June 1999
![]()
| Distributed Authoring and Versioning Extensions for HTTP Enable Team Authoring |
| Distributed Authoring and Versioning has two main benefits. First, it's an open standard, so it will be available on all platforms. Second, DAV is being built into HTTP, therefore you won't need to run an application on top of HTTP or set up a parallel system using SMB or FTP. |
| This article assumes you're familiar with the Internet, HTTP, and COM |
|
Code for this article: Dav.exe (134KB) Leonid Braginski and Matthew Powell are the coauthors of Running Microsoft Internet Information Server (Microsoft Press, 1998),
the definitive guide on Internet Information Server.
Leonid and Matthew work for Microsoft's Developer
Support organization on the Internet Server team.
|
|
The HTTP 1.1 protocol lets you edit Web content from remote locations, but it lacks important features that are needed for team development. For example, you can't lock files and there is no versioning capability. Current HTML distributed authoring tools either lack these features, or use nonstandard, noninteroperable extensions to the HTTP protocol. Distributed Authoring and Versioning (DAV) is a set of HTTP extensions designed to fill this gap. The emphasis is on collaborative authoring of resources that are not necessarily stored in a file system.
The Windows® 2000 version of Internet Information Services (IIS) will ship with an RFC-compliant implementation of DAV. Microsoft has had a DAV solution since the release of the IIS 4.0 Resource Kit, but the DAV specification was not complete at that time, and things have changed drastically since then.
What is DAV? When HTTP was first created, it was simply a way to download files. It quickly became apparent that the protocol needed to be expanded to allow descriptions of the files being downloaded, and needed the ability to send blocks of data that had nothing to do with files. This was accomplished with a series of headers that allowed the server to pass extra information about the data being returned to the client. Similarly, the HTTP methods available to the client were expanded beyond a simple GET to include a POST method for sending data to the server. With HTTP 1.1, additional methods were added to allow you to PUT files onto the server, as well as DELETE files. But that still left a lot to be desired. Although the Web was a perfect mechanism for presenting published data, the act of assembling the data for a standard collaborative workgroup of people had to be done outside of the scope of the HTTP protocol. HTTP provided a mechanism for putting a single file on the server, but there was no way to keep multiple people from overwriting each other's changes. The common acts of copying and moving files required a file transfer to the client and then back to the server. In the absence of an HTTP protocol solution to these problems, workgroups found other solutions. There are a number of applications that provide team authoring capabilities on top of HTTP (Microsoft® FrontPage is one example), but they use proprietary mechanisms to accomplish these tasks. Let's take a look at what DAV has to offer. DAV has two main benefits. First, it's an open standard so it will be available on all platforms. We will be focusing on the Microsoft Windows platform, but you could potentially have DAV clients on Unix, Macintosh, AS400, or even on proprietary hardware devices. Similarly, your DAV client on a machine running Windows could publish information to any number of other Web servers. This is possible because the implementation is at the protocol level, which brings us to the second advantage. DAV is being built into HTTP, so you won't need to run an application on top of HTTP or set up a parallel system using SMB or FTP. The nature of HTTP makes it very extensible. New methods and constructs such as those provided by DAV can be added to extend HTTP without losing or limiting the capabilities that it already has. In our discussion of DAV, we will talk a lot about "files" and "directories" because this is convenient and easily understood. In reality, there is nothing specific to file access in DAV. We could just as well talk about accessing database records or any other type of object that uses the concept of a collection.
