Microsoft Corporation
1998
Summary: This article describes implementing the Microsoft SQL 7.0 Server Data Warehousing Framework. (25 printed pages)
Introduction
Microsoft Data Warehousing Framework
OLE DB: An Information Interchange Standard
Microsoft Repository: The Glue that Binds the Data Warehouse
Designing the Data Warehouse
The Data Warehouse Database
Importing, Exporting, and Transforming Data
Analyzing and Presenting the Data
System Administration
Conclusion
Making better business decisions quickly is the key to succeeding in today’s competitive marketplace. Organizations seeking to improve their decision-making ability can be overwhelmed by the sheer volume and complexity of data available from their varied operational and production systems. Making this data accessible is one of the most significant challenges for today’s information technology professionals.
In response to this challenge, many organizations choose to build a data warehouse to unlock the information in their operational systems. A data warehouse is an integrated store of information collected from other systems that becomes the foundation for decision support and data analysis. While there are many types of data warehouses, based on different design methodologies and philosophical approaches, they all have these common traits:
The data warehousing process is inherently complex and, as a result, is costly and time-consuming. Over the past several years, Microsoft has been working within the software industry to create a data warehousing platform that consists of both component technology and leading products that can be used to lower the costs and improve the effectiveness of data warehouse creation, administration, and usage. Microsoft has also been developing a number of products and facilities, such as Microsoft® SQL Server™ version 7.0, that are well suited to the data warehousing process. Coupled with third-party products that can be integrated using the Microsoft Data Warehousing Framework, customers have a large selection of interoperable, best-of-breed products from which to choose for their data warehousing needs.
SQL Server 7.0 will offer broad functionality in support of the data warehousing process. In conjunction with the Data Warehousing Framework, Microsoft plans to deliver a platform for data warehousing that helps reduce costs and complexity, and improves effectiveness of data warehousing efforts.
From the information technology perspective, data warehousing is aimed at the timely delivery of the right information to the right individuals in an organization. This is an ongoing process, not a one-time solution, and requires a different approach from that required in the development of transaction-oriented systems.
A data warehouse is a collection of data in support of management’s decision-making process that is subject-oriented, integrated, time-variant, and nonvolatile. The data warehouse is focused on the concept (for example, sales) rather than the process (for example, issuing invoices). It contains all the relevant information on a concept gathered from multiple processing systems. This information is collected and stored at regular intervals and is relatively stable.
A data warehouse integrates operational data by using consistent naming conventions, measurements, physical attributes, and semantics. The first steps in the physical design of the data warehouse are determining what subject areas should be included and developing a set of agreed-upon definitions. This requires interviewing users, analysts, and executives in order to understand and document the scope of the information requirements. The issues must be thoroughly understood before the logical process can be translated into a physical data warehouse.
Following the physical design, operational systems are put in place to populate the data warehouse. Because the operational systems and the data warehouse contain different representations of the data, populating the data warehouse requires transformations of the data: summarizing, translating, decoding, eliminating invalid data, and so on. These processes need to be automated so that they can be performed on an ongoing basis: extracting, transforming, and moving the source data as often as needed to meet the business requirements of the data warehouse.
In the operational system, data is current-valued and accurate as of the moment of access. For example, an order entry application always shows the current value of inventory on hand for each product. This value could differ between two queries issued just moments apart. In the data warehouse, data represents information gathered over a long period, and is accurate as of a particular point in time. In effect, the data warehouse contains a long series of snapshots about the key subject areas of the business.
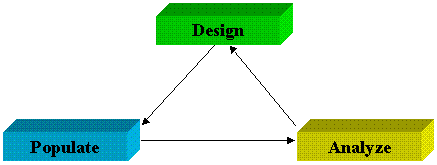
Finally, information is made available for browsing, analyzing, and reporting. Many tools assist in analysis, from simple report writers to advanced data miners. Ultimately, analysis drives the final iterations of the data warehousing process, causing revisions in the design of the data warehouse to accommodate new information, improve system performance, or allow new types of analysis. With these changes, the process restarts and continues throughout the life of the data warehouse.
Figure 1. Data warehousing process
Many methodologies have been proposed to simplify the information technology efforts required to support the data warehousing process on an ongoing basis. This has led to debates about the best architecture for delivering data warehouses in organizations.
Two basic types of data warehouse architecture exist: enterprise data warehouses and data marts.
The enterprise data warehouse contains enterprise-wide information integrated from multiple operational data sources for consolidated data analysis. Typically, it is composed of several subject areas, such as customers, products, and sales, and is used for both tactical and strategic decision making. The enterprise data warehouse contains both detailed point-in-time data and summarized information, and can range in size from 50 gigabytes (GB) to more than 1 terabyte. Enterprise data warehouses can be very expensive and time-consuming to build and manage. They are usually created from the top down by centralized information services organizations.
The data mart contains a subset of enterprise-wide data that is built for use by an individual department or division in an organization. Unlike the enterprise data warehouse, the data mart is usually built from the bottom up by departmental resources for a specific decision-support application or group of users. Data marts contain summarized and often detailed data about a subject area. The information in the data mart can be a subset of an enterprise data warehouse (dependent data mart) or can come directly from the operational data sources (independent data mart).
