Microsoft Corporation
December 1998
Summary: This article will address the strategies and techniques for transparently accessing data in a heterogeneous environment with Microsoft SQL Server 7.0. (27 printed pages)
Introduction
SQL Server 7.0 for the Heterogeneous Environment
SQL Server 7.0 in an Oracle Environment
Data Access
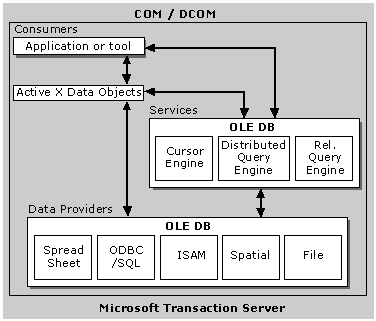
Microsoft Transaction Server
Conclusion
Appendix A: New Features of SQL Server 7.0
Appendix B: Comparison of SQL Server and Oracle Features
Enterprise business applications increasingly are being designed to run in a distributed computing environment. In addition to distributing applications across a network of workstations, servers, and legacy mainframe systems, organizations are distributing applications across geographic boundaries, time zones, and divisions. As organizations evolve and grow, they often acquire a heterogeneous collection of computers, networks, and databases.
As a result, these organizations need access to information and data from diverse enterprise business applications. For example, an organization may need to access the data residing on a UNIX workstation or an Oracle database in a way that is transparent to the end users. Transparent access is key to developing powerful distributed solutions that allow an organization to be responsive to the marketplace. Microsoft’s solution is the Universal Data Access (UDA) architecture:
Figure 1. UDA architecture
This document will address the strategies and techniques for transparently accessing data in a heterogeneous environment. Microsoft® SQL Server™ version 7.0 is based on the UDA architecture, which is implemented by means of OLE DB. OLE DB is an interface specification that provides for distributed data access without regard to the source or format of the data. Oracle, in contrast, takes a universal server approach, in which all data must exist in a single repository and must be accessed using a single access language.
The primary goal of SQL Server 7.0 is to take advantage of the capabilities offered through the UDA architecture, which allows data to exist in multiple formats and be accessed using many different methods. With the release of SQL Server 7.0, Microsoft provides not only a more powerful relational database management system (RDBMS), but also a mechanism for gathering disparate information stores and for presenting data in a consistent and useful manner without having to migrate or convert heterogeneous data to a single data store.
In addition to support for UDA, SQL Server 7.0 provides these new technologies for working with data in a heterogeneous environment:
All this functionality comes as part of SQL Server 7.0 at no additional cost. In addition, wizards make it easier for the user to build heterogeneous solutions using SQL Server.
The following scenarios will explore possible situations where SQL Server and Oracle would need to coexist.
In this scenario, a bookstore is using Oracle to track book orders and inventory. The bookstore is introducing an online ordering system through the Internet and is considering using the built-in Web server for Windows NT® Server, Internet Information Services (IIS) version 4.0, and SQL Server 7.0 to receive and process orders. Unless SQL Server is given the functionality to handle the orders and inventory, the two systems must coexist.
Online orders, once processed by SQL Server, are published to Oracle. This can be done without the use of any add-ons because the Oracle OLE DB driver provided with SQL Server 7.0 will support Oracle as a Subscriber in a SQL Server publication. Also, inventory can be directly accessed/modified in Oracle from SQL Server using linked remote servers and stored procedures. Reports can be built that access both the Oracle and SQL Server databases using the heterogeneous query support to be provided in SQL Server 7.0.
Given the proliferation of Windows NT and IIS and the ease of maintenance of Microsoft products, existing customers with Oracle databases could use a Microsoft Internet solution if they can easily access their legacy Oracle data.
In this scenario, a company has both Oracle and SQL Server running. Oracle was brought in with a package that the company purchased. SQL Server was implemented to solve a divisional computing need. In this scenario, the divisional system has grown in size and complexity and houses important data useful to both the division and the enterprise. The Oracle system could be modified to provide enterprise data for the growing departmental needs, or the departmental systems data could be migrated to a central data store. Either option represents a large undertaking that may result in little if any increased functionality.
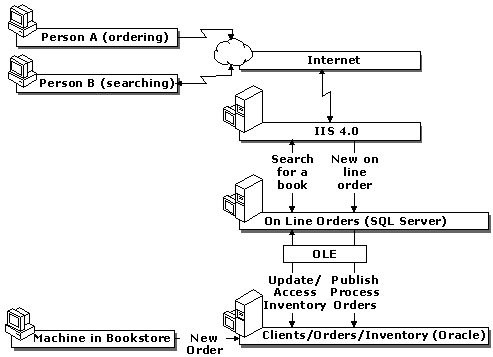
Figure 2. SQL Server and Oracle as peer databases
Another approach would be for the two systems to share data in a peer-to-peer relationship. For example, consider the case of a training company whose contact management, classes, students, and orders are stored in a SQL Server 7.0 database, while its financial data is stored in an Oracle database. When a new order is created in SQL Server, an invoice must be produced from the Oracle database.
By using Microsoft Transaction Server (MTS), part of Windows NT Server, the appropriate entries will be created in the Oracle database. If an order is canceled, an MTS transaction can update both the SQL Server and the Oracle databases.
A middle tier must be created to define the business rules and procedures, and care must be taken that all clients use the middle tier to perform business functions.
This peer approach leaves existing data in place, does not disrupt existing systems, and allows developers to focus their efforts on enhancing functionality rather than corralling data.