DAV Details In a system where multiple users may try to write changes to a file simultaneously, we must have a method for synchronizing access. Otherwise, some of the changes may be overwritten and the consistency of the data may be corrupted. DAV provides LOCK and UNLOCK methods to create and track locks on the files to which users are writing. Every file has information associated with it in addition to its contents. For example, files on our hard drives have associated information such as file size and creation date. HTTP has provided a mechanism for receiving some of this data through headers. For example, the HTTP Content-Type header is used to associate a MIME type with the data in the body of the HTTP request or response. But creating and defining HTTP headers for every possible file characteristic would be unrealistic. The properties that people want to store about a file may be very situation-specific. Therefore, DAV uses Extensible Markup Language (XML) to allow clients to make property queries. HTTP encapsulates the DAV request method (either PROPFIND or PROPPATCH) and serves as the transport for the XML data that contains the details. The actual response includes the properties for the requested object. In a world where the relationship between objects is usually a hyperlink, it can be quite difficult to group objects together in a logical fashion. Let's say you associate a virtual directory on a server like /scripts with a collection. You might imagine that making a request for the collection object would enumerate the collection. But this will not normally be the case since a file called default.htm or index.htm is usually the default page for a virtual directory. So in the HTTP namespace, the definition of a collection is looser than what we are used to with file system directories. But with DAV, we have the ability to enumerate collections and their children through the use of property queries. This parallels file system enumerations—you get a list of file properties like name, size, and date, just like you do when you enumerate the files in a directory. You can copy files between locations on a server without DAV if you perform a GET on the source and then a PUT to the destination. But this approach is inefficient and slow—especially if you connect to the network via a slow dial-up link. Since the source and destination exist on the same machine, a simple file copy would be much faster, limited only by hard drive access times. You can also move files from one location to another without DAV by using the GET, DELETE, and PUT methods. But as with copying, this is very inefficient. The ability to move files between locations on the server can make for much more efficient Web publishing.
Methods The HTTP protocol consists of a variety of methods (or request verbs). They all are fully explained in RFC 2068, "Hypertext Transfer Protocol?HTTP/1.1". We will spare you all the HTTP protocol details here. Instead, we will focus on the new methods offered by DAV, and changes in some old HTTP methods when DAV is involved. When testing new HTTP methods, it is common to use a telnet client to connect to a Web server's port (80 is the default) and type commands directly into a command window. A better solution would be to have a tool that allows you to construct requests by combining their components (the URL, the verb, and the request headers), and then send the request to the server. We created a tool that does this called HTTP Request Builder (see Figure 1), and you can download it from the link at the top of this article. We won't discuss the details here, but you are welcome to look at (and improve) this tool's source code. |
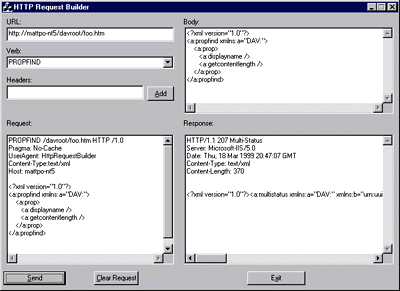 |
| Figure 1 HTTP Request Builder |
|
GET This is the simplest method in HTTP. In fact, it was the only method in the original HTTP 0.9 protocol. It does exactly what the name implies: it gets a URL from the server. GET works on all kinds of Web servers, with or without DAV support. A GET request for a specific URL, say /hello.htm, retrieves the hello.htm file. GET also works on collections. The data returned depends on the server's configuration. For example, even if a collection consists of multiple files, the server may be configured to return a specific file (such as index.html) for collection queries. The content of the file may or may not describe the collection itself. In other words, index.html may or may not contain a directory listing of the requested URL.
OPTIONS An OPTIONS request is used by client applications to request a list of all supported methods. This method is part of the HTTP specification and the server does not have to support DAV to implement it. It can be very important to know if a server allows a particular method before wasting network bandwidth trying to send an unsupported request. Here is an example of a correctly formatted request: |
|
| The server's reply contains a status code and response headers, but no body: |
|
| Two headers are of particular interest: Public and Allow. The Public header contains all the methods supported by the server. The Allow header lists only the methods supported for the specific URL. As you can see in the previous example, even though IIS 5.0 supports POST, it is not supported for the static HTML file default.htm.
Our WebDav sample program will use the OPTIONS method for two purposes. First, it will check for the DAV support header. Second, it will determine whether the URL can be written by checking whether the PUT method is supported. This brings us to another HTTP method used with DAV: the PUT method.
