Using VB and ADO, you can create a flexible data warehousing utility that fits your needs.
by Hao Li
Reprinted with permission from Visual Basic Programmer's Journal, August 1999, Volume 9, Issue 8, Copyright 1999, Fawcette Technical Publications, Palo Alto, CA, USA. To subscribe, call 1-800-848-5523, 650-833-7100, visit www.vbpj.com, or visit The Development Exchange.
Data warehouse developers face a common problem: They need to consolidate data, yet they lack flexible tools to achieve this. W. H. Inmon, a data warehouse expert, estimates that 80 percent of the efforts of building a data warehouse involve extracting, cleaning, and loading the data into a data warehouse. In fact, large enterprises often need to consolidate a large volume of data from many varied sources, but current data-consolidation tools often lack the necessary programmability and flexibility.
|
In this article, I'll show you how to write a utility that's more flexible than DTS, and you won't need to install SQL Server 7. You'll design and implement a Component Object Model (COM) object—DataPump—using VB5 or VB6 and ActiveX Data Objects (ADO) 2.0 (download this utility here). Like a DTS object, the COM object can transfer data between any OLE DB or ODBC data source. To match the DTS fast-load option, you'll add an optional bulk-copy transfer mode for loading data to SQL Server. You'll also implement a simple replacement mechanism to handle parameterized jobs. Finally, you'll design and implement an object designer with an intuitive graphical user interface (GUI) for interactive job testing, job maintenance, and automatic code generation of batch jobs that can be scheduled.
The object and its designer make a useful utility package you and your fellow developers can use for your data warehouse projects. During the process, you'll learn about general object design and implementation, as well as practical ADO 2.0 programming. I've used such a utility extensively in a large data warehousing project with multiple AS/400s as the source and SQL Server 6.5 as the destination, and found it flexible and easy to customize (see Table 1 for all the properties, methods, and events for the object).
Design the Job Table
The DataPump object is
table-driven: It encodes any job definition as a table entry. This
design offers four advantages. First, it means fewer properties for
the object itself, making the object simpler to use. Second, you
don't need to recompile the program when you change the job
definition (as is often the case from development to deployment).
Third, you don't need to write any persistence code for the object.
Finally, by using a tool such as Microsoft Access or Crystal
Reports, you can easily produce a report on all the jobs related to
a data warehouse development effort—a nice documentation feature
that many existing tools (including DTS) don't offer yet.
To define the job table, you need to first define what a job is in this context. You define a job as a unit of work involved for an entire data warehouse load. Typically, it's the loading of one warehouse table. Then, subdivide the job into three distinct stages:
JOB = preload + load + postload For example, you could define preload as truncating on the destination table, and define postload as deleting the old data from the last load and inserting the new data from the new load. However, you don't have to define all three parts of a job. For instance, you can define a job that contains only a series of drop or add index statements with no date transfer. It's up to the controller program to coordinate the execution of all your jobs. This design makes the job definition less granular, yet flexible enough to account for all possibilities (see the field definition for the job table in Table 2). To accomplish the same thing in DTS, you'd have to create at least three tasks in a DTS package: two Execute SQL tasks, one DataPump task, and a dependency relationship between the tasks. Even with the help of the friendly GUI, this creation process is tedious in the DTS Designer. Instead, to create a job using this design, you simply need to add one entry in the job table. Because this three-stage configuration is typical for data warehousing activity, this structure cuts design time significantly.
Code Efficiently With SQL Action Queries
From the
example in Table 2, you can see that both the source and destination
have the necessary connection information and SQL select strings.
The preload and postload might contain multiple SQL action queries,
as well as the special keywords shell and shellwait for spawning
external programs (shell returns immediately after launching the
external program; shellwait waits for the end of the external
program, then returns). You can easily express most preload and
postload activities in SQL action queries. Use action queries or
write stored procedures wherever possible, because they're usually
the most efficient way to express activities.
When you have more complex data cleansing requirements that you can't fulfill using simple action queries, you can write an independent VB program and use shellwait to link between your data load and post processing. You can also combine SQL action queries with shellwait statements. When you have multiple statements, use the go keyword to break them up. The object can then parse the statements into individual commands. (DTS provides an Execute SQL task and an Execute Process task to get the same effect. However, you must define their orders through workflow definitions.)
Our job table, called the "DataPump repository," doesn't have to reside on SQL Server. For example, you can easily implement this table in an Access database. Simply change the SQL Server data type to a corresponding Access data type (the download package contains a sample Access repository, repository.mdb, for you to use).
