December 1999
![]()
| Design Your Application to Manage Performance Data Logs Using the PDH Library |
| For the most part, performance data log files include information that administrators of Windows NT-based systems can use to analyze the general health of a system. However, the developers I talk to also use performance data to reveal potential bugs in their applications. |
| This article assumes you're familiar with Performance Monitor and PDH.DLL |
Code for this article: PDH.exe (26KB)
|
Gary Peluso lives in Redmond, Washington, with his wife and two cats. When not supporting his customers, he enjoys working with wood and building furniture.
|
|
The Performance Data Helper (PDH) Library is a DLL that provides high-level functions for reading performance counters in Windows NT®. If you've never heard of PDH.DLL before, you should probably first look at Matt Pietrek's Under the Hood columns in the March and May 1998 issues of MSJ. Matt introduced PDH there, including discussions of queries, counters, counter paths, and other essentials that you need to understand when working with performance data logs. This article will focus more on introducing some new functions in PDH that manage (read and write) performance data log files. For the most part, performance data log files include information that administrators of Windows NT-based systems can use to analyze the general health of a system. However, the developers I talk to also use performance data to reveal potential application bugs. For example, you might use performance data to watch the Handle Count counter of your app's Process object to determine whether it's leaking handles. The ability to create and, better yet, read and analyze performance data logs further facilitates this problem solving. You do not need to go to the customer site to look at the problem—just tell them to create a log file. You could also create a custom tool that logs exactly what you want automatically, although the Performance Monitor in Windows NT does let you use settings files. PDH.DLL gives you these logging capabilities, but the real advantage comes when you can open and read a log file. Consider managing a large set of server machines. Say your budget for RAM does not allow upgrading all the machines. Perhaps you need to determine which five machines out of 300 have the greatest need for additional RAM. How would you go about doing this? A clever way would be to collect performance data from them for a 24-hour time frame, maybe over the span of a regular workday. But then what? Would you open each of the 300 log files in Performance Monitor? That could be a very time-consuming task. Instead, it would be helpful to have a tool that can scan through the set of log files and pinpoint which five machines produced the most page faults. PDH can be used to create such a tool. Many developers use the HKEY_PERFORMANCE_ DATA registry key and parse through the huge PERF_DATA_BLOCK that is returned to get the performance goodies. This is difficult and error-prone, so developers are turning to PDH.DLL because it makes collecting the performance data easier. Sure, there are more functions to call to actually get the data into your address space. But PDH makes it far easier to find the data you want and to perform calculations based on performance counter types. There is no need to implement complicated functions to calculate the raw data with PDH. Reading a performance data log from Performance Monitor on Windows NT without PDH is just about impossible. The only information you'll find in the Platform SDK is the perfmon source code, which is actually the source for the version of perfmon that shipped with Windows NT 3.5. I have never spoken to a developer who has reverse-engineered the performance data log. With PDH, there is no need to try. When I first investigated this new performance data log functionality in PDH, it was not as easy as you would think. At first glance, there are functions that seem intuitive to use, but they may not get you what you are looking for. I tried opening a perfmon-type log using PdhOpenLog—a fairly smart thing to try, right? It turns out that you simply cannot get to the logged performance data this way. To open a log file for reading, you use the less intuitive PdhOpenQuery. After looking at the examples, you'll see that reading data from a log file is not much different from querying live performance data. The new PDH log file format (which is the format for Windows® 2000) is much more space-efficient. If you have done much logging with the old Performance Monitor in Windows NT 4.0, you may have noticed it takes a lot of disk space to log only a few counters. With the new Performance Monitor in Windows 2000, you can actually log more performance data without taking up as much disk space. To find the Performance Monitor on Windows 2000, open Control Panel, then open the Administrative Tools folder. This folder contains the Performance icon, which you use to start the Performance Monitor. The Performance Monitor tool is actually a Microsoft® Management Console (MMC) snap-in. I'll first describe the performance data log by comparing it to a typical database table. Then I'll cover each type of log file operation (open, read, write, close, and so on) and which PDH functions are used for each. I'll also show how these functions fit together to perform three different tasks on log files: dumping a log file, writing current activity to a log file, and transferring data from one log file to another. Finally, I'll describe two working examples—including using PDH to dump a log file and move data from one log file to another—along with describing the little nuances I discovered along the way. Performance Data Log Files