Enterprise data warehouses and data marts are constructed and maintained through the same iterative process described earlier. Furthermore, both approaches share a similar set of technological components.
A data warehouse always consists of a number of components, including:
Several years ago, Microsoft recognized the need for a set of technologies that would integrate these components. This led to the creation of the Microsoft Data Warehousing Framework, a roadmap not only for the development of Microsoft products such as SQL Server 7.0, but also for the technologies necessary to integrate products from other vendors.
The goal of the Microsoft Data Warehousing Framework is to simplify the design, implementation, and management of data warehousing solutions. This framework has been designed to provide:
The Data Warehousing Framework has been designed from the ground up to provide an open architecture that can be extended easily by Microsoft customers and third-party businesses using industry-standard technology. This allows organizations to choose best-of-breed components and still be assured of integration.
Ease of use is a compelling reason for customers and independent software vendors (ISVs) to choose the Data Warehousing Framework. Microsoft provides an object-oriented set of components designed to manage information in the distributed environment. Microsoft also provides both entry-level and best-of-breed products to address the many steps in the data warehousing process.
Building the data warehouse requires a set of components for describing the logical and physical design of the data sources and their destinations in the enterprise data warehouse or data mart.
To conform to definitions laid out during the design stage, operational data must pass through a cleansing and transformation stage before being placed in the enterprise data warehouse or data mart. This data staging process can be many levels deep, especially with enterprise data warehousing architectures, but is necessarily simplified in this illustration.
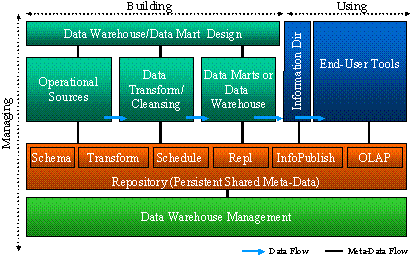
Figure 2. Data staging process
User tools, including desktop productivity products, specialized analysis products, and custom programs, are used to gain access to information in the data warehouse. Ideally, user access is through a directory facility that enables user searches for appropriate and relevant data to resolve questions and that provides a layer of security between the users and the data warehouse systems.
Finally, a variety of components can come into play for the management of the data warehousing environment, such as for scheduling repeated tasks and managing multiserver networks.
The Data Warehousing Framework describes the relationships between the various components used in the process of building, using, and managing a data warehouse. Two enabling technologies comprise the core Data Warehousing Framework: the integrated metadata repository and the data transport layer (OLE DB). These technologies make possible the interoperability of many products and components involved in data warehousing.
OLE DB provides for standardized, high-performance access to a wide variety of data and allows for integration of multiple data types.
Microsoft Repository provides an integrated metadata repository that is shared by the various components used in the data warehousing process. Shared metadata allows for the transparent integration of multiple products from a variety of vendors, without the need for specialized interfaces between each of the products.
Accessing the variety of possible data sources requires easy connectivity and interoperability between heterogeneous databases, and presents one of the most significant technical problems in data warehousing implementation. The Microsoft Data Warehousing Framework relies on the data transport standard that Microsoft has established, the Universal Data Access (UDA) architecture, and on OLE DB interfaces. UDA is a platform, application, and tools initiative that defines and delivers both standards and technologies. UDA is a key element in Microsoft’s foundation for application development: the Microsoft Windows® Distributed interNet Applications (DNA) architecture.
UDA provides high-performance access to a variety of data and information sources on multiple platforms and an easy-to-use programming interface that works with most tools and languages, leveraging the technical skills developers already possess. The technologies that support UDA allow organizations to create easy-to-maintain solutions and to use their choice of best-of-breed tools, applications, and data sources on the client, middle tier, or server.
One strength of the UDA architecture is that it is delivered through a common set of modern, object-oriented interfaces that are based on Component Object Model (COM). COM is a top choice of developers because it provides:
Because of the consistency and interoperability afforded through COM, the UDA architecture is open and works with virtually any tool or programming language. COM also allows UDA to provide a consistent data-access model at all tiers of the modern application architecture.
UDA exposes these COM-based interfaces optimized for both low-level and high-level application development:
OLE DB is Microsoft’s strategic system-level programming interface that manages data across the organization. OLE DB is an open specification designed to build on the success of Open Database Connectivity (ODBC) by providing an open standard for accessing all data types. While ODBC was created to access relational databases, OLE DB is designed to access both relational and nonrelational information sources, including:
OLE DB defines a collection of COM interfaces that encapsulates various database management system services. These interfaces enable the creation of software components that implement such services. OLE DB components consist of data providers (which contain and expose data), data consumers (which use data), and service components (which process and transport data).
OLE DB interfaces are designed to smoothly integrate components so that vendors can bring high-quality OLE DB components to the market quickly. In addition, OLE DB includes a bridge to ODBC that makes possible continued support for the broad range of ODBC relational database drivers available today.