In responding to the demands of key distributed business applications, enterprise planners, administrators, and programmers must determine the best way to distribute large amounts of data so that it is in the right place at the right time. Microsoft SQL Server 7.0 provides several alternatives for processing distributed data in a heterogeneous environment:
By using SQL Server 7.0 , you can easily replicate data from one database to another throughout the enterprise. The SQL Server replication technology copies data, moves these copies to different locations, and synchronizes the data so that all copies have the same data values. Other options allow you to selectively designate data from your tables to be replicated from a source database to a destination database. Replication can also be implemented between databases on the same server or on different servers connected by local area networks (LANs), wide area networks (WANs), or the Internet.
SQL Server 7.0 will support:
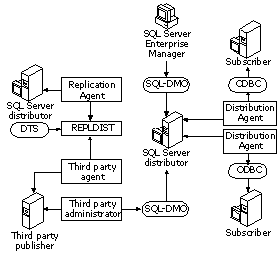
Figure 3. Data replication with programmatic interface
If a company is already using Oracle, there is often concern about using other databases because the information in the new database may not be accessible at the enterprise level. Using the previous example of a training company that has a central Oracle database system running Oracle financials, the environment is one in which the information technology (IT) staff is well-versed in Oracle and its development tools. When a department decided to purchase a SQL Server system, IT was concerned about how the SQL Server system would be supported and how it would integrate with the Oracle database.
In this case, all of the transactional inputs were maintained at the department level. However, some of the data in the departmental system was needed periodically for centralized reporting. Replication services were employed, allowing replication of the required data in the Oracle database, creating a planned, off-time window of network activity to move the data to the central database just prior to the scheduled report runs. This allowed the two systems to coexist, giving the department the system they required, while still satisfying the need of central IT for data access.
SQL Server 7.0 will provide a variety of replication options to chose from when considering replication between a variety of Publishers and Subscribers, including:
In addition, the overall replication architecture in SQL Server 7.0 has been enhanced and will include:
For more information about the replication capabilities in SQL Server 7.0, see Replication for Microsoft SQL Server Version 7.0.
DTS facilitates the import, export, and transformation of heterogeneous data. It supports transformations between source and target data using an OLE DB-based architecture. This allows you to move and transform data between the following data sources:
For example, consider a training company with four regional offices, each responsible for a predefined geographical region. The company is using a central SQL Server to store sales data. At the beginning of each quarter, each regional manager populates an Excel spreadsheet with sales targets for each salesperson. These spreadsheets are imported to the central database using the DTS Import Wizard. At the end of each quarter, the DTS Export Wizard is used to create a regional spreadsheet that contains target versus actual sales figures for each region.
DTS also can move data from a variety of data sources into data marts or data warehouses. Currently, data warehouse products are high-end, complex add-ons. As companies move toward more data warehousing and decision processing systems, the low cost and ease of configuration of SQL Server 7.0 will make it an attractive choice. For many, the fact that much of the legacy data to be analyzed may be housed in an Oracle system will focus their attention on finding the most cost-effective way to get at that data. With DTS, moving and massaging the data from Oracle to SQL Server is less complex and can be completely automated.
DTS introduces the concept of a package, which is a series of tasks that are performed as a part of a transformation. DTS has its own in-process component object model (COM) server engine that can be used independent of SQL Server and that supports scripting for each column using Visual Basic® and JScript® development software. Each transformation can include data quality checks and validation, aggregation, and duplicate elimination. You can also combine multiple columns into a single column, or build multiple rows from a single input.
Using the DTS Wizard, you can:
Once the package is executed, DTS checks to see if the destination table already exists, then gives you the option of dropping and recreating the destination table. If the DTS Wizard does not properly create the destination table, verify that the column mappings are correct, select a different data type mapping, or create the table manually and then copy the data.
Each database defines its own data types and column and object naming conventions. DTS attempts to define the best possible data-type matches between a source and a destination. However, you can override DTS mappings and specify a different destination data-type, size, precision, and scale properties in the Transform dialog box.
Each source and destination may have binary large object (BLOB) limitations. For example, if the destination is ODBC, then a destination table can contain only one BLOB column and it must have a unique index before data can be imported. For more information, see the OLE DB for ODBC driver documentation.
Note DTS functionality may be limited by the capabilities of specific database management system (DBMS) or OLE DB drivers.
DTS uses the source object’s name as a default. However, you can also add double quote marks (“ “) or square brackets ([ ])around multiword table and column names if this is supported by your DBMS.
DTS can function independent of SQL Server and can be used as a stand-alone tool to transfer data from Oracle to any other ODBC- or OLE DB-compliant database. Accordingly, DTS can extract data from operational databases for inclusion in a data warehouse or data mart for query and analysis.
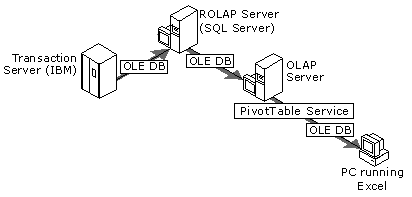
Figure 4. DTS and data warehousing
In the previous diagram, the transaction data resides on an IBM DB2 transaction server. A package is created using DTS to transfer and clean the data from the DB2 transaction server and to move it into the data warehouse or data mart. In this example, the relational database server is SQL Server 7.0, and the data warehouse uses OLAP Services to provide analytical capabilities. Client programs (such as Excel) access the OLAP Services server using the OLE DB for OLAP interface, which is exposed through a client-side component called Microsoft PivotTable® Service. Client programs using PivotTable Service can manipulate data in the OLAP server and even change individual cells.
SQL Server OLAP Services is a flexible, scalable OLAP solution, providing high-performance access to information in the data warehouse. OLAP Services supports all implementations of OLAP equally well: multidimensional OLAP (MOLAP), relational OLAP (ROLAP), and a hybrid (HOLAP). OLAP Services addresses the most significant challenges in scalability through partial preaggregation, smart client/server caching, virtual cubes, and partitioning.