I want to briefly describe what a performance data log looks like in terms of a database table, which should help you understand what some of the PDH functions are doing when working with logs. A typical database table contains records (rows) and fields (columns). In the same way, PDH logs are arranged with data samples (records) and counters (fields). Each record represents one sample of performance data. A log file can contain performance data for one or more counters; each counter has data in a field for each sample. The time stamp for each sample is also stored in the log file as a separate field. Figure 1 shows how a CSV (comma-separated value) log resembles the database table concept. |
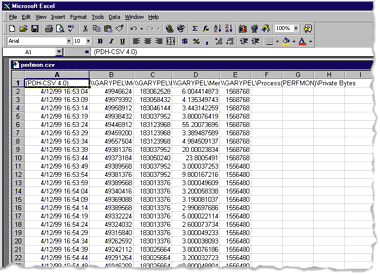 |
| Figure 1 A CSV-format Performance Data Log File |
|
There are four different performance data log file types that PDH supports (see Figure 2). One is the log file from the Performance Monitor in Windows NT 4.0. PDH refers to this type as PDH_LOG_
TYPE_PERFMON. Another is the PDH binary format, which is referred to as PDH_LOG_TYPE_BINARY. Two others are text-delimited files in CSV and TSV (tab-separated value) formats, which are referred to as PDH_LOG_ TYPE_CSV and PDH_LOG_ TYPE_TSV, respectively. Two additional log types, PDH_LOG_TYPE_TRACE_ KERNEL and PDH_LOG_ TYPE_TRACE_GENERIC, refer to logs created through Windows Management Interface (WMI) and the new Trace Event API. However, these topics are beyond the scope of this article. Since the beginning of Windows NT, Performance Monitor has had the ability to create and open performance data logs. PDH can only open and read perfmon-type log files; it cannot create or write them. You would not want to anyway since the perfmon log file format is quite inefficient. The perfmon-type log organizes the data with an entire PERF_DATA_BLOCK for each data sample, so at the minimum it stores entire performance data objects in the log file. For example, suppose you want to log the Private Bytes counter of your process's instance of the Process object. The Performance Monitor from Windows NT 4.0 would only allow you to specify the Process object, but not drill down to the Private Bytes counter and select your application instance. You would get the extra baggage of all of the other counters for all instances. For a more efficient log file format, consider the PDH_ LOG_TYPE_BINARY. On Windows 2000, the Performance Monitor tool logs performance data in a binary format to a file with a .BLG extension. The CSV and TSV formats are text files. For the most part they are very similar to files produced by spreadsheet or database report programs. The first column header is information that PDH uses to get the type (CSV or TSV) and version. The rest of the information is what you'd expect, including the first line being the header that describes the counter names and the subsequent lines holding the actual counter data. Opening a Log File
Two different functions exported by PDH will open a log file. PdhOpenLog includes parameters to specify the file name, access to open the file, and a flag. The flag will be set either by PDH to the type of PDH log that is being opened or to specify what type of log PDH is to create. For an application, PdhOpenLog is only used to create and write a performance data log, but not to read a log. The PdhReadRawLogRecord function will read the raw log records from an existing log, but the log records returned are in a structure with a proprietary format that is used internally by PDH. Reading a Log File
You could use PdhOpenLog and PdhReadRawLogRecord to read the log file, but the raw record format is proprietary. When you use PdhOpenQuery to open the log, the corresponding read function is PdhCollectQueryData. Think of the database table concept for a moment. Each time PdhCollectQueryData is called, an internal record pointer advances to the next record in the table. When PdhOpenQuery first opens a log file, the record pointer does not point to a data sample yet, so you must call PdhCollectQueryData at least once. When you call this function and there are no more records, PdhCollectQueryData fails. That's how you can determine when you have reached the end of the log file. There is no function that will reverse the record pointer. However, I cannot imagine a reason to do so. Viewing Log File Data
So far I've talked about opening and reading a log file. PdhCollectQueryData merely reads records in a log file. If you call PdhCollectQueryData repeatedly, you'll only be advancing a record pointer. To actually view the data you must call PdhGetRawCounterValue or PdhGetFormattedCounterValue. |
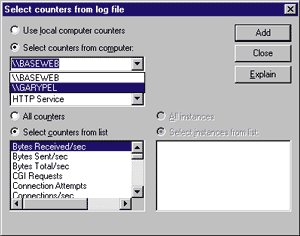 |
| Figure 3 Selecting Counters |
PDH has two functions that provide dialog boxes for the user: PdhBrowseCounters and PdhSelectDataSource. PdhBrowseCounters is the familiar dialog that allows users to select one or more counters. When used with an hQuery referring to a log file, the list of objects, counters, and instances shows only those found in the log file. Also, there may be counters from one or more machines in the log file; the PdhBrowseCounters function provides the objects associated with each machine. Figure 3 shows a dialog for browsing counters with counters included from two machines stored in the log file.