You define two properties for the object, sRepositoryConnectionString and sJobTableName, that the controlling program can use to inform the object where the repository resides. sRepositoryConnectionString, a standard ADO or ODBC connection string, is required. This connection string conveniently combines several connection-related values (such as server name, provider name, driver name, database name, user ID, and password) into one property that otherwise would require many properties to define. sJobTableName is simply the name of your job table. You can set a default value tJobInfo for sJobTableName. However, the controlling program might choose to use other names when there are more versions of the same table.
For example, you might have different versions of the job table, each supporting one stage of your data warehouse effort: development, preproduction, or production. You can switch easily to any version by setting this property to the right job table in the controlling program. To get all job-related information from your object, write code using the ADO Connection object and Recordset object to connect to the repository using these two properties, and retrieve data from the job table.
Use Record-Level Data Transfer Mode
Now that you've
nailed down the job table definition, you can start implementing the
actual data transfer routines for the object. Implement the routines
as LoadTable, the main method for the DataPump. LoadTable uses ADO
extensively, because ADO, as part of the Microsoft Universal Data
Access (UDA) initiative, enables you to connect to a wide range of
data sources. Specifically, this method connects to the job table,
loads the job definition information into memory, executes the
preload, does the data transfer, and finally executes the postload
(see Listing 1 for the
record-level data transfer code).
As shown in Listing 1, you use the adForwardOnly cursor type to create a recordset from the source. Significantly faster than other cursor types, adForwardOnly is the fastest cursor type to get read-only data. Then use the ADO GetRows method to read the data from the recordset into an array instead of looping through the recordset directly. The GetRows method is the best one to use, because getting individual data values from a recordset fields collection is much slower than getting the values from an array. Because you probably deal with tables containing many fields, the data retrieval time saved can be significant. I find this method efficient; try using it whenever you're dealing with a large volume of data.
One caveat: ADO 2.0 has a Microsoft-confirmed bug. Whenever you fetch more than 100 rows, the next fetch skips one record. To avoid this problem, use the latest version, ADO 2.1, or the service pack for ADO 2.0. You can also make the per-fetch upper limit 100 when using 2.0. To control the size of the resulting array returned by the GetRows method, you can add a lNoOfRowsPerFetch property so the controlling program can change its default value to get optimal transfer speed. You might also want to add two other useful properties: lMaxRowsToLoad and lNoOfRowsLoaded (read-only). You can easily implement these properties by incrementing lNoOfRowsLoaded when writing each row from the array into the destination table, and comparing its value to lMaxRowsToLoad after each insert. If you set the lMaxRowsToLoad property, the controlling program can control how many records to load. This property helps you test the job execution against large data sets, yet this capability is missing in existing data warehousing tools, including DTS. The lNoOfRowsLoaded read-only property proves useful for logging and reporting.
While record-level data transfer mode works well for most dimension types of tables, speed is a big concern when transferring data for fact tables, because they often contain a large volume of data. Although I use the ADO GetRows method to read data in chunks, the inserts to the destination table still happen row by row, producing a bottleneck for the loading process. When the destination is SQL Server, you can use the native bulk copy programming (bcp) routines to speed up the inserts. This dramatically improves the object's job execution performance.
Cut Load Time With bcp
From my test on large tables, I
find that bcp cuts down the load time by a factor of three or more,
and proves to be the only mode that competes with other loading
utilities speed-wise when loading large tables. This mode is similar
to the fast-load option available in DTS, and the performance is
generally a little better than DTS when the destination is SQL
Server 6.5 (although SQL Server 7.0 has much better performance when
using fast load). When using DTS, you can use either an OLE DB or
ODBC driver when loading data to SQL Server 6.5. However, ODBC
drivers don't use the fast-load feature, making performance much
slower. To use an OLE DB driver, you must apply the instcat.sql
patch to SQL Server 6.5.
Add an optional argument, bBCP (defaults to False), to the LoadTable method to implement this transfer mode. When in this mode, this method first fetches the data and writes it to a temporary text file, inserting column and row delimiters. This step is similar to Listing 1 except for the last part, where you write the field values to a text file instead of directly inserting them into the destination table. After this step, the method bulk-copies the text file to the destination table.
You have three options for this last step, each calling for a different level of effort. Your first option, which requires the least programming effort, is to use the command-line bcp utility that comes with SQL Server. However, the external program can't communicate with your object when it's executing, and you lose the error-trapping capability. Because this option is simple, you still might want to implement it, and add error detection by checking the program's log file. To launch the program, you can't simply use the VB Shell function, because the Shell function is asynchronous. You need to know when the external program ends in order to start your postload routine, so you need a synchronized shell. You can find this synchronized-shell routine in the download package; use it to implement the shellwait command in the preload and postload steps.
