![]()
|
This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.
|
|
Using Speech Recognition with Microsoft English Query
Ed Hess |
Speech recognition is a rapidly maturing technology. It's a natural complement to English Query, a package that lets you query a SQL Server database using natural language.
|
My job is to help developers design GUIs from the point of view of the people who will use the software. I'm currently doing research on how speech recognition can enhance the job performance of users in a health care setting.
Speech recognition offers certain users the best way to interact with a computer and promises to be the dominant form of human-computer interaction in the near future. The Gartner Group predicts that by 2002, speech recognition and visual browsing capabilities will be integrated into mainstream operating systems. According to a recent survey of more than a thousand chief executives in health care organizations by Deloitte & Touche Consulting, 40% planned to use speech recognition within two years. Recent advances in software speech recognition engines and hardware performance are accelerating the development and acceptance of the technology. Microsoft® invested $45 million in Lernout and Hauspie (http://www.lhs.com) in 1997 to accelerate the growth of speech recognition in Microsoft products. Both IBM/Lotus and Corel are delivering to the market application suites that feature speech recognition. Most people are familiar with speech recognition applications based on dictation grammars, also known as continuous speech recognition. These applications require a large commitment from the user, who has to spend time training the computer and learning to speak in a consistent manner to assure a high degree of accuracy. This is too much of a commitment for the average user, who just wants to sit down and start using a product. Users of this technology tend to be those who must use it or are highly motivated to get it working for some other reason, like people with various physical disabilities. However, there are other forms of speech recognition based on different grammars. These grammars represent short-run solutions that can be used by more general audiences. Grammars A grammar defines the words or phrases that an application can recognize. Speech recognition is based on grammars. An application can perform speech recognition by using three different types of grammars: context-free, dictation, and limited-domain. Each type of grammar uses a different strategy for narrowing the set of sentences it will recognize. Context-free grammar uses rules that predict the next words that might possibly follow the word just spoken, reducing the number of candidates to evaluate in order to make recognition easier. Dictation grammar defines a context for the speaker by identifying the subject of the dictation, the expected language style, and the dictation that's already been performed. Limited-domain grammar does not provide strict syntax structures, but does provide a set of words to recognize. Limited-domain grammar is a hybrid between a context-free grammar and a full dictation grammar. Each grammar has its advantages and disadvantages. Context-free grammars offer a high degree of accuracy with little or no training required and mainstream PC requirements. Their drawback is that they cannot be used for data entry, except from a list of predefined phrases. They do offer a way to begin offering speech capabilities in products without making large demands on users before they understand the benefits of speech recognition. They represent an ideal entry point to begin rolling this technology out to a general audience. You can achieve up to 97% recognition accuracy by implementing commands and very small grammars. Dictation grammars require a much larger investment in time and money for most people to be able to use in any practical way. They deliver speech recognition solutions to the marketplace for those who need them now. Lernout and Hauspie's Clinical Reporter lets physicians use speech recognition to enter clinical notes into a database, then calculates their level of federal compliance. Speech recognition is an excellent fit for clinicians, who are accustomed to dictating patient information and then having transcriptionists type that data into a computer. The feedback from early adopter audiences is helping to accelerate the development of usable speech recognition interfaces. None of the current speech recognition vendors are achieving greater than 95% accuracy with general English dictation grammars. That translates to one mistake for every 20 words, which is probably not acceptable to most people. The problem is further magnified when a user verbally corrects something and their correction is not recognized. Most users will not tolerate this and will give up on the technology. If a more limited dictation grammar is used, levels of accuracy over 95% can be achieved with a motivated user willing to put in months of effort. Limited-domain grammars represent a way to increase speech recognition accuracy and flexibility in certain situations without placing large demands on users. An application might use a limited-domain grammar for the following purposes:
English Query I had been working with Microsoft Agent (http://www.microsoft.com/msagent) for a couple of months before I saw Adam Blum's presentation on Microsoft English Query at Web TechEd. His session inspired me to try hooking speech recognition up to English Query to find information in a SQL Server™ database. I'd been showing around a speech-based Microsoft Agent demo, and many people asked if I could somehow keep the speech recognition, but make the animated character interface optional. Because I wanted to research that while still being able to use different types of speech recognition grammar, I started looking into the Microsoft Speech API (SAPI) SDK version 4.0, which is available at http://www.research.microsoft.com/research/srg/. English Query has two components: the domain editor and the engine. The English Query domain editor (mseqdev.exe) creates an English Query application. An English Query application is a program that lets you retrieve information from a SQL Server database using plain English rather than a formal query language like SQL. For example, you can ask, "How many cars were sold in Pennsylvania last year?" instead of using the following SQL statements: |
|
| An English Query application accepts English commands, statements, and questions as input and determines their meaning. It then writes and executes a database query in SQL and formats the answer.