DTS and OLAP Services offer an attractive and cost-effective solution. Data warehousing and OLAP solutions using DTS and OLAP Services are developed with point-and-click graphical tools that are tightly integrated and easy to use. Furthermore, because the PivotTable Service client is using OLE DB, the interface is more open to access by a variety of client applications.
Oracle does not support more than one BLOB data type per table. This prevents copying SQL Server tables that contain multiple text and image data types with modification. You may want to map one or more BLOBs to the varchar data type and allow truncation, or split a source table into multiple tables. Oracle returns numeric data types such as precision = 38 and scale = 0, even when there are digits to the right of the decimal point. If you copy this information, it will be truncated to integer values. If mapped to SQL Server, the precision is reduced to a maximum of 28 digits.
The Oracle ODBC driver does not work with DTS and is not supported by Microsoft. Use the Microsoft Oracle ODBC driver that comes with SQL Server. When exporting BLOB data to Oracle using ODBC, the destination table must have an existing unique primary key.
Distributed queries access not only data currently stored in SQL Server (homogeneous data), but also access data traditionally stored in a data store other than SQL Server (heterogeneous data). Distributed queries behave as if all data were stored in SQL Server. SQL Server 7.0 will support distributed queries by taking advantage of the UDA architecture (OLE DB) to access heterogeneous data sources, as illustrated in the following diagram.
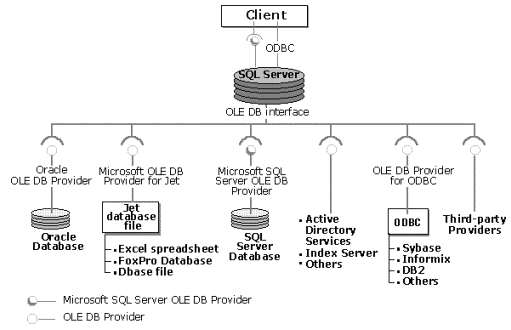
Figure 5. Accessing heterogeneous data sources with UDA
The advantages of heterogeneous distributed queries include:
Oracle supports heterogeneous distributed queries with SQL Server through the use of gateways. The SQL Server gateway is not included with Oracle; it must be purchased separately. SQL Server is more cost-effective because you get heterogeneous distributed queries out of the box with SQL Server 7.0. And because SQL Server 7.0 uses OLE DB, you can access a wider spectrum of heterogeneous relational databases and nonrelational data providers.
MS DTC was first released as part of SQL Server 6.5 and is included as a component in the MTS. MS DTC implements a transparent two-phase commit protocol that ensures that the transaction outcome (either commit or abort) is consistent across all resource managers involved in a transaction. The MS DTC ensures atomicity, regardless of failures, race conditions, or availability.
MS DTC supports resource managers that implement either the OLE transaction protocol or the X/Open XA specification for Distributed Transaction Processing.
Disparate databases will exist in the same environment for many reasons. Oracle provides several products that facilitate connectivity and coexistence with Microsoft SQL Server.
The Oracle transparent gateway allows Oracle client applications to access SQL Server. The gateway, in conjunction with an Oracle server, creates the appearance of all data residing on a local Oracle server, even though the data might be widely distributed. The Oracle transparent gateway provides:
The gateway accesses SQL Server data. Oracle client applications do not connect directly to the gateway, but connect indirectly to an Oracle server. The Oracle server communicates with the gateway by using SQL*Net. The gateway is started as a Windows NT-based service.
Client applications and Oracle tools, such as Oracle Forms, access the gateway through the Oracle server. When a client application queries a SQL Server database through the gateway, the query triggers the following sequence of events:
The Oracle server connects directly to the gateway, enabling heterogeneous queries against Oracle and SQL Server data. The Oracle server also post-processes Oracle SQL functions not supported by SQL Server. Definitions of database links for the SQL Server database are stored in the Oracle server.
SQL*Net version 2.0 provides client-to-server and server-to-server communication. This allows a client to communicate with the Oracle server, and the Oracle server to communicate with the gateway.
The Oracle server and the gateway work together to present the appearance to the client of a single Oracle database.
The Oracle server can accept an SQL statement that queries data stored in several different databases. The Oracle server passes the appropriate SQL statement directly to other Oracle databases and through gateways to other databases. The Oracle server then combines the results and returns them to the client, allowing a query to be processed that spans SQL Server and local and remote Oracle data.
Oracle offers a suite of additional products called Replication Services, which replicate SQL Server data into Oracle. By using Replication Services, either incremental row changes made to the SQL Server data or a full refresh can be propagated into Oracle.
Replicating data with Oracle transparent gateway provides both a synchronous and asynchronous means for maintaining Oracle and SQL Server copies of data. When updates are made to Oracle, synchronous copies of Oracle and SQL Server data can be maintained automatically by using Oracle database triggers. For gateways that provide two-phase commit functionality, an Oracle trigger can be developed to fire every time an update is made to the Oracle data. The two-phase commit feature supported by the transparent gateways ensures that transaction consistency is maintained.
Synchronous technology ensures application integrity, but requires communication between Oracle and SQL Server to complete a transaction. By ensuring that all updates are made before a transaction is complete, all copies are synchronized at a single point in time.
Replication in a mixed database environment using asynchronous technology allows applications to complete transactions without requiring access to the replicated copies of the data. Updates made to the source are committed, and updates to the replicated targets are deferred until a later time. If a system is not available, then the operation is delayed until the system becomes available. Eventually, all copies will be identical, but there may be differences in the various copies of the data at any single point in time.