Your second option: Use the DBLibrary APIs, which provide you with the best control. However, these C-style routines aren't easily programmable in VB. Third, you can use vbsql.ocx, a 32-bit ActiveX control that interfaces between VB and DBLibrary, to accomplish this task (see Listing A). I chose the last option because it gives me better control on the bcp step, offers better error trapping, and is simple to use.
To give the controlling program flexibility, add these properties to the object: sBCPColumnSeparator, sBCPOutFileName, sBCPErrorFileName, and bKeepBCPFile. You can use the sBCPColumnSeparator property when the default separator string exists in the data. Use the sBCPOutFileName and sBCPErrorFileName properties to alter the location of the text file and error file. The bKeepBCPFile property is a flag that indicates whether the object should keep the text file after bcp. By default, the object deletes the file when the transfer is successful, and keeps it when there is an error.
Support Parameterized Jobs
One flexible feature in the
DataPump object is its support of parameterized jobs. I find this
almost a requirement for any serious data warehousing development,
although many existing tools don't have this functionality. Without
it, you can easily end up with hundreds of jobs for your data
warehouse project. For example, my client needs consolidated data
from all its local ERP systems on AS/400s. The ERP system
establishes a library for each site and installs the same list of
tables in the library (you can think of each library as a database).
Using one job per table is impractical because the system has well
over 30 sites. By using a placeholder for the library name in the
SourceSelectSQL column in the job table and replacing it with the
actual value at run time, you can use the same job template to
retrieve a table for all sites, cutting the number of jobs needed
thirty-fold.
To implement this feature, you'll create a replacement mechanism using two new properties: vReplace and sReplaceSeparator. The first property is a string array (v for variant) that contains all the replacement strings. For example, [Server]?(local) and [Password]?madonna each combine the placeholder, the separator, and the actual value at run time. The default value for sReplaceSeparator is ?, but you can set it to other strings as needed. Once you put any placeholders such as [Server] or [Password] in your job definition, the job entry in the job table becomes a job template. You traverse the vReplace array and use a routine to do the actual string replacement (see Listing 2).
When you use this mechanism, you should always use consistent delimiting symbols in your entire project, such as square brackets for your placeholders, to easily distinguish job templates from normal jobs. Also, you might want to add some comments describing the placeholders you use in the job definition. This makes future reading of your job definitions much easier. (DTS doesn't offer a similar mechanism.) Developers consider the inability to pass parameters to a package a weakness. Although DTS offers global variables, you'd have to know the DTS objects intimately to be able to change properties such as connection strings and SQL strings dynamically for the DataPump task. For example, I found it hard to design a package to load a table from 30 sources without designing 30 DataPump tasks or designing 30 distinct packages.
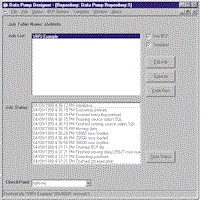 | |
| Figure
1 Develop Your Job Interactively. Click
here |
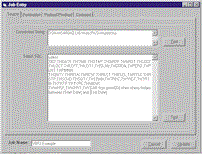 |
|
| Figure 2 Add or Edit a Job. Click here |
Now that you've created a generic data warehousing utility with an easy-to-use object designer, you might want to consider a few enhancements. The download package contains some features you can add, such as data validation and transformation. DTS provides ActiveX scripting functionality for this purpose, although many people avoid using it because of its slow performance. You can provide similar functionality by implementing an OnTransform event with the data array as one of its parameters. You raise this event for each data fetch, and the controlling program can apply the necessary validation and transformation in the event handler. This design is much faster than DTS, because DTS calls the ActiveX scripts every row and sometimes every column. Instead, you raise the event in every call to the ADO GetRows method.
Other things to add: debugging capability for your job templates
so you can see the actual values used at run time, and a checkpoint
feature so you can restart a failed job from a checkpoint rather
than the beginning. Once you're done, you'll find that your data
warehousing tasks are much easier to perform.
Hao Li lives in the Philadelphia region and is a
consultant at IMI Systems Inc., where he's working on a large data
warehousing project. A long-time VB programmer, he's a Microsoft
Certified Solutions Developer and holds a master's degree in
computer information systems. Reach him at hao_li@rohmhaas.com.