You create an English Query application by defining domain knowledge and compiling it into a file that can be deployed to the user. More information about how to build English Query applications can be found in the article " Add Natural Language Search Capabilities to Your Site with English Query," by Adam Blum (MIND, April 1998). English Query was delivered with SQL Server Version 6.5 Enterprise Edition, and is also part of SQL Server Version 7.0. The English Query engine uses the application to translate English queries into SQL. The Microsoft English Query engine is a COM automation object with no user interface. However, four samples included with English Query provide a convenient UI for Internet, client-based, middle-tier, or server-based applications. You must install the domain editor to build an English Query application. However, to use an existing English Query application with a client user interface, you need only install the engine. The English Query engine generates SQL for Microsoft SQL Server 6.5 or later; these queries may generate errors on other databases, such as Microsoft Access. With a patient orders database as a starting point, I went through the typical steps of creating an English Query application (see Figure 1). I'll skip the details of setting up the English Query application for my database. Since it's only a prototype, I just set up a couple of entities (patients and orders) and minimal relationships between entities ("patients have orders"). |
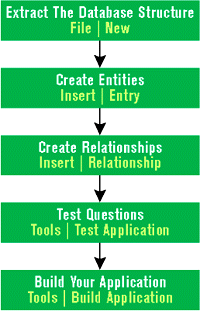 |
| Figure 1: Query Steps |
|
I started with the sample Visual Basic-based query application that comes with English Query and modified it to point to my application: |
|
| I then modified the connection string in the InitializeDB function to point to my SQL Server database: |
|
| My English Query application then looked like what you see in Figure 2. |
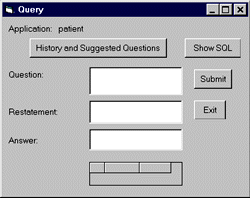 |
| Figure 2: An English Query App |
|
The next step was to add the Direct Speech Recognition ActiveX® control (xlisten.dll) to my Visual Basic Toolbox. The control comes with the SAPI 4.0 SDK, so you will need to download and install that first. After I added the control to my form, I set its Visible property to False and added the following code to Form_Load: |
|
|
| The patient.txt file referenced in the DirectSR1.GrammarFromFile method contains my grammar, or list of recognized voice commands. I wanted to make my demo as bulletproof as possible, and I have found context-free grammars to be the most reliable. Because a context-free grammar allows a speech recognition engine to reduce the number of recognized words to a predefined list, high levels of recognition can be achieved in a speaker-independent environment.
Context-free grammars work great with no voice training, cheap microphones, and average CPUs. (This demo should work fine on a Pentium 150 MMX notebook with a built-in microphone.) The demo could be made even more powerful by using dictation grammars, voice training, more powerful CPUs, and better microphones, but I wanted to make as few demands as possible on the user and remain speaker-independent. My grammar file (patient.txt) looks like this: |
|
|
| Langid=1033 means the application's language is English type=cfg means this uses a context-free grammar. The <start> tags define each of the recognized voice commands. The first command translates to any words (
) followed by the phrase "orders for patient" followed by a list of digits. <Digits> is a built-in item in the direct speech recognition control (DirectSR1), which recognizes a series of single digits. If I can command my app to "Show the orders for patient 1051762," they appear like magic (see Figure 3). In the commands after the orders command, the words before the quotes are the values for the phrase object and the words in quotes are values for the parsed object.
The SAPI SDK comes with a tool called the Speech Recognition Grammar Compiler for compiling and testing your grammars with different speech recognition engines. The compiler lives under the Tools menu after you install the SDK. After you speak a phrase and a defined time period has passed, the event shown in Figure 4 is fired. All of the Case options are based on the value of the parsed object that's captured after each voice command and corresponds to buttons on the form. The ctrlQuestion object is my rich text field. Normally, the user types their query here, but in this case they can be entered by voice. The ctrlSubmit_Click submits the ctrlQuestion.SelText to the English Query application and the results are immediately displayed by a DBGrid object. Programming for the Future I recently downloaded the Speech Control Panel from the Microsoft Agent Downloads Web site at http://msdn.microsoft.com/msagent/agentdl.asp. The Speech Control Panel enables you to list the compatible speech recognition and text-to-speech engines installed on your system, and to view and customize their settings. When you install the file, it adds a speech icon to your Control Panel. Note that this application will only install on Windows® 95, Windows 98, and Windows NT® 4.0-based systems. I've suggested to Microsoft that the program allow the user to pick a default speech recognition engine and TTS engine through this panel. If you could then programmatically pull a user's choice out of their registry with SAPI, you could code it once and never change it. This would give users more flexibility in their use of speech-enabled software. For example, a user might already be using a product from, say, Dragon for their speech recognition engine. If they wanted to continue using that engine and their training profiles, SAPI could allow that if it were defined as the default speech recognition engine in the registry. Summary The combination of speech recognition and English Query represents a powerful way for a user to access information in a SQL Server database very quickly. For users who work in an environment where speed and ease of access are critical, it holds enormous promise for future applications. As hardware continues to become more powerful and cheaper, speech recognition should continue to become more accurate and useful to increasingly wider audiences. See the sidebar "English Query Semantic Modeling Format". |
|
|
|
http://msdn.microsoft.com/library/psdk/englishquery/eq02_1.htm
|
From the June 1999 issue of Microsoft Internet Developer.