Microsoft ADO is a strategic application-level programming interface to data and information. ADO provides consistent, high-performance access to data and supports a variety of development needs, including creating front-end database clients and middle-tier business objects, and using applications, tools, languages, or Internet browsers. ADO is designed to be a data interface for one-to-multitier, client/server, and Web-based solution development.
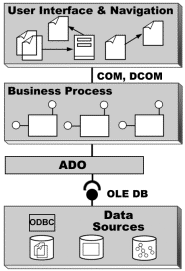
Figure 3. ADO on a data interface
ADO provides an easy-to-use application-level interface to OLE DB, which in turn provides underlying access to data. ADO is implemented with a small footprint, minimal network traffic in key scenarios, and minimal layers between the front end and data source. The result is a lightweight, high-performance interface. ADO is called using the COM automation interface, a familiar metaphor available from all leading rapid application development (RAD) environments, database tools, and languages on the market today. Because ADO was designed to combine the best features of, and eventually to replace, Remote Data Objects (RDO) and data access object (DAO), it uses similar conventions with simplified semantics, making it a natural next step for today’s developers.
One of the greatest implementation challenges is integrating all of the tools required to design, transform, store, and manage a data warehouse. The ability to share and reuse metadata reduces the cost and complexity of building, using, and managing data warehouses. Many data warehousing products include a proprietary metadata repository that cannot be used by any other components in the data warehouse. Each tool must be able to access, create, or enhance the metadata created by any other tool easily, while also extending the metadata model to meet the specific needs of the tool.
Consider the example of a data warehouse built with shared metadata. Metadata from operational systems is stored in the repository by design and data transformation tools. This physical and logical model is used by transformation products to extract, validate, and cleanse the data prior to loading it into the database. The database management system may be relational, multidimensional, or a combination of both. The data-access and data-analysis tools provide access to the information in the data warehouse. The information directory integrates the technical and business metadata, making it easy to find and launch existing queries, reports, and applications for the data warehouse.
The Microsoft Data Warehousing Framework is centered upon shared metadata in Microsoft Repository, which is a component of Microsoft SQL Server 7.0. Microsoft Repository is a database that stores descriptive information about software components and their relationships. It consists of an open information model (OIM) and a set of published COM interfaces.
OIMs are object models for specific types of information and are flexible enough to support new information types as well as extensible enough to fit the needs of specific users or vendors. Microsoft has developed OIMs in collaboration with the software industry for database schema, data transformations, and online analytical processing (OLAP). Future models may include replication, task scheduling, semantic models, and an information directory that combines business and technical metadata.
The Meta Data Coalition, an industry consortium of 53 vendors dedicated to fostering a standard means for vendors to exchange metadata, has announced support for Microsoft Repository, and Microsoft Repository OIMs have received broad third-party support. For more information, see the Meta Data Coalition home page at www.MDCinfo.com/.
The development phase of the data warehousing process often begins with the creation of a dimensional model that describes the important metrics and dimensions of the selected subject area based on user requirements. Unlike online transaction processing (OLTP) systems that organize data in a highly normalized manner, the data in the data warehouse is organized in a highly denormalized manner to improve query performance when stored in a relational database management system.
Relational databases often use star or snowflake schemas to provide the fastest possible response times to complex queries. Star schemas contain a denormalized central fact table for the subject area and multiple dimension tables for descriptive information about the subject’s dimensions. The fact table can contain many millions of rows. Commonly accessed information is often preaggregated and summarized to further improve performance.
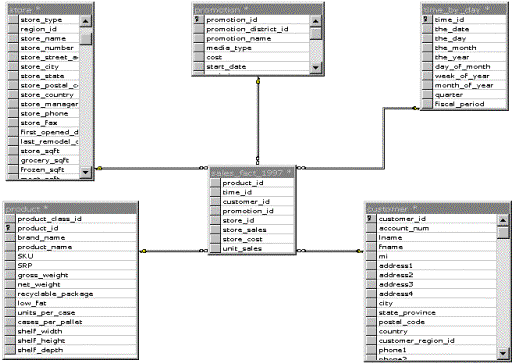
Figure 4. Star database schema
While the star schema is primarily considered a tool for the database administrator to increase performance and simplify data warehouse design, it also represents data warehouse information in a way that makes better sense to end users.
At the heart of the data warehouse is the database. It is crucial to build the data warehouse on a high-performance database engine that will meet both current and future needs of the organization. Relational database management systems (RDBMS) are the most common reservoirs for the large volumes of information stored in data warehouses. Increasingly, relational systems are being augmented with multidimensional OLAP (MOLAP) servers that provide enhanced navigational capabilities and increased performance for complex queries. Also important are facilities for replicating databases reliably from central data warehouses to dependent data marts, and ensuring consistency between mirrored data marts distributed geographically.