PUT and MKCOL The PUT method allows clients to directly create a resource at the indicated URL on the server. The server takes the body of the request, creates the file specified in the URL, and copies the received data to the newly created file. If the file exists and is not locked, the content of the file will be overwritten. The nice thing about PUT is that there is no need to write any server scripts or code to handle received data. All the functionality is built into IIS itself. Of course, to be able to perform a PUT, the server must enable write privileges for the specific directory. Here is an example of a PUT request: |
|
| After receiving this request, IIS reads the 47 bytes of the request body (don't forget to count the characters "\r\n" after "?" as newline marks), creates a file called newfile.htm in the /upload directory, and then sends the following reply to the client: |
|
| The "200 OK" status code indicates that the server did not create newfile.htm from scratch; it has updated an existing file. If newfile.htm did not exist before we executed our PUT request, the server would return a "201 Created" status code with a corresponding message in the body of the reply.
Even though DAV-enabled servers use this method, PUT is described in the HTTP RFC and hence will work on older servers. Be aware that PUT requests do not work with collection items. It's not possible to create a directory (collection) with a PUT request. The DAV specification has a special verb, MKCOL, to create an entire collection. If the URL for a PUT request is /Dir1/SubDir2/File.htm, PUT will only succeed if the directory hierarchy /Dir1/SubDir2 already exists. The correct way to create /Dir1/SubDir2/File.htm takes three steps. First, create a collection for Dir1 by creating an empty directory: |
|
| Second, create a collection for SubDir2: |
|
| Finally, create a file in the newly created collection: |
|
| If Dir1 does not exist, the request MKCOL /Dir1/SubDir2 will fail with a "402 Conflict" status code. Once the file or collection is created, you can delete it with the DELETE method.
DELETE If a directory has write permissions, it is trivial to delete a file. The client sends the following request: |
|
| If the file is deleted successfully, then the server replies with a "200 OK" status code: |
|
| Using the DELETE method on collections is a little more complex. The DELETE method assumes the Depth header is set to infinity. The Depth header is a way to define the scope of a request. "Depth: 0" indicates that the request only applies to the actual entity in the target URL. "Depth: 1" means that the request applies to the target URL and any immediate child entities it may have. This is equivalent to performing an operation on all the files in a directory, but not in any subdirectories. "Depth: Infinity" implies that the operation applies to the entity, its child entities, and all subentities beneath it.
A depth of infinity makes a lot of sense when executing the DELETE method since you can't delete a directory and not delete the files and subdirectories it contains. Therefore the server tries to delete all files in the collection. If an individual item in the collection can't be deleted, then the container itself should not be deleted. In this situation, the server would reply with a "207 Multi-Status" status code and the body of the reply would contain the URL for the collection that caused the problem. This might occur, for example, if a file is exclusively locked for writing. The next two methods come from the DAV specification. The HTTP 1.1 specification does not have any notion of moving and copying files directly on the server.
COPY and MOVE As we have mentioned earlier in this article, without DAV, copying and moving files directly on the Web server is a problem. It requires bringing files to the client machine with a GET request and then uploading them back to the server with a PUT request. The COPY and MOVE methods described in the DAV protocol avoid the deficiencies of the GET/PUT combination by allowing you to copy either a specific URL or a collection from one location to another. Both methods use a request URL as a source and a destination header as a target. In the absence of the depth header, infinity is assumed. This means that if we want to copy or move the /Directory/ collection, by default the entire structure of the source directory will be copied or moved. The MOVE method performs some additional work beyond the COPY method. It copies the source URL to the destination, checks the integrity of the newly created URL, and then deletes the source URL. When a collection or element is copied, by default all its properties are copied too. However, a request may contain an optional body with an XML property behavior element that supplies additional information for the operation. You can specify that all properties must be copied successfully for the operation to succeed, or define which properties must be copied for the operation to succeed. For example, imagine a file system where files can be copied to different locations with or without associated properties such as file creation date, last modified date, archive bit, and so on. By default, a copy or move would transfer all these properties to the target location. However, it may be possible to issue a copy or move command with specific command-line parameters that would indicate which file attributes must be copied or moved for the entire operation to be successful. These hypothetical command-line parameters would be implemented as optional XML text that accompanied the request. Both the COPY and MOVE methods use the Overwrite header to control the behavior of the request. This header can be set to T or F. If the destination exists prior to copying or moving a resource and "Overwrite: T" is present, then the server will first call DELETE with "Depth: Infinity" for the target URL. If "Overwrite: F" is present, the server will report an error. Let's take a look at the simple operation of copying an entire collection (that is, an entire directory hierarchy) from the directory /upload to the directory /MyDir1/MyDir2. Note that the directory /MyDir1 must first exist, and can be created with the MKCOL method: |
|
| Since we are happy with the default action of the method with regard to element properties, we did not add an optional XML body with a property behavior element. The server created the /MyDir1/MyDir2 structure and reported success: |
|
| Now that directory structure is created, if you try to execute the same request again, you'll get an error due to the "Overwrite: F" header: |
|
| The request failed because we set a precondition: if the collection already exists in the destination, then the operation must fail.