Oracle transparent gateway also provides asynchronous capabilities for replicating data. Oracle transparent gateway uses the Oracle snapshot replication feature to automatically and asynchronously replicate SQL Server data into Oracle. Snapshot replication can be used with any Oracle transparent gateway, thereby providing a simple method for automatically replicating data from the data stores.
Oracle Objects for OLE provides Oracle data access without the use of native database APIs or the need for external data drivers. Using OLE2 technology, it provides a programmatic interface for Visual Basic, C++, and OLE 2.0 scripting applications to access Oracle data.
For Visual Basic or other 4GL development, Oracle Objects for OLE uses an OLE in-process server that supports Oracle functionality in Windows®-based applications.
Oracle Objects for OLE provides native access to Oracle so that you can obtain features such as shared SQL, PL/SQL, stored procedures, array processing, and server-side query parsing. Client-side features include bidirectional and scrollable cursors, find and move, customizable local data cache, commit/rollback, and row-level locking.
Microsoft has developed the UDA architecture based on COM, which is a binary standard for objects that defines how an object should present itself to the system after it has been compiled from its target language into machine code. Defining a standard allows objects to be compatible regardless of their source language. The UDA architecture allows applications to efficiently access data where it resides without replication, transformation, or conversion.
The strategy behind implementing distributed connectivity is to assure open, integrated, standards-based access to all types of data (SQL, non-SQL, and unstructured) across a wide variety of applications, from traditional client/server to the Web. Under UDA architecture, ActiveX Data Objects (ADO) is the high-level interface that most applications developers will use. OLE DB providers are the data-access engines or services, as well as the business logic components, that these applications can use in a highly interoperable, component-based environment.
The two fundamental components of UDA architecture are the ODBC standard and the OLE DB standard. ODBC unifies access to relational data from heterogeneous systems. Any application that supports ODBC can access information stored in any database that houses relational data, including Oracle. If all of the data were stored in relational databases, integration could be solved by using ODBC only. However, much data is nonrelational, or unstructured (for example, audio and video clips and e-mail messages). To simplify integration of unstructured data across the enterprise, Microsoft offers OLE DB.
OLE DB is a set of OLE interfaces that provides applications with uniform access to unstructured data regardless of type or location on the network. Developers can write applications that connect to any OLE DB provider, whether a file system, Oracle database, Microsoft Excel spreadsheet, or DB2 database, and can allow end users running Windows-based desktop applications to share and manipulate data stored there.
OLE DB is based on COM and provides:
Microsoft products provide several data access connectivity options that are illustrated in the following diagram and summarized in the following discussion.
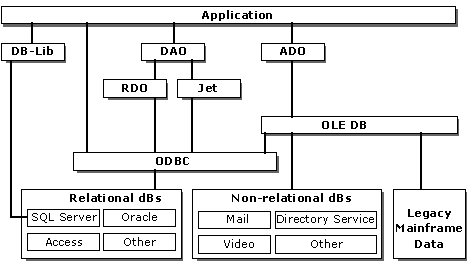
Figure 6. Connectivity options
ODBC, a C/C++ API, is designed to target different sources from the same source code by substituting different drivers. It provides access to server-specific extensions, and developers can write code to query which extensions are available.
Microsoft developed the ODBC interface as a means of providing applications with a single API through which to access data stored in a wide variety of DBMSs. Prior to ODBC, applications written to access data stored in a DBMS had to use the proprietary interface specific to that database. If application developers wanted to provide their users with heterogeneous data access, they needed to code to the interface of each data source. Applications written in this manner are difficult to code, maintain, and extend. ODBC was created to overcome these difficulties.
Data Access Object (DAO), designed for desktop access to data, is based on the Microsoft Jet database engine technology and uses Jet to gain access to other sources. Jet supports heterogeneous queries by using linked tables. This solution, however, is inefficient because the query processor does not attempt to optimize the query.
Remote Data Objects (RDO) is an object interface to ODBC that is similar to DAO in its programming techniques. RDO is a thin OLE layer on top of ODBC specifically optimized for SQL Server and Oracle databases. It provides a less complex programming model than ODBC, and it is tuned for SQL Server and Oracle access.
ODBCDirect integrates RDO methods directly into DAO, bypassing the Jet engine and thus improving performance. ODBCDirect provides similar features as RDO, but it uses the DAO object model. It offers an easy path to upscale Microsoft Access applications for SQL Server and Oracle.
OLE DB is the foundation of the UDA architecture. It is a specification for a set of COM-based data-access interfaces that encapsulate various data management services, allowing an application to access data without regard to its source. This abstraction of the data-access method provides a more flexible development environment and allows developers to focus their efforts on the application rather than the data. To become an OLE DB provider, implement OLE DB components from the OLE DB interfaces for the level of OLE DB support you want. This component-based model allows you to work with data sources in a unified manner and allows for future extensibility.
OLE DB components can be broken down into three categories: data providers, data consumers, and service components. A data provider owns the data it exposes to the outside world. While each OLE DB provider handles implementation details independently, all OLE DB providers expose their data in a tabular format through virtual tables.
A data consumer is any component, whether it be system or application code, that needs to access data from the OLE DB provider. Development tools, programming languages, and many sophisticated applications fit into this category.
A service component is a logical object that encapsulates a piece of DBMS functionality (such as query processors, cursor engines, or transaction managers). One of the design goals of OLE DB is to implement service components as stand-alone products that can be plugged in when needed.