Microsoft SQL Server 7.0 contains a number of features that will make it an excellent RDBMS for enterprise data warehouses and data marts, including:
SQL Server 7.0 will be appropriate for nearly every data warehouse size and complexity. However, data warehouse implementations usually require more than one central database. In practice, organizations will implement decision support systems with additional analytical tools and with distributed information architectures. SQL Server 7.0 includes essential facilities for managing these additional tasks.
OLAP is an increasingly popular technology that can dramatically improve business analysis. Historically, OLAP has been characterized by expensive tools, difficult implementation, and inflexible deployment. Microsoft SQL Server OLAP Services is a new, fully featured OLAP capability that will be provided as a component of SQL Server 7.0. OLAP Services includes a middle-tier server that allows users to perform sophisticated analysis on large volumes of data with exceptional results. OLAP Services also includes a client-side cache and calculation engine called Microsoft PivotTable® Service, which helps improve performance and reduce network traffic. PivotTable Service allows users to conduct analyses while disconnected from the network.
OLAP Services is a middle-tier OLAP server that simplifies user navigation and helps improve performance for queries against information in the data warehouse.
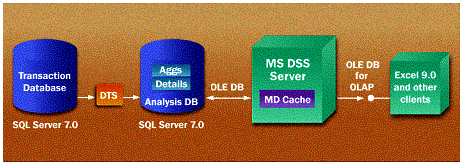
Figure 5. SQL Server OLAP services
OLAP is a key component of data warehousing, and OLAP Services provides essential functionality for a wide array of applications ranging from reporting to advanced decision support. The planned inclusion of OLAP functionality within SQL Server 7.0 will help make multidimensional analysis much more affordable and bring the benefits of OLAP to a wider audience, from smaller organizations to groups and individuals within larger corporations. Coupled with the wide variety of tools and applications supporting OLAP applications through Microsoft OLE DB for OLAP, OLAP Services will help increase the number of organizations that have access to sophisticated analytical tools and will help reduce the costs of data warehousing.
For more information about Microsoft SQL Server OLAP Services, see
Creating distributed, dependent data marts from a central data warehouse, or even duplicating the contents of an independent data mart, requires the ability to replicate information reliably. SQL Server 7.0 will include facilities for reliably distributing information from a central publishing data warehouse to multiple subscribing data marts. Information can be partitioned by time, geography, and so on as part of the replication process.
SQL Server 7.0 will provide a variety of replication technologies that can be tailored to your application’s specific requirements. Each replication technology produces different benefits and restrictions across these dimensions:
Requirements along and across these three dimensions vary from one distributed application to the next.
In most decision-support applications, data will not be updated at individual sites. Instead, information will be prepared at a central staging area and pushed to distributed database servers for remote access. For this reason, snapshot replication is often used to distribute data.
As its name implies, snapshot replication takes a picture, or snapshot, of the published data in the database at one moment in time. Instead of copying INSERT, UPDATE, and DELETE statements (characteristic of transactional replication) or data modifications (characteristic of merge replication), Subscribers are updated by a total refresh of the data set. Hence, snapshot replication sends all the data to the Subscriber instead of sending the changes only. If the amount of information being sent is extremely large, it can require substantial network resources to transmit. In deciding if snapshot replication is appropriate, you must balance the size of the entire data set against the volatility of the data.
Snapshot replication is the simplest type of replication, and it guarantees latent consistency between the Publisher and Subscriber. It also provides high autonomy if Subscribers do not update the data. Snapshot replication is a good solution for read-only Subscribers that do not require the most recent data and can be totally disconnected from the network when updates are not occurring. However, SQL Server will provide a full range of choices for replication depending on application requirements.
For more information about replication capabilities in SQL Server 7.0, see “Replication for Microsoft SQL Server Version 7.0.”
Before the data can be loaded into the data warehouse, it must first be transformed into an integrated and consistent format. A transformation is a sequence of procedural operations that is applied to the information in a data source before it can be stored in the specified destination. Microsoft Data Transformation Services (DTS) is a new facility in Microsoft SQL Server 7.0 that supports many types of transformations, such as simple column mappings, calculation of new values from one or more source fields, decomposition of a single field into multiple destination columns, and so on.
DTS was created to:
DTS allows the user to import, export, and transform data to and from multiple data sources using 100 percent OLE DB-based architecture. OLE DB data sources include not only database systems, but also desktop applications such as Microsoft Excel. Microsoft provides native OLE DB interfaces for SQL Server and for Oracle. In addition, Microsoft has developed an OLE DB wrapper that works in conjunction with existing ODBC drivers to provide access to other relational sources. Delimited and fixed-field text files are also supported natively.
DTS transformation definitions are stored in Microsoft Repository, SQL Server, or COM-structured storage files. Relational and nonrelational data sources are accessed using OLE DB. The data pump opens a rowset from the data source and pulls each row from the data source into the data pump. The data pump executes Microsoft ActiveX scripting functions (Microsoft Visual Basic®, Scripting Edition; JScript® development software; and PerlScript) to copy, validate, or transform data from the data source to the destination. Custom transform objects can be created for advanced data scrubbing. The new values for the destination are returned to the pump and sent to the destination by means of high-speed data transfers. Destinations can be OLE DB, ODBC, ASCII fixed field, ASCII delimited files, and HTML.