Manipulating Log Files
There are typically three management tasks you can accomplish with performance data logs using PDH. One is to read a log and use the data in some way, such as simply displaying it to the user in a graph or text output. The second task is to write current performance activity to a log file. The third task is to read a log file and transfer the information to another log file. The source and destination log files can have different formats. This may be useful to get some counter data from a perfmon-type log and transfer that data to a CSV-type log.
Lossing Current Activity
When writing a log file you will be using some of the new functions exported from PDH, specifically PdhOpenLog, PdhCloseLog, PdhUpdateLog, and PdhUpdateLogFileCatalog. These functions are not used alone, but augment the task of getting performance data from current activity.
Again, this is similar to monitoring live data. Aside from the new PDH functions, the differences here are that PdhUpdateLog replaces PdhCollectQueryData, and you don't need to call PdhGetRawCounterValue or PdhGetFormattedCounterValue. You specify the source of information for PdhUpdateLog when you pass the hQuery to PdhOpenLog. When creating a PDH binary format log, you can optionally call PdhUpdateLogFileCatalog. This will write an index portion, called a catalog, in the log file so that PDH can quickly reference the names of the objects, counters, and instances when the output log is subsequently read. This is important for the speed of PdhAddCounter and other PDH functions that look up the names of these items if there are many different counters in the log file. PdhUpdateLogFileCatalog can be called before or after you finish writing counter data to the log file. Note, however, that calling PdhUpdateLogFileCatalog is only valid when the hLog is opened with PdhOpenLog using the PDH_LOG_ TYPE_BINARY type. Transferring Log Data
Using what you know now about PDH, I bet you can figure how to take a log file produced by the Performance Monitor in Windows NT 4.0 and create a CSV file using text file output. There is an easy way to do this using the techniques I just described. A Couple of Caveats
Before I describe the samples included with this article, I want to discuss a couple of issues I ran into as I was developing sample code with this new PDH.DLL. I hope this will save you time when you begin using the new PDH. DumpLog
The DumpLog sample (partially shown in Figure 5) is actually fairly rudimentary, but can be extended easily to accomplish other tasks. The goal for this sample was to demonstrate how to read the log file data. CvtLog
Like the DumpLog sample, CvtLog (see Figure 6) is a simple Windows NT-based console application designed to illustrate the steps for using PDH to read a performance data log of one type and transfer the information to a performance log of another type. This utility can transfer information between logs of the same type so that the destination log file contains a subset of the counters from the first log. It is possible to implement a slight augmentation of this utility that allows you to give a subrange of data samples. In this case you would use PdhCollectQueryData to advance the record pointer to skip data samples, and then use PdhUpdateLog to transfer the next record to the destination performance log file. However, the CvtLog sample transfers all data samples of the selected counters. Wrap-up
I hope this article helped you grasp the purpose and functionality of performance data logs in PDH. Now you should be able to design your own utility or application that can manage performance data logs, including reading a log, writing live data to a log file, or transferring data from one log to another. While the logging service in Windows 2000 provides just about all you would need to schedule performance logging or to run a log without user interaction, the real power of sifting through the data comes from PDH and the tools you build with it. |
|
For related information see: Performance Monitoring at: http://msdn.microsoft.com/library/psdk/pdh/perfdata_0pgn.htm. Also check http://msdn.microsoft.com for daily updates on developer programs, resources and events. |
|
From the December 1999 issue of Microsoft Systems Journal.
|