ADO is an application-level programming interface to data and information. ADO supports a variety of development needs, including front-end database clients and middle-tier business objects using applications, tools, languages, or browsers. Remote Data Services (RDS), previously known as Active Data Connector, is a client-side component that interfaces with ADO and provides cursors, remote object invocation, and explicit and implicit remote recordset functionality such as fetch and update. OLE DB provides the low-level interface to data across the enterprise.
While ADO interfaces with OLE DB behind the scenes, applications can still access OLE DB directly. And ADO includes the ODBC components that have become the standard for working with relational databases. While the emphasis in the UDA architecture is on OLE DB native providers, ODBC remains a backward-compatible solution.
RDS is responsible for client-side services such as caching and updating data and binding data to controls. RDS controls use ADO as their data source, then the cursor engine in RDS communicates with ADO using OLE DB. RDS is a valuable component of the UDA architecture because it is responsible for improving client-side performance and flexibility in the Windows Distributed interNet Applications (DNA) architecture.
The Microsoft DB-Library, a C API, is a set of functions used to create client applications that interact with SQL Server. DB-Library offers the best performance because it is designed to communicate directly with SQL Server, bypassing ODBC and OLE DB. DB-Library is backward-compatible, but it is not the recommended way of connecting to SQL Server.
For more information about connectivity, see the Microsoft Interactive Developer article on Universal Data Access at www.microsoft.com/mind/0498/uda/uda.htm.
Several independent software vendors (ISVs) have incorporated OLE DB as the data-access technology in their products. The ISVs, in turn, are making commitments to market OLE DB technology. Intersolv and ISG are two examples of ISVs that provide OLE DB-based solutions and that produce OLE DB components such as providers and service providers. For more information about ISVs building OLE DB providers, see the OLE DB Web site at www.microsoft.com/data/oledb/default.htm.
Data-access middleware based on OLE DB provides a data access tier, which buffers an application from the native interface of the data source, the location of the data source, and the data model. To the client application, the middleware presents a transparent interface and data model, regardless of the type and number of data sources.
Data-access middleware processes application requests for data from a variety of database types. It packages the requests and transports them to a specific server system, which handles the request. After processing the request, the middleware returns the data to the application.
The following are examples of the current middleware and third-party products available for data access.
ISG Navigator is universal data access middleware that provides access and manipulation of data residing on Windows and non-Windows platforms (such as OpenVMS and UNIX). ISG Navigator is OLE DB-compliant, providing access to data sources such as hierarchical databases, indexed sequential files, simple files, personal databases, spreadsheets, and mail folders. By using ISG Navigator, nonrelational data can be accessed in the same way as relational data, that is, by using standard SQL.
ISG Navigator also allows heterogeneous queries, where data from different data sources, relational and nonrelational, can be integrated in a single query. ISG Navigator provides access to multiple data sources including SQL Server and Oracle.
While ISG Navigator is natively designed for OLE DB, it also provides an ODBC interface so that application programs accessing data through ODBC can readily benefit from ISG Navigator. In other words, ISG Navigator appears to the application as an ODBC data source but, unlike other ODCB data sources, ISG Navigator encapsulates as one numerous data sources on multiple platforms. The ISG Navigator OLE DB query processor for Windows NT, together with its ODBC interface, is included in the Microsoft OLE DB software development kit (SDK) as ODBC Bridge.
Intersolv provides full support for the OLE DB initiative through its full-function ODBC solutions. The Intersolv DataDirect ODBC Drivers version 3.0 contains optimizations for use in the OLE DB environment. Intersolv is developing a series of OLE DB service providers and data providers.
Sequiter Software is developing an OLE DB provider for Xbase databases such as dBASE and Microsoft FoxPro®. The Metawise Computing OLE DB providers, which will use the IBM data access Distributed Data Management (DDM) protocol, will work with AS/400 and virtual storage access method (VSAM) on Multiple Virtual Storage (MVS). These providers are included as part of the base system, with no host code required. MapInfo is releasing a client product with an OLE DB interface.
COM arose out of the need for an efficient method of interprocess communication. COM provides a group of conventions and supporting libraries that allow interaction between different pieces of software in a consistent, object-oriented way. COM objects can be written in many languages, including C++, Java, and Visual Basic, and they can be implemented in dynamic link libraries (DLLs) or in their own executables, running as distinct processes.
A client using a COM object need not be aware of either what language the object is written in or whether it is running in a DLL or a separate process. This functionality is achieved because COM defines an object concept known as an interface, which is a collection of methods that a client application can call. Interfaces are assembled and exposed to the system in the same way, regardless of the language used to create the object. This design provides a system whereby any COM-based component can communicate with any other existing or future COM-compliant component. These components can be created and accessed both on local and remote machines.
Distributed COM (DCOM) allows objects to be created and accessed on remote machines. DCOM provides a standard protocol that can sit on top of any standard networking protocol. If connectivity is established between machines at the network layer, DCOM-based communications can occur.
DCOM runs on top of these network protocols:
DCOM communications also work between dissimilar computer hardware platforms and operating systems. If DCOM has been implemented on both ends of a communication, it does not matter to either the client or the component which operating system is executing the other.
These platforms currently support DCOM, or will support it in the future:
Developing DCOM servers that are capable of processing a small number of clients is manageable. However, developing servers that are capable of processing thousands of transactions can be daunting. In an effort to facilitate the development of scalable DCOM servers, Microsoft has developed and released MTS, which is designed to insulate developers from complex system-oriented tasks, such as process and thread management, and from involvement in development-intensive activities, such as directory management. MTS handles all of the applications infrastructure, allowing developers to focus on business logic. Support is provided for accessing SQL Server and Oracle databases within MTS.