In DTS architecture, data is pulled from the data source with an OLE DB data pump, and optionally transformed before being sent to OLE DB destinations.
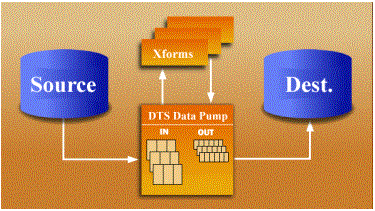
Figure 6. DTS architecture
Complex transformation and data validation logic can be implemented using ActiveX scripting. These scripts can invoke methods from any OLE object to modify or validate the value of a column. Advanced developers can create reusable COM transformation objects that provide advanced scrubbing capabilities. Custom tasks can be created that transfer files by means of FTP or launch external processes.
ISVs and consultants can create new data sources and destinations by providing OLE DB interfaces. The data pump will query the OLE DB interface for any provider to determine whether high-speed data loading is supported; if not, then standard loading mechanisms will be used.
Although standards like SQL-92 have improved interoperability between relational database engines, vendors still differentiate themselves in the marketplace by adding useful but proprietary extensions to SQL-92. SQL Server offers a simple programming language known as Transact-SQL that provides basic conditional processing and simple repetition control. Oracle Corporation, Informix Software, Inc., and other vendors offer similar SQL extensions.
The DTS Transformation Engine pass-through SQL architecture helps guarantee that the majority of the functionality of the source and destination are available to customers using the DTS Transformation Engine. This allows customers to leverage scripts and stored procedures that they have already developed and tested by simply invoking them from the DTS Transformation Engine. The pass-through architecture dramatically simplifies development and testing, since DTS does not modify or interpret the SQL statement being executed. Any statement that works through the native interface of the DBMS will work exactly the same way during a transformation.
DTS will record and document the lineage of each transformation in the repository so customers can know where their data came from. Data lineage can be tracked at both the table and row levels. This provides a complete audit trail for the information in the data warehouse. Data lineage is shared across vendor products. DTS packages and data lineage can be stored centrally in Microsoft Repository. This includes transformation definitions, Visual Basic scripting, Java scripting, and package execution history. Integration with Microsoft Repository allows third parties to build on the infrastructure provided by the DTS Transformation Engine. DTS packages can be scheduled for execution through an integrated calendar, and then executed interactively or in response to system events.
The DTS package is a complete description of all the work to be performed as part of the transformation process. Each package defines one or more tasks to be executed in a coordinated sequence. A DTS package can be created interactively using the graphical user interface or any language that supports OLE Automation. The DTS package can be stored in Microsoft Repository, in SQL Server, or as a COM-structured storage file. Once retrieved from the repository or structured storage file, the package can be executed in the same way as a DTS package that was created interactively.
A DTS package can contain multiple tasks, and each task can be as uninvolved as table-to-table mapping or as complex as invoking an external data cleansing process.
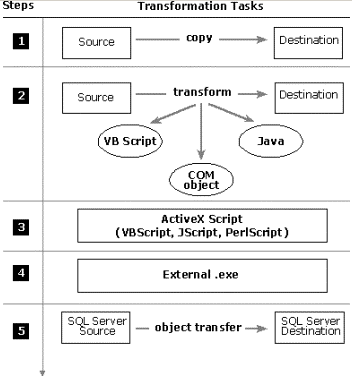
Figure 7. DTS package
A task defines a piece of work to be performed as part of the transformation process. A task can move and transform heterogeneous data from an OLE DB source to an OLE DB destination using the DTS Data Pump, and can execute ActiveX scripting or launch an external program. Tasks are executed by step objects.
Step objects coordinate the flow of control and execution of tasks in the DTS package. Some tasks must be executed in a certain sequence. For example, a database must be successfully created (Task A) before a table can be created (Task B). This is an example of a finish-start relationship between Task A and Task B; Task B, therefore, has a precedence constraint on Task A.
Each task is executed when all preceding constraints have been satisfied. Tasks can be executed conditionally based on run-time conditions. Multiple tasks can be executed in parallel to improve performance. For example, a package can load data simultaneously from Oracle and DB2 into separate tables. The step object also controls the priority of a task. The priority of a step determines the priority of the Win32® API thread running the task.
The DTS Data Pump is an OLE DB service provider that provides the infrastructure to import, export, and transform data between heterogeneous data stores. The OLE DB strategic data access interface provides access to the broadest possible range of relational and nonrelational data stores. The DTS Data Pump is a high-speed, in-process COM server that moves and transforms OLE DB rowsets.
A transformation is a set of procedural operations that must be applied to the source rowset before it can be stored in the desired destination. The DTS Data Pump provides an extensible, COM-based architecture that allows complex data validations and transformations as the data moves from the source to the destination. The DTS Data Pump makes the full power of ActiveX scripting available to the DTS package, allowing complex procedural logic to be expressed as simple, reusable ActiveX scripts. These scripts can validate, convert, or transform the column values using the scripting language of their choice as they move from the source, through DTS Data Pump, to the destination. New values can be calculated easily from one or more columns in the source rowset. Source columns also decompose a single field into multiple destination columns. ActiveX scripts can invoke and utilize the services of any COM object that supports automation.