PROPFIND The PROPFIND method is used to discover properties of DAV resources. You can use it to request a single property, all properties, or all property names. You can also use the PROPFIND method to make requests that involve more than just the particular resource indicated in your URL. DAV supports the use of the Depth header to allow you to do PROPFIND requests on your resource and every resource that it contains. This is how you can enumerate the contents of a collection. Let's take a look at how the PROPFIND method works. We'll start by looking at a simple example: |
|
| Notice that the Content-Type header indicates that the body of the request is in the mime-type format text/xml. Basically, this means that the body is an XML document. The Depth header tells us that the depth scope is zero. The PROPFIND method lets us submit a request for more than one file at a time. For instance, I could find properties for every file in a directory. In this sample we are only looking for properties of the item specified in the URI. Later in this article we will look at some PROPFIND requests where the Depth is not zero.
XML and DAV XML was created to address problems that HTML was too static to handle. XML allows you to describe your data in any fashion that you see fit. Along with whatever descriptive XML you may have produced, there must be a description of the schema associated with your XML. Typically this indicates the relationships between parent and child entities, whether a child entity is required, what data values are allowed within certain entities, and a list of entity attributes and their potential uses. Traditionally, the schema definition for XML documents is kept in a Document Type Definition (DTD) file that is referenced within the XML document itself. Therefore, when trying to interpret an XML document, you would dig through it looking for the DOCTYPE definition entity that would give you the name of the DTD file associated with your XML. For common document types like those defining the schema for DAV XML, it makes more sense to use a namespace. Our DAV XML uses the "DAV:" namespace, which basically means that all XML entities will be prefixed with "DAV:". Any software parsing our DAV XML will recognize this prefix as a reference to the DAV XML schema defined in the DAV specification. This allows our software to make assumptions on the schema of the XML without having to read in DTD files and interpret them correctly. The common prefix "DAV:" can be a bit tedious to write, so XML namespace support allows the use of a shorthand to save typing. First, we specify the namespace by using the xmlns attribute in our root entity like so: |
|
| The xmlns attribute indicates that wherever we see a: we can treat it as if it is replaced with DAV:.
Similarly, a reference can be made with the xmlns attribute to a URL that defines another namespace. For example: |
|
| This indicates that any time we see the prefix b: for an entity or attribute, it refers to the namespace uniquely defined by the specified URL. This happens to indicate the datatypes namespace, which defines common datatypes like integers, strings, and so forth. Now we can mix namespace definitions within our document by simply associating the a: prefix with the DAV namespace and the b: prefix with the datatypes namespace.
After we're finished looking at the HTTP headers, we need to look at the specifics of the HTTP body. In our case, the body is an XML document as specified by the Content-Type header. As with all XML documents, our document starts with the XML declaration <?xml version="1.0"?>. For the DAV request, we are using an XML schema specific to DAV. The DAV namespace is indicated by the xmlns=a:"DAV" part of our first entity definition. The main entity of our PROPFIND request is a propfind XML entity. The details of our request are located within this propfind entity. The particular properties we are interested in are indicated within the subentity prop. We are looking for two properties: displayname and getcontentlength. The response to our PROPFIND request is shown in Figure 2. First, we need to look at the HTTP headers in our response. The HTTP response code 207 indicates that it's a multistatus response. DAV allows us to make requests of several entities at the same time, so we have a new response code that indicates multiple responses are included. For simplicity, even if we are only requesting information on a single object (as is the case here), DAV replies with a multistatus response that has only a single response subentity. Again the content type for the body of our response indicates that it's an XML document. In the body of our response we have a multistatus XML document entity. This is simply a construct with the potential for holding a list of responses. The subentities within our multistatus entity are response entities for each file or directory it encapsulates. The response entity consists of an href that gives the URL to the object involved and a propstat entity that lists the properties requested along with a status code to indicate if the response was successful. As it turns out, the status looks much the same as a normal HTTP response status line. The specific properties are listed beneath the prop entity. This is where you can find the common name and size information encapsulated within our commonname and getcontentlength entities. If we want to enumerate all the elements in the directory, we simply need to change the Depth header in our request from "Depth: 0" to "Depth: 1". This will give us a listing of information for all files and directories underneath any potential collections. We will also change our target URL in order to point it at a collection instead of a single file. The request will now look like this: |
|
| The request is exactly as before except for the target URI and the Depth header. The response, however, is now going to contain multiple response entities for each item in the directory, as shown in Figure 3.