Microsoft Transaction Server (MTS) provides a run-time environment executing under Windows NT, which uses the COM interface mechanism to provide a flexible application development environment. MTS is suited for creating multitier client/server and Web-based applications. MTS is based on proven transaction processing methods, but its significance transcends the domain of transaction processing monitors. It defines a simple programming model and execution environment for distributed, component-based server applications.
MTS applications are composed of ActiveX components that provide the business-application function. These components are developed as if for a single user. By installing these components to execute within the MTS environment, the server application automatically scales to support many concurrent clients with high performance and reliability. MTS is specifically designed to allow server applications to scale over a wide range of users, from single-user systems to high-volume Internet servers. MTS provides the robustness and integrity traditionally associated with high-end transaction processing systems.
Servers require a sophisticated infrastructure. Building a network application server from scratch is a complex task. Implementing the business function is a small fraction of the work. In fact, most of the work involves building a sophisticated infrastructure to attain acceptable levels of performance and scale.
Application server developers usually must develop much of the infrastructure themselves. For example, even with the rich services provided by remote procedure call (RPC) systems, developers must:
MTS provides the application-server infrastructure that satisfies these requirements, allowing the developer to focus on creating the business logic.
It is critical that business systems accurately maintain the state of the business. For example, an online bookstore must reliably track orders. If it does not do this, revenue and customers can be lost.
Maintaining the integrity of business systems has never been easy. While computers are becoming increasingly reliable, systems are becoming increasingly unreliable. Failures are common with systems that are composed of multiple desktop machines connected through intranets and the Internet to multiple server machines.
The problem is compounded by the demand for distributed applications. Business transactions increasingly involve multiple servers. Credit must be verified, inventory must be shipped and managed, and customers must be billed. As a result, updates must occur in multiple databases on multiple servers. Developers of distributed applications must anticipate that some parts of the application may continue to run even after other parts have failed. These failure scenarios are orders of magnitude more complicated than those of monolithic applications, which fail as a whole. Business applications are frequently required to coordinate multiple pieces of work as part of a single transaction. Coordinating the work so that it all happens, or none of it happens, is difficult without system support. By using multiple components, which hide their implementations by design, problems are compounded.
Applications must provide consistent behavior when multiple clients access a component. Concurrent orders of the same item should not result in attempting to send a single item to two customers. Unless the application is properly written, race conditions will eventually cause inconsistencies. These problems are difficult and expensive to resolve, and are more likely to occur as volume and concurrency increase. Again, multiple components compound the problem.
MTS integrates transactions with component-based programming so that you can develop robust, distributed, component-based applications.
Because Oracle is XA-compliant and supports the Microsoft Oracle ODBC driver, Oracle databases can participate in MTS transactions. Oracle 7.3.3 is the first release of Oracle that supports MTS transactions. MTS also works with Oracle 8.0, but you must access Oracle 8.0 using the Oracle 7.3.3 client. MTS does not currently support Oracle 8.0 clients. It does work with Oracle Parallel Server.
The following table outlines the data access methods that work with Oracle.
Table 1. Data access methods that work with Oracle
| Data Access Method | Comments |
| ADO | Provides an object-oriented programming interface for accessing OLE DB data sources.
ADO permits a collection of records to be passed between clients and servers in the form of a recordset. A recordset can be used to pass a query result from the server to the client, and to pass updated records from the client to the server. |
| Java Database Connectivity (JDBC) | Allows Java components to invoke ODBC databases. |
| OLE DB | Provides a standard interface to any tabular data source.
ADO/OLE DB currently only supports transactions through the ODBC to OLE DB provider. The Microsoft OLE DB Provider for Oracle will support transactions when it becomes available. You cannot call OLE DB interfaces directly from Visual Basic because OLE DB is a pointer-based interface. A Visual Basic-based client can access an OLE DB data source through ADO. |
| ODBC | Provides a standard interface to relational data sources. |
| RDO | Provides an object-oriented programming interface for accessing ODBC data sources. |
Many corporations increasingly are finding themselves operating in a distributed computing environment. Through a variety of factors, including growth, acquisition, and management, these corporations find useful enterprise data in a variety of formats and data stores. The ability to effectively extract and analyze useful information from these diverse data stores is the key to success.
Microsoft SQL Server 7.0, with its UDA architecture, enhanced database architecture, and built-in analysis tools, will provide high-level integration of enterprise data and the tools to manage that information effectively. This will allow the information manager to focus on using the enterprise data rather than on trying to collect it in a single data store, which should prove attractive for any enterprise operating in a heterogeneous data environment.
With SQL Server 7.0, Microsoft has created an RDBMS system that integrates well in a heterogeneous database environment, using OLE DB to access data and to replicate data to and from various sources, and using DTS services for importing, exporting, and data cleaning. The new administration user interface, MMC, includes more than 25 wizards that simplify the day-to-day administrative operations.
Finally, SQL Server 7.0 will include support for all forms of OLAP analysis. SQL Server 7.0 will offer comprehensive support for use in a heterogeneous environment without additional cost and with a less complex and more consistent user interface. Oracle offers heterogeneous support and MOLAP support, but only as separate products.
SQL Server 7.0 will offer many access methods, making it more accessible and easier to integrate in a heterogeneous environment. The SQL Server 7.0 security system will integrate well in Windows NT-based networks and also is less complicated to maintain. Finally, the SQL Server 7.0 administration utility and the self-tuning SQL Server engine will make administration less complex, thus reducing the cost of ownership for SQL Server.
This appendix provides a summary of the new features to be found in Microsoft SQL Server 7.0 database architecture.
One of the strengths of Microsoft SQL Server 7.0 is its universal accessiblity. The SQL Server database architecture has been refined to include a query processor that supports parallel execution, the ability to query both ODBC and OLE DB, and other enhancements such as increased size limits for pages, rows, and tables, and support for row-level locking.