DTS packages can be created using import/export wizards, the DTS Package Designer, or a COM interface. The import/export wizards provide the simplest mechanism for moving data into or out of a data warehouse, but the transformation complexity is limited by the wizards’ scope. For example, only single sources and single destinations are allowed in the wizard.
The DTS Package Designer exposes all the capabilities of DTS through an easy-to-use, visual interface. Within the DTS Package Designer, users can define precedence relationships, complex queries, flow of control, and access to multiple, heterogeneous sources.
The DTS Package Designer provides a graphical environment for describing data flow and package execution.
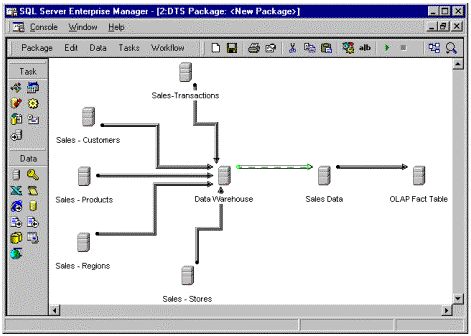
Figure 8. DTS package designer
Finally, applications can define and execute DTS package programming through a COM interface. This approach is primarily used by ISVs who want to utilize the features of DTS without requiring a user to define the packages separately.
Microsoft provides a number of mechanisms for querying information in the data warehouse. In the Microsoft Office suite of productivity tools, both Microsoft Access and Microsoft Excel offer facilities for query and analysis of information in a data warehouse. Included with Microsoft SQL Server 7.0 is a component called Microsoft English Query, which allows users to query the database using natural, English-language sentences. In addition, through the Data Warehousing Framework, many compatible products are available for sophisticated viewing and analysis of data.
Two of the most common tools used to access and manipulate data for decision support are Microsoft Access and Microsoft Excel. With the introduction of Microsoft Office 2000, users will have access to many more facilities for analyzing and presenting the information in their data warehouses.
Microsoft Excel 2000 will enable tabular and graphical representation of OLAP data sources through the OLE DB for OLAP interfaces. At the same time, the existing PivotTable dynamic views capability will be replaced with a more advanced OLAP facility based on the PivotTable Service component of Microsoft SQL Server OLAP Services.
Microsoft Access 2000 will provide transparent support for SQL Server databases in addition to the existing Access database facilities. For customers, these new capabilities will allow their familiar desktop tools to be used for increasingly sophisticated data analysis.
Microsoft Office 2000 will include a number of components for simplifying the construction of Web-based applications using prebuilt controls. These controls will provide access to relational databases and OLAP databases, enabling widespread viewing of information in the data warehouse.
English Query is a component of SQL Server 7.0 that will allow an application builder to create an application to the data warehouse that allows users to retrieve information from a SQL Server database using English rather than a formal query language like SQL. For example, you can ask, “How many widgets were sold in Washington last year?” instead of using these SQL statements:
SELECT sum(Orders.Quantity) from Orders, Parts
WHERE Orders.State=‘WA’
and Datepart(Orders.Purchase_Date,’Year’)=‘1996’
and Parts.PartName=‘widget’
and Orders.Part_ID=Parts.Part_ID
English Query accepts natural, English-language commands, statements, and questions as input and determines their meaning. It then writes and executes a database query in SQL and formats the answer. English Query also can request additional information from a user if a question cannot be interpreted.
English Query contains a deep knowledge of language syntax and usage, but the application developer must create a domain of information about the data being made available to the user. In English Query, a domain is the collection of all information that is known about the objects in the English Query application. This information includes the specified database objects (such as tables, fields, and joins), semantic objects (such as entities, the relationships between them, and additional dictionary entries), and global domain default options.
The first step to building an English Query application is to model the semantics of the data warehouse. The developer maps the English-language entities (nouns) and relationships (verbs, adjectives, traits, and subsets) to tables, fields, and joins in the database. This is done by using an authoring tool that allows for domain testing outside the application.
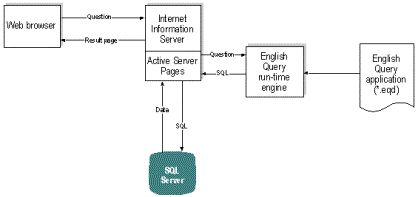
Figure 9. English Query
Once the domain is modeled sufficiently for user testing and access, the developer makes the English Query application accessible through a Visual Basic-based application or a Web-based implementation using Active Server Pages (ASPs). With the increase of intranet-based information delivery to data warehouses, English Query is an excellent tool for providing access without costly query tools and training.
At run time, a user of an English Query application connects to a Web page through Microsoft Internet Explorer software (or another Web browser) and enters a question. Microsoft Internet Explorer then passes the question to the Windows NT® Server’s built-in Web server, Internet Information Services (IIS), along with the URL of the ASP that executes the Visual Basic scripting.
