with MTS ensuring that memory accesses are serialized to prevent data corruption. As with class-based and interface-based development, the state-conscious programming model of MTS requires additional discipline and attention on the part of the developer. Fortunately, as with class-based and interface-based development, the state-conscious model of MTS can be adopted incrementally. Of course, incremental adoption means that the benefits of MTS will be realized incrementally as well. This allows developers to adopt MTS at a pace that is appropriate for the local development culture. From the January 1998 issue of Microsoft Systems Journal. |