The SQL Server 7.0 query processor will support large databases and complex queries by using hash join, merge join, and hash aggregation techniques. The query processor uses fast sampling to extract and regather statistics. It also supports parallel execution of a single query over multiple processors, which will allow SQL Server to perform query execution.
SQL Server 7.0 uses OLE DB technology to perform distributed queries to access data in multiple SQL Servers, heterogeneous databases, file systems, and other network sources.
SQL Server 7.0 has enhanced I/O capability in database page size. Page size will increase from 2 kilobytes (KB) to 8 KB, with a maximum of 8,060 bytes per row. Other enhancements will change the character data-type limit from 255 bytes to 8,000 bytes and the columns per table limit from 250 columns to 1,024 columns. These changes will allow SQL Server to handle increasingly larger databases.
SQL Server 7.0 can handle larger enterprise systems. SQL Server 6.5 was limited to around 100 gigabytes (GB) for high-availability online transaction processing (OLTP) applications. In contrast, SQL Server 7.0 will support terabyte-size applications, increasing previous capabilities by a factor of 10.
SQL Server 7.0 backup utilities will perform incremental backups, capturing only the pages that have changed since the last database backup.
SQL Server 7.0 backup restoration will automatically create the database and all necessary files, enhancing the restoration procedure. SQL Server 7.0 will support the Microsoft Tape Format so that backup files can be stored on the same media as other backup files.
SQL Server 7.0 will include an OLE DB driver for Oracle, which facilitates the migration and movement of data and tables to and from Oracle servers to SQL Server 7.0 servers. DTS is one method that can be implemented to migrate and transform data. Data also can be migrated from one Oracle table to another using SQL Server 7.0 and DTS. The OLE DB driver for Oracle provided with SQL Server 7.0 will allow an Oracle database to be a Subscriber in a SQL Server 7.0 Publisher without using a third-party product. In contrast, Oracle requires a SQL Server gateway in order for SQL Server to participate in Oracle replication.
SQL Server 6.5 could replicate to any ODBC-compliant database, while replication to SQL Server 6.5 from a non-SQL Server database required a custom solution. With SQL Server 7.0, replication APIs will be made public so that ISVs can implement bi-directional replication solutions.
The database size has expanded from 1 terabyte in SQL Server 6.5 to 1,048,516 terabytes in SQL Server 7.0. SQL Server 7.0 can shrink or grow databases automatically.
The SQL Server 7.0 Enterprise Manager will provide wizards for common tasks that database administrators perform, including creation of databases, tables, views, indices, jobs, alerts, and stored procedures. The Index Tuning Wizard examines a server activity capture file and then analyzes submitted queries against a database’s index configuration, suggesting new indexes. The Maintenance Plan Wizard schedules table reorganizations to add fill-factor space, updates statistics, checks table and index integrity, and runs backups.
SQL Server 7.0 will dynamically allocate memory and disk space based on system resources and current workload. Dynamically shrinking devices is a feature that helps optimize resource utilization. Disk devices have been modified to become operating system files, thus avoiding the overhead that SQL Server 6.5 imposed with database-specific devices.
This appendix compares and contrasts the features found in Microsoft SQL Server 7.0 and Oracle.
The SQL Server Enterprise Manager will be delivered as a plug-in to Microsoft Management Console (MMC), the standard user interface for all Microsoft BackOffice® family products. This provides consistency and usability with all other Microsoft server products.
SQL Server 7.0 will come with more than 25 wizards that significantly simplify system administration. In addition, there are more than 100 prewritten scripts that can be used to administer the database. Oracle does not offer either the wizards or the prewritten scripts. However, Oracle has many system tables that can provide the information required.
SQL Server 7.0 will use autotuning of parameters, thus reducing the number of parameters that the administrator needs to set to optimize the Server.
SQL Server 7.0 will handle memory management automatically. To increase the performance of an application in Oracle, the database administrator must alter the buffer cache and memory pool parameters in the INIT.ORA file. The amount of space allocated varies by system and is constrained by the amount of memory on the server and the resources required by the shared pool.
Oracle and SQL Server use standard SQL, with extensions provided by each database server. Oracle uses PL-SQL to extend its SQL usage with developers, and SQL Server uses Transact-SQL. Stored procedures can be used in both environments. However, Oracle is more limited in its capabilities than SQL Server.
Both SQL Server and Oracle come with a battery of utilities that allow developers to manipulate data within the database, as well as to import and export data. Users can take advantage of transactions, foreign key constraints, and triggers.
A difference between Oracle and SQL Server is that SQL Server works almost transparently with other development tools, and it can be accessed by either ODBC or OLE DB. Oracle works best with other Oracle products. To access an Oracle database using ODBC, the client machine must have SQL*Net installed.
Oracle and SQL Server use different backup and recovery terminology but the results are the same. All transactions can be logged, archived, and recovered as needed, and backups can be performed without degradation to server performance.
Although there are many similarities, the greatest difference is administration time. Oracle can require a longer continuous period of time to administer than SQL Server.
SQL Server does not hold to the conventions of schemas and instances; Oracle does. In SQL Server, each database is an autonomous application hosted within SQL Server. The database is a logical definition that associates the objects within the database, and then identifies the level of access granted to users and groups.
The defined structure for SQL Server and for the data systems it hosts is kept in a set of system tables that are roughly equivalent to data dictionaries in Oracle. The following diagram illustrates the SQL Server defined structure.