The script passes the question to English Query for translation into an SQL statement. English Query uses domain knowledge about the target database (in the form of an English Query application) to parse the question and translate it into an SQL statement. The script then retrieves this SQL statement, executes it (using an ASP database control), formats the result as HTML, and returns the result page to the user.
English Query includes sample ASPs that can be used as delivered for rapid prototyping, or customized to fit the appearance and behavior of an existing Web application.
A fundamental philosophy of the Data Warehousing Framework is the openness of the solution to third-party components. Through the ODBC and OLE DB database interface standards, dozens of products can access and manipulate the information stored in SQL Server or another relational database. Likewise, the OLE DB for OLAP multidimensional database interface makes available the information in OLAP Services and other OLAP data stores. Because of these two access standards, organizations are able to select the most appropriate analytical tools for their needs. The reduced expenses for ISVs due to standardization will also mean that the costs of acquiring best-in-class products may diminish over time.
One of the most significant hidden costs of implementing a data warehouse is the ongoing system maintenance and administration. With conventional technology, specialized skills are typically required to manage the relational database, the OLAP server, and the design and transformation technology. This means that multiple individuals with specific training are often needed to perform integral, related tasks. The Microsoft Data Warehousing Framework provides an integrated management and administration layer that can be shared across components in the data warehousing process.
Microsoft provides a console for the Microsoft product lines that simplifies the transition from task to task, even between separate products. Microsoft Management Console (MMC) is extensible by customers, consultants, and ISVs, providing for a highly customized interface for specific environments. Applications are delivered as snap-ins to the console, and can be either a packaged user interface developed by an ISV or a customized interface developed separately, but accessing the capabilities of an underlying product such as SQL Server. Like much of the Microsoft BackOffice® family, SQL Server 7.0 is delivered as a snap-in to MMC.
MMC provides a consistent, familiar interface for accessing the capabilities of Microsoft server products. The MMC user interface is similar to the Windows Explorer environment, with a vertically split work area containing a console tree of categories and objects relevant to a particular server on the left side, and a details pane about a selected item on the right. Detailed information in the details pane can be displayed in a variety of ways, including as an HTML document.
MMC allows for more sophisticated tools to assist the novice or infrequent database administrator. One significant addition is taskpads, which group multifaceted activities such as building a database, establishing user security, and monitoring the SQL Server database. Taskpads combine tutorial information, guided activities, and wizards.
SQL Server 7.0 will contain more than 25 wizards designed to simplify frequent tasks, including:
Wizards help reduce the learning curve required for a database administrator to become productive with SQL Server. In the data warehousing environment, where database administrators are often supporting many steps of the process with multiple products, this can translate into savings of both time and money.
Because data warehousing applications are more iterative than OLTP systems, the database structures and schemas can change more often. Visual database diagrams provide physical data modeling tools for SQL Server database administrators, simplifying the definition and change cycles.
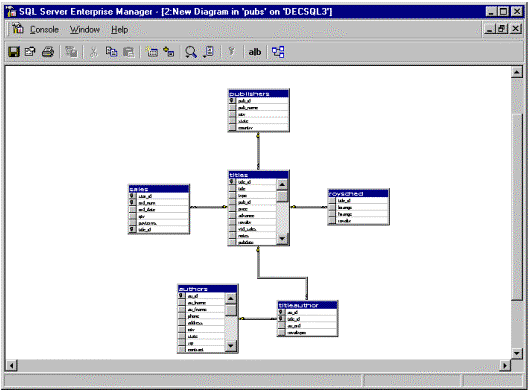
Figure 10. Visual database diagram
The visual database diagrams are stored on the database server using SQL Server 7.0 Enterprise Manager. Changes to either the database or the diagrams are reflected in the other.
A wizard is available that automates the selection and layout of tables in an existing database. However, database entities (tables and their relationships) can be defined entirely within the diagram tool. The visual database diagram shows tables and their relationships, and allows changes to the structure of individual tables and to the constraints linking the tables.
Proper tuning of a relational database requires knowledge of the way the database is used on a regular basis. Microsoft SQL Server 7.0 Profiler is a graphical tool that will allow system administrators to monitor engine events in SQL Server by capturing a continuous record of server activity in real time. SQL Server Profiler monitors events that occur in SQL Server, filters events based on user-specified criteria, and directs the trace output to the screen, a file, or a table. SQL Server Profiler then allows the database administrator to replay previously captured traces to test changes to database structures, to identify slow-performing queries, to troubleshoot problems, or to re-create past conditions.
Examples of engine events that can be monitored include:
Data from each event can be captured and saved to a file or SQL Server table for later analysis. Data from the engine events is collected by creating traces, which can contain information about the SQL statements and their results, the user and computer executing the statements, and the time the event started and ended.
Event data can be filtered so that only a subset of the event data is collected. This allows the database administrator to collect only the event data they are interested in. For example, only the events that affect a specific database or user can be collected; all others will be ignored. Similarly, data can be collected from only those queries that take longer than a specified time to execute.