Notice that we have four responses for our property query. Also notice that for each response we received a successful "200 OK" status. The specific properties we requested are listed, so we could now either use the information to display the results in an XML viewer or use the information ourselves in our program's own internal structures. Finally, notice that the first response entity in our multistatus response is the response for the actual collection item that was the target of our request. There are a couple other options available for getting property information on directories and files. The first provides a list of all the property names that are supported for our object. We accomplish this by using the propname attribute within our request's propfind entity. A request for all the property names on an object would look like this: |
|
| The result for standard HTML files on an IIS 5.0 server is a list of the following properties. |
|
| Property | Description |
|
getcontentlength |
Returns the size of the file. |
|
creationdate |
The date the file was created. |
|
displayname |
The common name for the file. |
|
getetag |
The HTTP 1.1 ETag associated with the
file to indicate the current version. |
|
getlastmodified |
The last date the file was modified. |
|
resourcetype |
Specifies whether this is a collection.v |
|
lockdiscovery |
Returns all the DAV locking information on the file. |
|
supportedlock |
Returns information on what types of locks are supported on the object. |
|
ishidden |
Indicates whether the file is hidden. |
|
iscollection |
Indicates whether the file is a collection, such as a directory. |
|
getcontenttype |
Returns content type of the document (same as the Content-Type header returned by IIS for the document). |
| The last option we have for getting property information is not a request for any specific property at all. Instead, it lets us request all the properties available for the file by using the allprop entity. It is used much like the propname attribute. The XML body of a request for all properties would look like the following: |
The PROPPATCH method provides a means for setting properties on a URI. Later, we can use PROPFIND queries to get the information that we are setting. For instance, if we wanted to specify the name of the owner of an object, we would send a request that looked like the following: |
|
| First, you see the PROPPATCH method. The rest of the HTTP headers look similar to the PROPFIND method, though the body of the request looks a bit different. The base entity of our XML document is the propertyupdate entity instead of the propertyinfo entity we used for the PROPFIND method.
We also see that the direct child of our base entity is not the prop entity, but instead we have a middle-tier entity. This is the set entity, which indicates that we are trying to set the contained list of properties. This is how we set the file property. To delete a file property, we can use a remove entity instead of the set entity.
LOCK In a workgroup situation, file locks must be available so that people don't overwrite one another's changes. DAV supports locking via the LOCK method. LOCK is another method that sends XML in the body of the request. Here is a simple LOCK request: |
|
| The XML being submitted has the lockinfo entity as its base entity. We are setting three values within our lockinfo structure: locktype, lockscope, and owner. The locktype indicates that this is a write lock. You could potentially also have a read lock, but IIS only supports write locks.