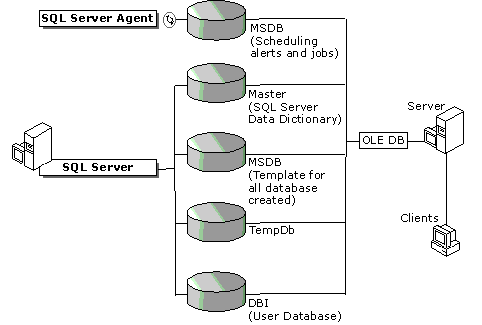
Figure 7. SQL Server defined structure
Master is the database that records all of the system-level information for the SQL Server system. It records all login accounts and all system configuration settings. Master records the existence of all other databases and the location of the primary files that contain the initialization information for SQL Server and user databases.
Model is the database used as the template for all the databases created on the system. When a CREATE DATABASE statement is issued, the first part of the database is created by copying in the context of the Model database.
The tempdb database is the temporary storage area used by all databases. This construct functions similar to how Oracle manages the system global area.
The MSDB database is used by the SQL Server Agent component for scheduling alerts and jobs.
In addition to the logical constructs maintained within SQL Server, there are a number of system services that are implemented. Unlike Oracle, which implements a set of system services for each instance, SQL Server initiates only one set of system services for all instances. The MSSQLServer service is the primary service responsible for SQL Server. The SQLServerAgent service is the service responsible for the SQL Server Agent component and manages alerts and scheduled jobs.
The SQL Server 7.0 security system architecture is based on users and groups of users, called security principals. The following diagram illustrates how Windows NT-based users and groups can map to security accounts in SQL Server, and how SQL Server can handle security accounts independent of Windows NT-based accounts.
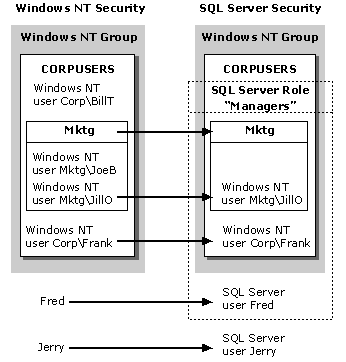
Figure 8. Windows NT-based users and groups mapped to security accounts in SQL Server
SQL Server provides security at the database level by using individual application security. SQL Server operates in one of two security (authentication) modes:
Mixed Mode allows users to connect using Windows NT Authentication or SQL Server Authentication. Users who connect through a Windows NT-based user account can make use of trusted connections in either Windows NT Authentication Mode or Mixed Mode. After successful connection to SQL Server, the security mechanism for both modes is the same.
Security systems based on SQL Server logins and passwords may be easier to manage than security systems based on Windows NT user and group accounts, especially for nonsensitive, noncritical databases and applications. For example, a single SQL Server login and password can be created for all users of an application, rather than creating all the necessary Windows NT user and group accounts. However, this eliminates the ability to track and control the activities of individual users.
The security environment in Windows NT and SQL Server is stored, managed, and enforced through a hierarchical system of users. To simplify the administration of many users, Windows NT and SQL Server use groups and roles. A group is an administrative unit within the Windows NT operating system that contains Windows NT users or other groups. A role is an administrative unit within SQL Server that contains SQL Server logins, Windows NT logins, groups, or other roles. Arranging users into groups and roles makes it easier to grant or deny permissions to many users at once. The security settings defined for a group are applied to all members of that group. When a group is a member of a higher-level group, all members of the group inherit the security settings of the higher-level group, in addition to the security settings defined for the group or the user accounts.
The organizational chart of a security system commonly corresponds to the organizational chart of a company, as demonstrated with the following diagram.
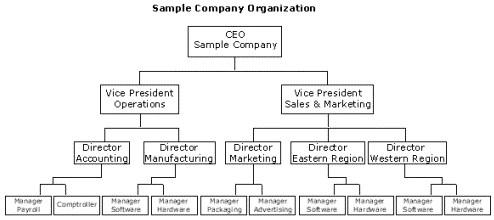
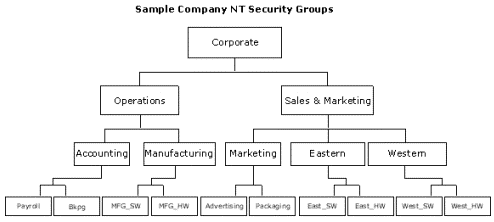
Figure 9. Correspondence between organizational chart of a security system and organizational chart of a company
The organizational chart for a company is a good model for the security system of a company, but there is one rule for a company’s organizational hierarchy that does not apply to the security model. Common business practice usually dictates that an individual reports to only one manager. This implies that an employee can fall under only one branch of the organizational hierarchy.
The needs of a database security system go beyond this limitation because employees commonly need to belong to security groups that do not fall within the strict organizational hierarchy of the company. Certain staff members, such as administrators, can exist in every branch of the company and require security permissions regardless of organizational position. To support this broader model, the Windows NT and SQL Server security system allows groups to be defined across the hierarchy. An administrative group can be created to contain administrative employees for every branch of the company, from corporate to payroll.
This hierarchical security system simplifies management of security settings, allowing security settings to be applied collectively to all group members, without having to be defined redundantly for each person. The hierarchical model also accommodates security settings applied to only one user.
--------------------------------------------
The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Due to the nature of ongoing development work and because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication.
This document is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS DOCUMENT.
©1998 Microsoft Corporation. All rights reserved.
Microsoft, ActiveX, BackOffice, the BackOffice logo, FoxPro, JScript, PivotTable, Visual Basic, Visual C++, Windows, and Windows NT are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries.
Other trademarks and tradenames mentioned herein are the property of their respective owners.
Microsoft Part Number: 098-80830