SQL Server Profiler will provide a graphical user interface to a set of extended stored procedures, which you can use directly. Therefore, it will be possible to create your own application to monitor SQL Server that uses the SQL Server Profiler extended stored procedures.
Microsoft SQL Server 7.0 Query Analyzer will be an excellent tool for the ad hoc, interactive execution of Transact-SQL statements and scripts. Because users must understand Transact-SQL in order to use the Query Analyzer, this facility is primarily meant for database administrators and power users. Users can enter Transact-SQL statements in a full-text window, execute the statements, and view the results in a text window or tabular output. Users can also open a text file containing Transact-SQL statements, execute the statements, and view the results in the results window.
The Query Analyzer provides excellent tools for determining how SQL Server is interpreting and working with a Transact-SQL statement. A user can:
The Query Analyzer illustrates how complex queries are resolved. In the following example, portions of a query are parallelized for performance improvement.
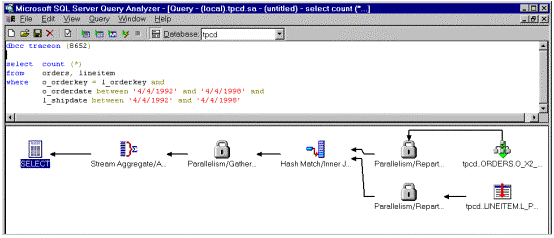
Figure 11. Query Analyzer
One of the most time-consuming and inexact processes in managing a relational database is the creation of indexes to optimize the performance of user queries. The SQL Server 7.0 Index Tuning Wizard is a new tool that will allow a database administrator to create and implement indexes without an expert understanding of the structure of the database, hardware platforms, and components, or of how end-user applications interact with the relational engine. The Index Tuning Wizard analyzes database workload and recommends an optimal index configuration for the SQL Server database.
The Index Tuning Wizard can:
The Index Tuning Wizard can analyze an SQL script or the output from a SQL Server Profiler trace and make recommendations regarding the effectiveness of the current indexes that are referenced in the trace file or SQL script. The recommendations consist of SQL statements that can be executed to drop existing indexes and create new, more-effective indexes. The recommendations suggested by the wizard can then be saved to an SQL script to be executed manually by the user at a later time, immediately implemented, or automatically scheduled for later implementation by creating a SQL Server job that executes the SQL script.
If an existing SQL script or trace is not available for the Index Tuning Wizard to analyze, the wizard can create one immediately or schedule one using SQL Server Profiler. Once the database administrator has determined that the trace file has captured a representative sample of the normal workload of the database being monitored, the wizard can analyze the captured data and recommend an index configuration to improve the database performance.
Data warehouse administrators can benefit significantly from automation of routine tasks, such as database backups. By using SQL Server Agent service, administrative tasks can be automated by establishing which tasks will occur regularly, and can be administered programmatically by defining a set of jobs and alerts. Automated administration can include single server or multiserver environments.
The key components of automated administration are jobs, operators, and alerts. Jobs define an administrative task once so it can be executed one or more times and monitored for success or failure each time it executes. Jobs can be executed on one local server or on multiple remote servers; executed according to one or more schedules; executed by one or more alerts; and made up of one or more job steps. Job steps can be executable programs, Windows NT commands, Transact-SQL statements, ActiveX scripting, or replication agents.
Operators are individuals responsible for the maintenance of one or more servers running SQL Server. In some enterprises, operator responsibilities are assigned to one individual. In larger enterprises with multiple servers, many individuals share operator responsibilities. Operators are notified though e-mail, pager, or network messaging.
Alerts are definitions that match one or more SQL Server events and a response, should those events occur. In general, database administrators cannot control the occurrence of events, but they can control the response to those events with alerts. Alerts can be defined to respond to SQL Server events by notifying one or more operators, by forwarding the event to another server, or by raising an error condition that is visible to other software tools.
Through a combination of notifications and actions that can be automated through the SQL Server Agent service, administrators can construct a robust, self-managing environment for much of their day-to-day operational tasks. This frees administrators to tend to more complex tasks that cannot be automated.
Through the technologies underlying the Microsoft Data Warehousing Framework and the significant advancements in Microsoft SQL Server 7.0, Microsoft is working to reduce the complexity, improve the integration, and lower the costs associated with data warehousing. Microsoft believes customers investing in data warehouse technology based on the Microsoft platform are creating applications with the best possible economic considerations, while maintaining the full scalability and reliability of their systems.
For more information about Microsoft SQL Server, see the SQL Server Web site at www.microsoft.com/sql/.
--------------------------------------------
The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Due to the nature of ongoing development work and because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication.
This document is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS DOCUMENT.
©1998 Microsoft Corporation. All rights reserved.
Microsoft, ActiveX, BackOffice, the BackOffice logo, JScript, PivotTable, Visual Basic, Win32, Windows, and Windows NT are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries.
Other trademarks and tradenames mentioned herein are the property of their respective owners.
Microsoft Part Number: 098-80704