The lockscope determines if this is an exclusive lock or a shared lock. This happens to be an exclusive lock, so no one else will be able to access the file while the lock is in place. If we had a shared lock, we would have to coordinate with the other shared lock owners. The final property we are sending with our lock is a URL that indicates the owner of this lock. If other people try to lock the file while this lock is in place, they will receive a lockdiscovery XML document that indicates this owner. Hopefully the specified URL will provide enough information to identify the individual. The response to our lock request is shown in Figure 4. We have successfully received a lockdiscovery XML document embedded within a prop entity. The lockdiscovery entity provides all the information we need to know about our lock. Within the lockdiscovery entity we have an activelock entity that holds the information we sent with the request—the locktype, lockscope, and owner. It also includes a locktoken, a depth entity, and a timeout value. The depth entity is used in the same way as the Depth header that we discussed previously. In this case, a value of zero lets us know that the lock only applies to the specific file in the URL. The timeout value tells us that this lock will expire in 180 seconds. This doesn't give us a lot of time to edit our file before we lose our lock. If we need more than 180 seconds, we will need to refresh our lock. The most important value in the response is the locktoken, which uniquely identifies our lock and is used with future requests. Because HTTP does not maintain any state information between requests, we need the lock token to know who is actually writing to the file at a later time. We will need to send this value when we unlock our resource and when we do a PUT, COPY, or MOVE to overwrite the file we have locked. It is also sent when we refresh our lock, which is done by sending another LOCK request. We use the If HTTP header to send our lock token when we send it with a PUT, COPY, MOVE, or LOCK refresh request. The If header has the following format: |
|
| Basically this says to perform the requested operation if the indicated state matches the current state of the file. Specifically, if the lock token for the http://mattpo-nt5/davroot/foo.htm resource matches that indicated, then the requested command is completed.
UNLOCK The UNLOCK method simply removes a lock on a resource. The format is simple: |
|
| For unlock, we don't need to indicate a set of complex properties, so we can accomplish the task by sending an HTTP request without a body. The lock token we are releasing is passed in the Lock-Token header. If the unlock is successful, we receive a "204 No Content" instead of the standard "200 OK" response. This is a 2xx-level error, so it indicates that the command completed successfully. The reason we have a "No Content" status is because there is nothing for the server to return to the client beyond the status. The response body is empty.
DAVClient: Overview DAV enables Internet users to truly collaborate online. Applications running on various hardware and software platforms can share the same Web documents, retrieving information about them and editing them simultaneously. The RFC describes quite a few methods that can be used to create DAV-enabled applications. We have created a sample application called DAVClient that demonstrates a few of these methods. DAVClient allows a user to retrieve a document from a Web server. The user can then modify the document and return it to the server, simulating a File Open/Edit/Save transaction in a normal text editor. However DAVClient goes a step further. To prevent multiple users from corrupting documents during save operations or downloading corrupted versions while documents are being edited, the sample application uses DAV to create exclusive locks on the file. Here is the sequence of the requests that must be submitted to the server to implement the edit and save operations. First, the URL is locked for exclusive write with a LOCK request. The file is then retrieved with a GET request. Next, the file is edited and uploaded back to the server with a PUT request. Finally, the exclusive write lock is removed with the UNLOCK request. If John, who uses the DAVClient application, decides to edit the document while it is being edited by Jane, the locking operation will fail. He will see an error message that says the document is locked by Jane. Note that locking functionality is only available with DAV-enabled Web servers. |
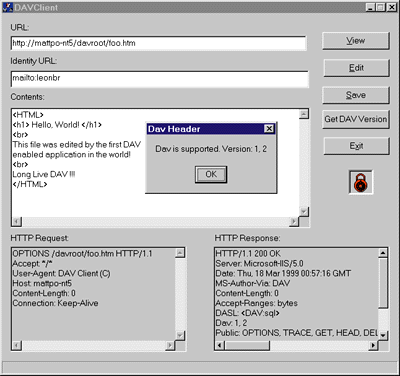 |
| Figure 5 DAVClient |
|
Figure 5 shows the DAVClient application in action. The URL is being edited and the bright red lock on the right side indicates that we currently have the file locked through DAV. To determine if DAV is enabled on the server, we clicked on the Get DAV Version button, which pulls the version information from the OPTIONS request that
we submitted.
Implementation Details The DAVClient application uses the MFC WinInet classes for most of its Internet functionality. Sending and receiving DAV-specific information involves composing and parsing XML as well. Microsoft Internet Explorer 5.0 provides reusable COM classes that enable easy creation and parsing of XML buffers. These classes also can handle simple HTTP requests that don't need to return XML information in the request or reply body. It would be possible to write an entire DAV application using the XML Document Object Model (DOM) interfaces. But you may want to stick with normal WinInet in cases where its flexibility eases tasks like posting large files to your site. In our sample application, all the WinInet functionality is encapsulated in a class called DAV. The DAV class is responsible for parsing the URL into its components: the server, the object, and the port. The ParseAndConnect method takes a URL, parses it, and establishes a connection to the server. Here is the function prototype: |
|
| The DAVClient application needs to know whether the server supports DAV. This verification is done in the DAV::IsDav method by sending an OPTIONS HTTP request. As described in the DAV specification, the presence of the Dav: header in the server response indicates that the server supports DAV. IIS 5.0 returns "Dav: 1, 2". The numbers in the header indicate what DAV compliance classes are implemented for a specific resource. IIS 5.0 implements Level 1 and Level 2 compliance classes.
Compliance classes let you know how much of RFC 2518 (HTTP Extensions for Distributed Authoring?WEBDAV) the server implements. The DAVClient application is not too picky, so if the Dav header can be found at all, the support is sufficient. In a production application, you may want to actually check compliance classes and, depending on what is implemented, chose a different code path. After the server's reply is received, the DAV::bDavSupport Boolean class property is set accordingly. For DAVClient to be able to save documents back to server, the URL must allow a PUT request. In IIS, the PUT method is enabled for all directories configured with write permissions. The Allow response header generated for the OPTIONS request may or may not contain a PUT method. The absence of the PUT verb in the Allow header indicates that the URL can't be saved, so the DAV::bWritable property is set to FALSE and the application disables the Save button. There are some other options for when we enable and disable the Save and Edit buttons based on whether the file exists and so forth. For details, take a look at the source code, which is contained in the file DAVClientDlg.cpp. The DavXML class encapsulates our XML functionality, including the use of the IXMLHttpRequest interface that is part of the Internet Explorer 5.0 XML DOM object model. The file DavXML.CPP (see Figure 6) contains the code for the Lock method of the DavXML class that issues the LOCK request and saves the lock token. For clarity, we've pulled out the error handling code and extra code that displays the HTTP request and response for the dialog display. The Lock member function of the DavXML class starts off by creating an instance of the XMLHttpRequest object. It then calls the object's open method to set the URL, the method (LOCK in this case), and blocking options. We then create an instance of the XMLDOMDocument class to help us to build the XML for the body of our request. We use the LoadXML member function to input a string that lays out the template for our XML. We can then use the convenient selectSingleNode method to pull out any particular nodes that we need to set with nonconstant information. The selectSingleNode function takes an XSL string as input and uses it to perform a query against the XML document. Our query simply contains the full path to the node we need to retrieve: a:lockinfo/a:owner/a:href. Now we can set the actual owner URL for the lock request, which we do by calling the putText method on the node object that was returned from our call to selectSingleNode. Once the XML is in place, we call the XMLHttpRequest object's send function with a pointer to our XML document as the body. The response can then be retrieved with get_ responseXML into another XMLDOMDocument object. This allows for easy access to the specific information through an XSL query, as we did before with selectSingleNode. The DavXML class also provides an Unlock member function that passes the lock token back with a request that uses UNLOCK as the method. The UNLOCK method doesn't use XML, so it's simple. Remember that a successful unlock response has a status code of "204 No Content" instead of "200 OK".
Other DAVClient Features DAVClient implements a fairly complete locking mechanism for Web access that illustrates some of the power that DAV can give you. But what else could we do with DAV in our application? First of all, DAVClient assumes you are a pretty fast editor because the lock that IIS provides expires after three minutes. If you wanted to take longer than three minutes to edit the file, a smarter DAVClient would send a lock refresh request using the LOCK method with an If HTTP header to indicate the lock token you're refreshing. DAVClient has you type in the full URL in an edit control, but DAV allows you to enumerate files within a directory or collection. Therefore, you could let users browse the Web site instead of typing in the complete URL by using the PROPFIND method to enumerate the files in the various Web directories. Finally, we haven't taken advantage of the COPY, MOVE, or DELETE methods that you can use to transfer content from one location on your server to another. DAV is useful whether you're building a Web publishing application or simply trying to extend your traditional File>Save options. The DAV vision is being implemented in Internet Explorer 5.0 through the XML HTTP Request object, and on the server with IIS 5.0 (shipping with Windows 2000).
|
|
From the June 1999 issue of Microsoft Systems Journal.
|